 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEC: Mixture of Expert Clusters
Jul 19, 2022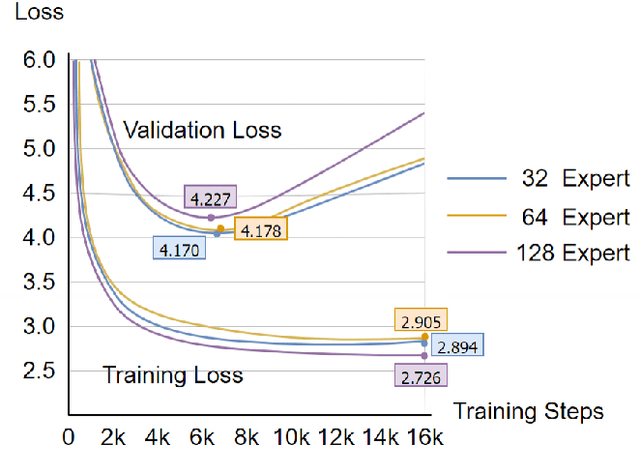

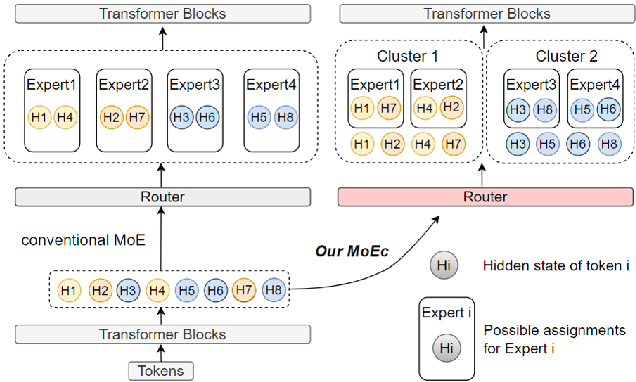

Sparsely Mixture of Experts (MoE) has received great interest due to its promising scaling capability with affordable computational overhead. MoE converts dense layers into sparse experts, and utilizes a gated routing network to make experts conditionally activated. However, as the number of experts grows, MoE with outrageous parameters suffers from overfitting and sparse data allocation. Such problems are especially severe on tasks with limited data, thus hindering the progress for MoE models to improve performance by scaling up. In this work, we propose Mixture of Expert Clusters - a general approach to enable expert layers to learn more diverse and appropriate knowledge by imposing variance-based constraints on the routing stage. We further propose a cluster-level expert dropout strategy specifically designed for the expert cluster structure. Our experiments reveal that MoEC could improve performance on machine translation and natural language understanding tasks, and raise the performance upper bound for scaling up experts under limited data. We also verify that MoEC plays a positive role in mitigating overfitting and sparse data allocation.
Variational Distillation for Multi-View Learning
Jun 20, 2022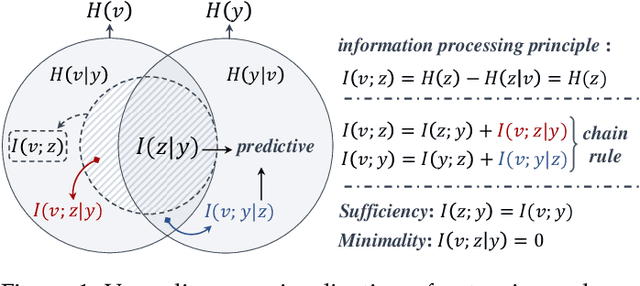
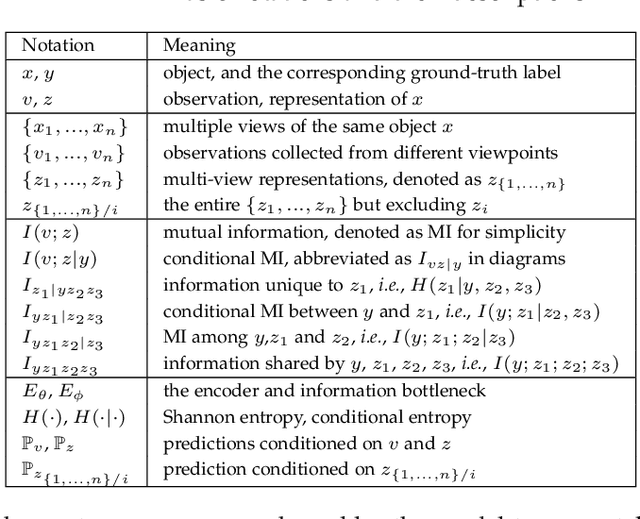
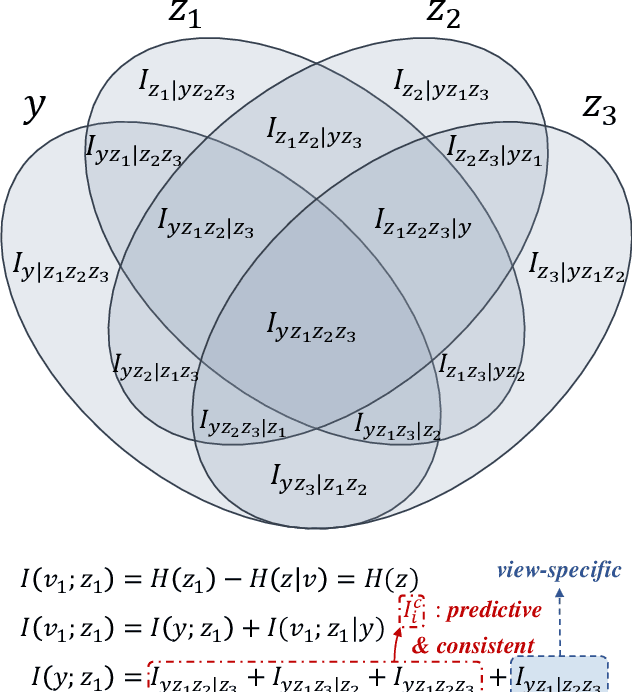
Information Bottleneck (IB) based multi-view learning provides an information theoretic principle for seeking shared information contained in heterogeneous data descriptions. However, its great success is generally attributed to estimate the multivariate mutual information which is intractable when the network becomes complicated. Moreover, the representation learning tradeoff, {\it i.e.}, prediction-compression and sufficiency-consistency tradeoff, makes the IB hard to satisfy both requirements simultaneously. In this paper, we design several variational information bottlenecks to exploit two key characteristics ({\it i.e.}, sufficiency and consistency) for multi-view representation learning. Specifically, we propose a Multi-View Variational Distillation (MV$^2$D) strategy to provide a scalable, flexible and analytical solution to fitting MI by giving arbitrary input of viewpoints but without explicitly estimating it. Under rigorously theoretical guarantee, our approach enables IB to grasp the intrinsic correlation between observations and semantic labels, producing predictive and compact representations naturally. Also, our information-theoretic constraint can effectively neutralize the sensitivity to heterogeneous data by eliminating both task-irrelevant and view-specific information, preventing both tradeoffs in multiple view cases. To verify our theoretically grounded strategies, we apply our approaches to various benchmarks under three different applications. Extensive experiments to quantitatively and qualitatively demonstrate the effectiveness of our approach against state-of-the-art methods.
