 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Vision Misleads, Let Location Speak: A Worldwide Image Geo-Localization Method via Location Attention Mechanism and Large Multimodal Models
Jun 08, 2026Worldwide image geo-localization aims to determine the capture location of an image on a global scale. Existing methods often mislocalize images by matching them to visually similar scenes from different geographic regions, which limits reliability in practical applications. To address this issue, we propose TransGeoCLIP, a novel retrieval-based framework that integrates a location attention mechanism and large multimodal models (LMMs). Using the Transformer encoder with location attention to encode GPS coordinates, TransGeoCLIP can effectively distinguish geographic features among visually similar images. The framework consists of two stages: 1) Retrieval database construction, which employs Transformers equipped with location attention mechanisms to encode labeled GPS coordinates and enhance location semantics, subsequently enables joint image-text-GPS embedding through CLIP; 2) Retrieval-augmented inference, which leverages LMMs to infer the final image location prediction from retrieved database results. Extensive experimental results on diverse datasets, including IM2GPS, IM2GPS3k, YFCC4k, and YFCC26k, demonstrate that TransGeoCLIP significantly enhances localization performance for visually similar images. Particularly, street-level localization accuracy (within 1 km error) is substantially improved, surpassing state-of-the-art methods by 1.5%, 1.07%, 7.18%, and 9.75% on these benchmarks, respectively.
Learning manifold diffusion semigroups from graph transition matrices
May 25, 2026We consider graph diffusion processes constructed from finite i.i.d. samples drawn from an unknown manifold embedded in ambient Euclidean space, where the graph affinity is defined by an ambient Gaussian kernel matrix. We show that the manifold heat semigroup $Q_t = e^{tΔ}$ can be approximated directly by iterating the graph transition matrix $P$, under only low regularity assumptions on the test function $f$, including the case $f \in L^\infty$. We bound $\| P^n f - Q_t f \|$ in $\infty$-norm, with the operator application to $f$ properly defined, and we recover the classical graph-Laplacian pointwise rate $O(N^{-2/(d+6)})$ up to logarithmic factors, for diffusion times $t $ up to $O(1)$ and longer. The rate holds for in-sample error as well as out-of-sample generalization, where the estimator of $Q_t f$ at a new point is defined via kernel convolution. To handle non-uniform sampling densities on the manifold, we introduce a right-normalization of the graph transition matrix; under the assumption that the sampling density $p$ is $C^3$ and bounded away from zero, the same convergence rates hold. We numerically demonstrate the performance of the proposed estimator on simulated data.
DanQing: An Up-to-Date Large-Scale Chinese Vision-Language Pre-training Dataset
Jan 15, 2026Vision-Language Pre-training (VLP) models demonstrate strong performance across various downstream tasks by learning from large-scale image-text pairs through contrastive pretraining. The release of extensive English image-text datasets (e.g., COYO-700M and LAION-400M) has enabled widespread adoption of models such as CLIP and SigLIP in tasks including cross-modal retrieval and image captioning. However, the advancement of Chinese vision-language pretraining has substantially lagged behind, due to the scarcity of high-quality Chinese image-text data. To address this gap, we develop a comprehensive pipeline for constructing a high-quality Chinese cross-modal dataset. As a result, we propose DanQing, which contains 100 million image-text pairs collected from Common Crawl. Different from existing datasets, DanQing is curated through a more rigorous selection process, yielding superior data quality. Moreover, DanQing is primarily built from 2024-2025 web data, enabling models to better capture evolving semantic trends and thus offering greater practical utility. We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model. Experimental results show that DanQing consistently achieves superior performance across a range of Chinese downstream tasks, including zero-shot classification, cross-modal retrieval, and LMM-based evaluations. To facilitate further research in Chinese vision-language pre-training, we will open-source the DanQing dataset under the Creative Common CC-BY 4.0 license.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
