 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaDSE: A Few-shot Meta-learning Framework for Cross-workload CPU Design Space Exploration
Apr 18, 2025



Cross-workload design space exploration (DSE) is crucial in CPU architecture design. Existing DSE methods typically employ the transfer learning technique to leverage knowledge from source workloads, aiming to minimize the requirement of target workload simulation. However, these methods struggle with overfitting, data ambiguity, and workload dissimilarity. To address these challenges, we reframe the cross-workload CPU DSE task as a few-shot meta-learning problem and further introduce MetaDSE. By leveraging model agnostic meta-learning, MetaDSE swiftly adapts to new target workloads, greatly enhancing the efficiency of cross-workload CPU DSE. Additionally, MetaDSE introduces a novel knowledge transfer method called the workload-adaptive architectural mask algorithm, which uncovers the inherent properties of the architecture. Experiments on SPEC CPU 2017 demonstrate that MetaDSE significantly reduces prediction error by 44.3\% compared to the state-of-the-art. MetaDSE is open-sourced and available at this \href{https://anonymous.4open.science/r/Meta_DSE-02F8}{anonymous GitHub.}
RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation
Apr 11, 2025



As an essential part of modern hardware design, manually writing Register Transfer Level (RTL) code such as Verilog is often labor-intensive. Following the tremendous success of large language models (LLMs), researchers have begun to explore utilizing LLMs for generating RTL code. However, current studies primarily focus on generating simple single modules, which can not meet the demands in real world. In fact, due to challenges in managing long-context RTL code and complex cross-file dependencies, existing solutions cannot handle large-scale Verilog repositories in practical hardware development. As the first endeavor to exclusively adapt LLMs for large-scale RTL development, we propose RTLRepoCoder, a groundbreaking solution that incorporates specific fine-tuning and Retrieval-Augmented Generation (RAG) for repository-level Verilog code completion. Open-source Verilog repositories from the real world, along with an extended context size, are used for domain-specific fine-tuning. The optimized RAG system improves the information density of the input context by retrieving relevant code snippets. Tailored optimizations for RAG are carried out, including the embedding model, the cross-file context splitting strategy, and the chunk size. Our solution achieves state-of-the-art performance on public benchmark, significantly surpassing GPT-4 and advanced domain-specific LLMs on Edit Similarity and Exact Match rate. Comprehensive experiments demonstrate the remarkable effectiveness of our approach and offer insights for future work.
Cost-Effective Label-free Node Classification with LLMs
Dec 16, 2024



Graph neural networks (GNNs) have emerged as go-to models for node classification in graph data due to their powerful abilities in fusing graph structures and attributes. However, such models strongly rely on adequate high-quality labeled data for training, which are expensive to acquire in practice. With the advent of large language models (LLMs), a promising way is to leverage their superb zero-shot capabilities and massive knowledge for node labeling. Despite promising results reported, this methodology either demands considerable queries to LLMs, or suffers from compromised performance caused by noisy labels produced by LLMs. To remedy these issues, this work presents Cella, an active self-training framework that integrates LLMs into GNNs in a cost-effective manner. The design recipe of Cella is to iteratively identify small sets of "critical" samples using GNNs and extract informative pseudo-labels for them with both LLMs and GNNs as additional supervision signals to enhance model training. Particularly, Cella includes three major components: (i) an effective active node selection strategy for initial annotations; (ii) a judicious sample selection scheme to sift out the "critical" nodes based on label disharmonicity and entropy; and (iii) a label refinement module combining LLMs and GNNs with rewired topology. Our extensive experiments over five benchmark text-attributed graph datasets demonstrate that Cella significantly outperforms the state of the arts under the same query budget to LLMs in terms of label-free node classification. In particular, on the DBLP dataset with 14.3k nodes, Cella is able to achieve an 8.08% conspicuous improvement in accuracy over the state-of-the-art at a cost of less than one cent.
Multi-objective Optimization in CPU Design Space Exploration: Attention is All You Need
Oct 24, 2024