The Spike Gating Flow: A Hierarchical Structure Based Spiking Neural Network for Online Gesture Recognition
Jun 07, 2022
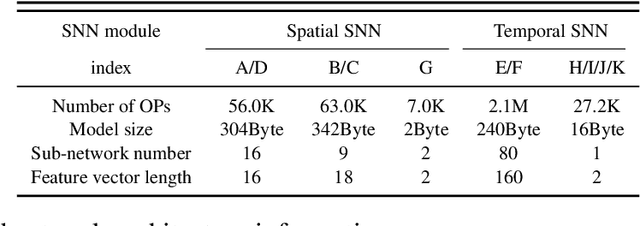
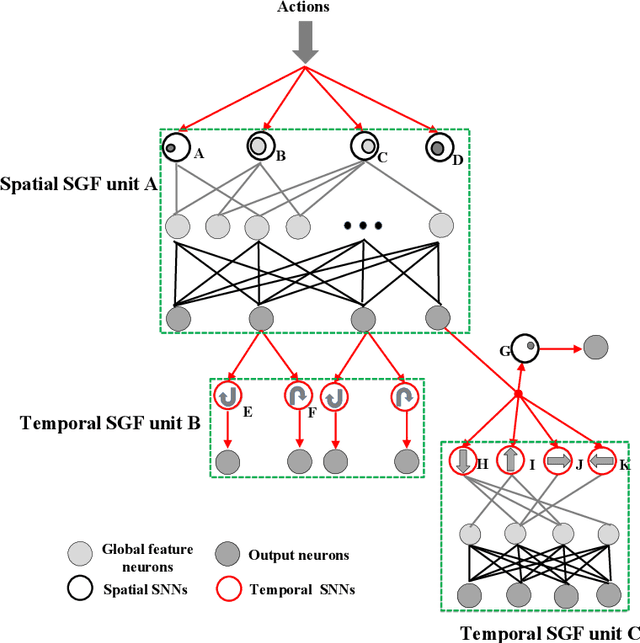
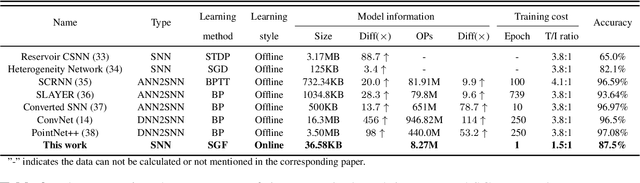
Action recognition is an exciting research avenue for artificial intelligence since it may be a game changer in the emerging industrial fields such as robotic visions and automobiles. However, current deep learning faces major challenges for such applications because of the huge computational cost and the inefficient learning. Hence, we develop a novel brain-inspired Spiking Neural Network (SNN) based system titled Spiking Gating Flow (SGF) for online action learning. The developed system consists of multiple SGF units which assembled in a hierarchical manner. A single SGF unit involves three layers: a feature extraction layer, an event-driven layer and a histogram-based training layer. To demonstrate the developed system capabilities, we employ a standard Dynamic Vision Sensor (DVS) gesture classification as a benchmark. The results indicate that we can achieve 87.5% accuracy which is comparable with Deep Learning (DL), but at smaller training/inference data number ratio 1.5:1. And only a single training epoch is required during the learning process. Meanwhile, to the best of our knowledge, this is the highest accuracy among the non-backpropagation algorithm based SNNs. At last, we conclude the few-shot learning paradigm of the developed network: 1) a hierarchical structure-based network design involves human prior knowledge; 2) SNNs for content based global dynamic feature detection.
Task-Specific Expert Pruning for Sparse Mixture-of-Experts
Jun 02, 2022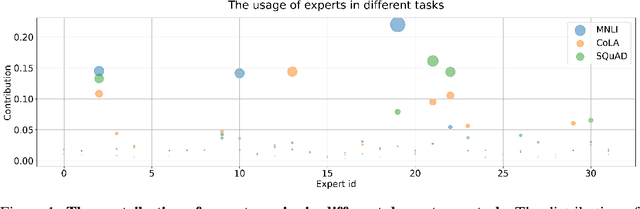
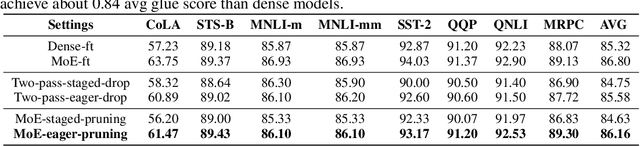
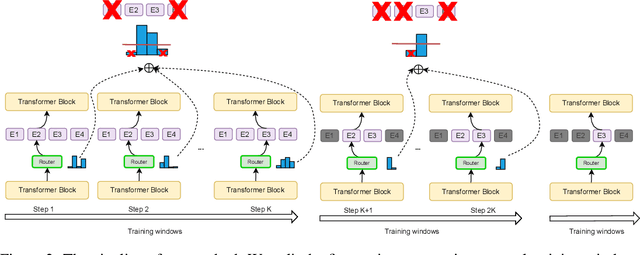
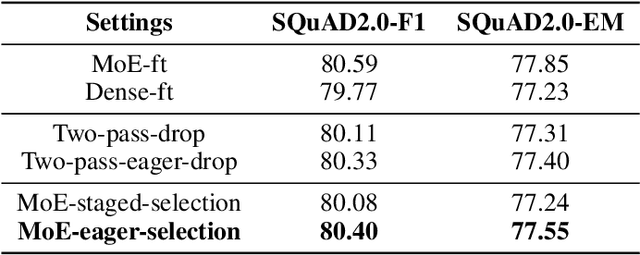