Dec 18, 2025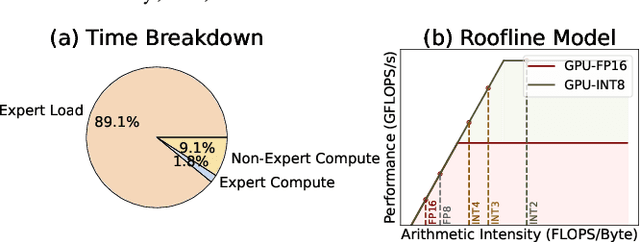

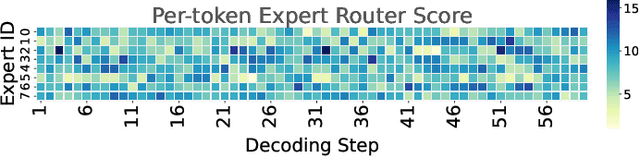
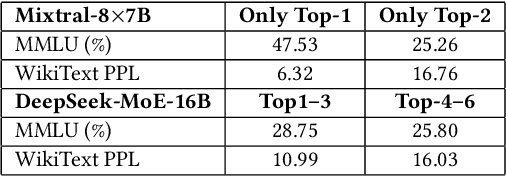
Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
zkUnlearner: A Zero-Knowledge Framework for Verifiable Unlearning with Multi-Granularity and Forgery-Resistance
Sep 08, 2025As the demand for exercising the "right to be forgotten" grows, the need for verifiable machine unlearning has become increasingly evident to ensure both transparency and accountability. We present {\em zkUnlearner}, the first zero-knowledge framework for verifiable machine unlearning, specifically designed to support {\em multi-granularity} and {\em forgery-resistance}. First, we propose a general computational model that employs a {\em bit-masking} technique to enable the {\em selectivity} of existing zero-knowledge proofs of training for gradient descent algorithms. This innovation enables not only traditional {\em sample-level} unlearning but also more advanced {\em feature-level} and {\em class-level} unlearning. Our model can be translated to arithmetic circuits, ensuring compatibility with a broad range of zero-knowledge proof systems. Furthermore, our approach overcomes key limitations of existing methods in both efficiency and privacy. Second, forging attacks present a serious threat to the reliability of unlearning. Specifically, in Stochastic Gradient Descent optimization, gradients from unlearned data, or from minibatches containing it, can be forged using alternative data samples or minibatches that exclude it. We propose the first effective strategies to resist state-of-the-art forging attacks. Finally, we benchmark a zkSNARK-based instantiation of our framework and perform comprehensive performance evaluations to validate its practicality.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Forecast-Then-Optimize Deep Learning Methods
Jun 16, 2025Time series forecasting underpins vital decision-making across various sectors, yet raw predictions from sophisticated models often harbor systematic errors and biases. We examine the Forecast-Then-Optimize (FTO) framework, pioneering its systematic synopsis. Unlike conventional Predict-Then-Optimize (PTO) methods, FTO explicitly refines forecasts through optimization techniques such as ensemble methods, meta-learners, and uncertainty adjustments. Furthermore, deep learning and large language models have established superiority over traditional parametric forecasting models for most enterprise applications. This paper surveys significant advancements from 2016 to 2025, analyzing mainstream deep learning FTO architectures. Focusing on real-world applications in operations management, we demonstrate FTO's crucial role in enhancing predictive accuracy, robustness, and decision efficacy. Our study establishes foundational guidelines for future forecasting methodologies, bridging theory and operational practicality.
SwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
From Tokens to Materials: Leveraging Language Models for Scientific Discovery
Oct 21, 2024



Exploring the predictive capabilities of language models in material science is an ongoing interest. This study investigates the application of language model embeddings to enhance material property prediction in materials science. By evaluating various contextual embedding methods and pre-trained models, including Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformers (GPT), we demonstrate that domain-specific models, particularly MatBERT significantly outperform general-purpose models in extracting implicit knowledge from compound names and material properties. Our findings reveal that information-dense embeddings from the third layer of MatBERT, combined with a context-averaging approach, offer the most effective method for capturing material-property relationships from the scientific literature. We also identify a crucial "tokenizer effect," highlighting the importance of specialized text processing techniques that preserve complete compound names while maintaining consistent token counts. These insights underscore the value of domain-specific training and tokenization in materials science applications and offer a promising pathway for accelerating the discovery and development of new materials through AI-driven approaches.