The sparse Mixture-of-Experts (MoE) model is powerful for large-scale pre-training and has achieved promising results due to its model capacity. However, with trillions of parameters, MoE is hard to be deployed on cloud or mobile environment. The inference of MoE requires expert parallelism, which is not hardware-friendly and communication expensive. Especially for resource-limited downstream tasks, such sparse structure has to sacrifice a lot of computing efficiency for limited performance gains. In this work, we observe most experts contribute scarcely little to the MoE fine-tuning and inference. We further propose a general method to progressively drop the non-professional experts for the target downstream task, which preserves the benefits of MoE while reducing the MoE model into one single-expert dense model. Our experiments reveal that the fine-tuned single-expert model could preserve 99.3% benefits from MoE across six different types of tasks while enjoying 2x inference speed with free communication cost.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
LAKe-Net: Topology-Aware Point Cloud Completion by Localizing Aligned Keypoints
Mar 31, 2022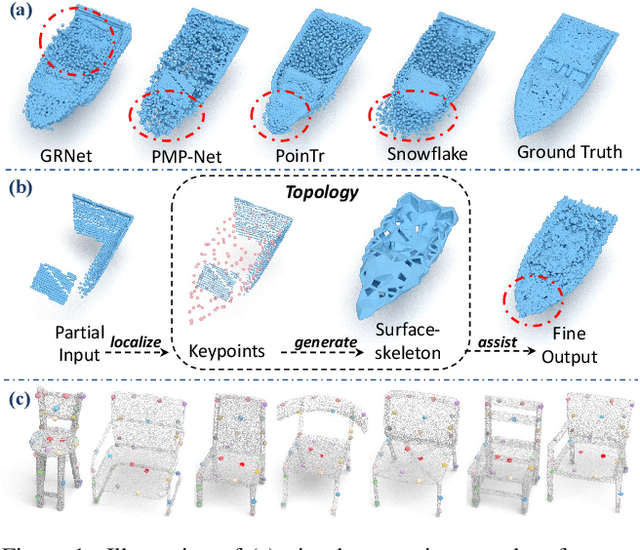

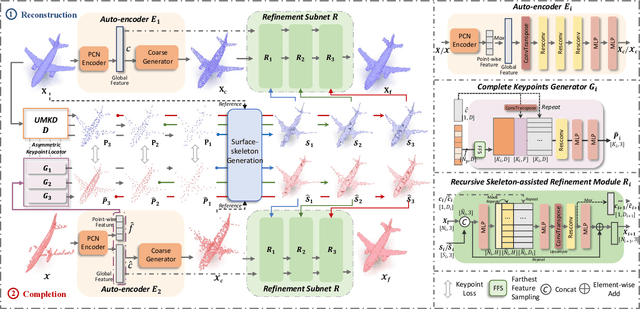
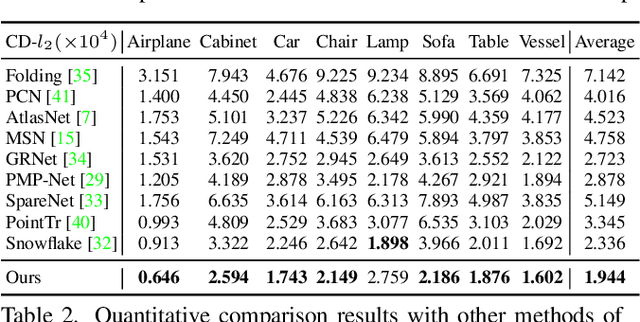
Point cloud completion aims at completing geometric and topological shapes from a partial observation. However, some topology of the original shape is missing, existing methods directly predict the location of complete points, without predicting structured and topological information of the complete shape, which leads to inferior performance. To better tackle the missing topology part, we propose LAKe-Net, a novel topology-aware point cloud completion model by localizing aligned keypoints, with a novel Keypoints-Skeleton-Shape prediction manner. Specifically, our method completes missing topology using three steps: 1) Aligned Keypoint Localization. An asymmetric keypoint locator, including an unsupervised multi-scale keypoint detector and a complete keypoint generator, is proposed for localizing aligned keypoints from complete and partial point clouds. We theoretically prove that the detector can capture aligned keypoints for objects within a sub-category. 2) Surface-skeleton Generation. A new type of skeleton, named Surface-skeleton, is generated from keypoints based on geometric priors to fully represent the topological information captured from keypoints and better recover the local details. 3) Shape Refinement. We design a refinement subnet where multi-scale surface-skeletons are fed into each recursive skeleton-assisted refinement module to assist the completion process. Experimental results show that our method achieves the state-of-the-art performance on point cloud completion.
CHEX: CHannel EXploration for CNN Model Compression
Mar 29, 2022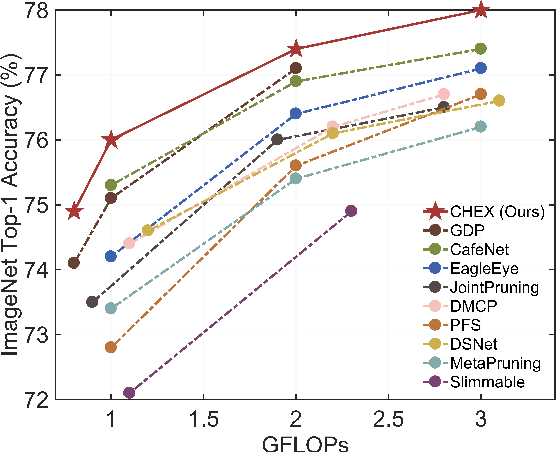
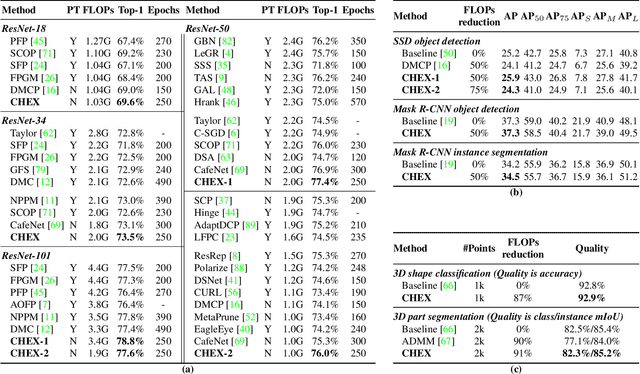
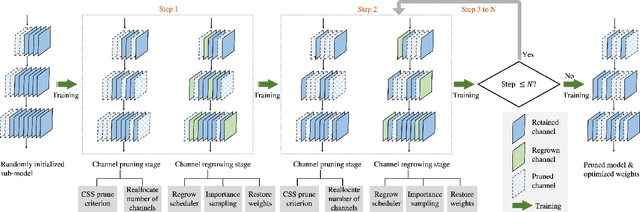

Channel pruning has been broadly recognized as an effective technique to reduce the computation and memory cost of deep convolutional neural networks. However, conventional pruning methods have limitations in that: they are restricted to pruning process only, and they require a fully pre-trained large model. Such limitations may lead to sub-optimal model quality as well as excessive memory and training cost. In this paper, we propose a novel Channel Exploration methodology, dubbed as CHEX, to rectify these problems. As opposed to pruning-only strategy, we propose to repeatedly prune and regrow the channels throughout the training process, which reduces the risk of pruning important channels prematurely. More exactly: From intra-layer's aspect, we tackle the channel pruning problem via a well known column subset selection (CSS) formulation. From inter-layer's aspect, our regrowing stages open a path for dynamically re-allocating the number of channels across all the layers under a global channel sparsity constraint. In addition, all the exploration process is done in a single training from scratch without the need of a pre-trained large model. Experimental results demonstrate that CHEX can effectively reduce the FLOPs of diverse CNN architectures on a variety of computer vision tasks, including image classification, object detection, instance segmentation, and 3D vision. For example, our compressed ResNet-50 model on ImageNet dataset achieves 76% top1 accuracy with only 25% FLOPs of the original ResNet-50 model, outperforming previous state-of-the-art channel pruning methods. The checkpoints and code are available at here .
Dynamic N:M Fine-grained Structured Sparse Attention Mechanism
Feb 28, 2022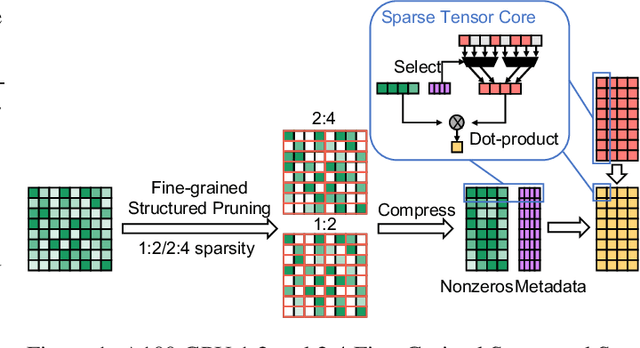
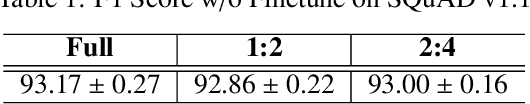
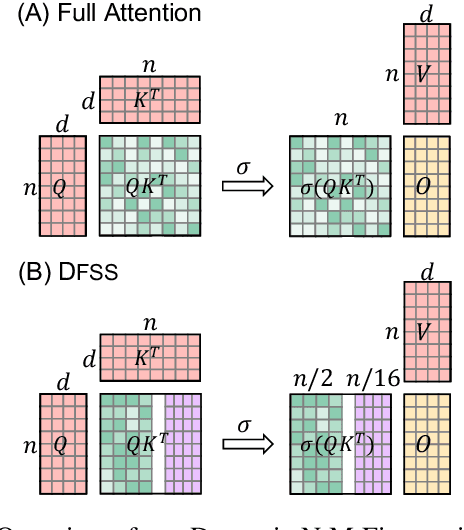
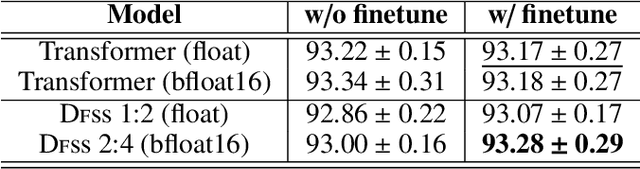
Transformers are becoming the mainstream solutions for various tasks like NLP and Computer vision. Despite their success, the high complexity of the attention mechanism hinders them from being applied to latency-sensitive tasks. Tremendous efforts have been made to alleviate this problem, and many of them successfully reduce the asymptotic complexity to linear. Nevertheless, most of them fail to achieve practical speedup over the original full attention under moderate sequence lengths and are unfriendly to finetuning. In this paper, we present DFSS, an attention mechanism that dynamically prunes the full attention weight matrix to N:M fine-grained structured sparse pattern. We provide both theoretical and empirical evidence that demonstrates DFSS is a good approximation of the full attention mechanism. We propose a dedicated CUDA kernel design that completely eliminates the dynamic pruning overhead and achieves speedups under arbitrary sequence length. We evaluate the 1:2 and 2:4 sparsity under different configurations and achieve 1.27~ 1.89x speedups over the full-attention mechanism. It only takes a couple of finetuning epochs from the pretrained model to achieve on par accuracy with full attention mechanism on tasks from various domains under different sequence lengths from 384 to 4096.
Survey on Graph Neural Network Acceleration: An Algorithmic Perspective
Feb 10, 2022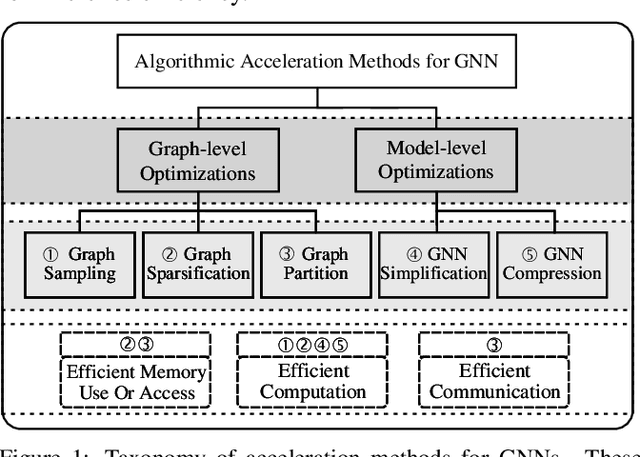
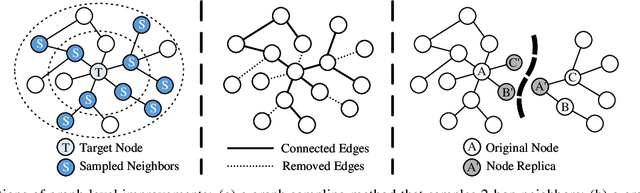

Graph neural networks (GNNs) have been a hot spot of recent research and are widely utilized in diverse applications. However, with the use of huger data and deeper models, an urgent demand is unsurprisingly made to accelerate GNNs for more efficient execution. In this paper, we provide a comprehensive survey on acceleration methods for GNNs from an algorithmic perspective. We first present a new taxonomy to classify existing acceleration methods into five categories. Based on the classification, we systematically discuss these methods and highlight their correlations. Next, we provide comparisons from aspects of the efficiency and characteristics of these methods. Finally, we suggest some promising prospects for future research.
Hybrid Graph Models for Logic Optimization via Spatio-Temporal Information
Jan 20, 2022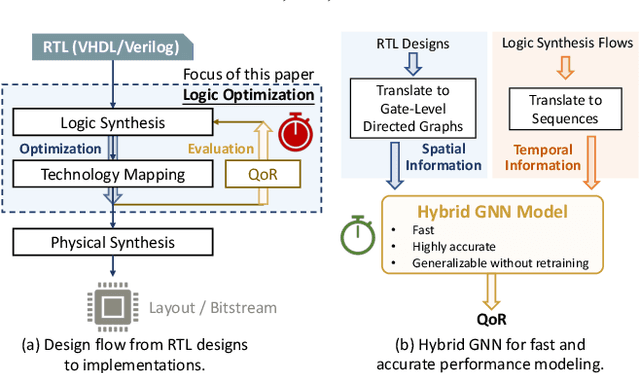



Despite the stride made by machine learning (ML) based performance modeling, two major concerns that may impede production-ready ML applications in EDA are stringent accuracy requirements and generalization capability. To this end, we propose hybrid graph neural network (GNN) based approaches towards highly accurate quality-of-result (QoR) estimations with great generalization capability, specifically targeting logic synthesis optimization. The key idea is to simultaneously leverage spatio-temporal information from hardware designs and logic synthesis flows to forecast performance (i.e., delay/area) of various synthesis flows on different designs. The structural characteristics inside hardware designs are distilled and represented by GNNs; the temporal knowledge (i.e., relative ordering of logic transformations) in synthesis flows can be imposed on hardware designs by combining a virtually added supernode or a sequence processing model with conventional GNN models. Evaluation on 3.3 million data points shows that the testing mean absolute percentage error (MAPE) on designs seen and unseen during training are no more than 1.2% and 3.1%, respectively, which are 7-15X lower than existing studies.