Design space exploration (DSE) enables architects to systematically evaluate various design options, guiding decisions on the most suitable configurations to meet specific objectives such as optimizing performance, power, and area. However, the growing complexity of modern CPUs has dramatically increased the number of micro-architectural parameters and expanded the overall design space, making DSE more challenging and time-consuming. Existing DSE frameworks struggle in large-scale design spaces due to inaccurate models and limited insights into parameter impact, hindering efficient identification of optimal micro-architectures within tight timeframes. In this work, we introduce AttentionDSE. Its key idea is to use the attention mechanism to establish a direct mapping of micro-architectural parameters to their contributions to predicted performance. This approach enhances both the prediction accuracy and interpretability of the performance model. Furthermore, the weights are dynamically adjusted, enabling the model to respond to design changes and effectively pinpoint the key micro-architectural parameters/components responsible for performance bottlenecks. Thus, AttentionDSE accurately, purposefully, and rapidly discovers optimal designs. Experiments on SPEC 2017 demonstrate that AttentionDSE significantly reduces exploration time by over 80\% and achieves 3.9\% improvement in Pareto Hypervolume compared to state-of-the-art DSE frameworks while maintaining superior prediction accuracy and efficiency with an increasing number of parameters.
SiHGNN: Leveraging Properties of Semantic Graphs for Efficient HGNN Acceleration
Aug 27, 2024Heterogeneous Graph Neural Networks (HGNNs) have expanded graph representation learning to heterogeneous graph fields. Recent studies have demonstrated their superior performance across various applications, including medical analysis and recommendation systems, often surpassing existing methods. However, GPUs often experience inefficiencies when executing HGNNs due to their unique and complex execution patterns. Compared to traditional Graph Neural Networks, these patterns further exacerbate irregularities in memory access. To tackle these challenges, recent studies have focused on developing domain-specific accelerators for HGNNs. Nonetheless, most of these efforts have concentrated on optimizing the datapath or scheduling data accesses, while largely overlooking the potential benefits that could be gained from leveraging the inherent properties of the semantic graph, such as its topology, layout, and generation. In this work, we focus on leveraging the properties of semantic graphs to enhance HGNN performance. First, we analyze the Semantic Graph Build (SGB) stage and identify significant opportunities for data reuse during semantic graph generation. Next, we uncover the phenomenon of buffer thrashing during the Graph Feature Processing (GFP) stage, revealing potential optimization opportunities in semantic graph layout. Furthermore, we propose a lightweight hardware accelerator frontend for HGNNs, called SiHGNN. This accelerator frontend incorporates a tree-based Semantic Graph Builder for efficient semantic graph generation and features a novel Graph Restructurer for optimizing semantic graph layouts. Experimental results show that SiHGNN enables the state-of-the-art HGNN accelerator to achieve an average performance improvement of 2.95$\times$.
Characterizing and Understanding HGNN Training on GPUs
Jul 16, 2024Owing to their remarkable representation capabilities for heterogeneous graph data, Heterogeneous Graph Neural Networks (HGNNs) have been widely adopted in many critical real-world domains such as recommendation systems and medical analysis. Prior to their practical application, identifying the optimal HGNN model parameters tailored to specific tasks through extensive training is a time-consuming and costly process. To enhance the efficiency of HGNN training, it is essential to characterize and analyze the execution semantics and patterns within the training process to identify performance bottlenecks. In this study, we conduct an in-depth quantification and analysis of two mainstream HGNN training scenarios, including single-GPU and multi-GPU distributed training. Based on the characterization results, we disclose the performance bottlenecks and their underlying causes in different HGNN training scenarios and provide optimization guidelines from both software and hardware perspectives.
Disttack: Graph Adversarial Attacks Toward Distributed GNN Training
May 10, 2024



Graph Neural Networks (GNNs) have emerged as potent models for graph learning. Distributing the training process across multiple computing nodes is the most promising solution to address the challenges of ever-growing real-world graphs. However, current adversarial attack methods on GNNs neglect the characteristics and applications of the distributed scenario, leading to suboptimal performance and inefficiency in attacking distributed GNN training. In this study, we introduce Disttack, the first framework of adversarial attacks for distributed GNN training that leverages the characteristics of frequent gradient updates in a distributed system. Specifically, Disttack corrupts distributed GNN training by injecting adversarial attacks into one single computing node. The attacked subgraphs are precisely perturbed to induce an abnormal gradient ascent in backpropagation, disrupting gradient synchronization between computing nodes and thus leading to a significant performance decline of the trained GNN. We evaluate Disttack on four large real-world graphs by attacking five widely adopted GNNs. Compared with the state-of-the-art attack method, experimental results demonstrate that Disttack amplifies the model accuracy degradation by 2.75$\times$ and achieves speedup by 17.33$\times$ on average while maintaining unnoticeability.
Revisiting Edge Perturbation for Graph Neural Network in Graph Data Augmentation and Attack
Mar 10, 2024



Edge perturbation is a basic method to modify graph structures. It can be categorized into two veins based on their effects on the performance of graph neural networks (GNNs), i.e., graph data augmentation and attack. Surprisingly, both veins of edge perturbation methods employ the same operations, yet yield opposite effects on GNNs' accuracy. A distinct boundary between these methods in using edge perturbation has never been clearly defined. Consequently, inappropriate perturbations may lead to undesirable outcomes, necessitating precise adjustments to achieve desired effects. Therefore, questions of ``why edge perturbation has a two-faced effect?'' and ``what makes edge perturbation flexible and effective?'' still remain unanswered. In this paper, we will answer these questions by proposing a unified formulation and establishing a clear boundary between two categories of edge perturbation methods. Specifically, we conduct experiments to elucidate the differences and similarities between these methods and theoretically unify the workflow of these methods by casting it to one optimization problem. Then, we devise Edge Priority Detector (EPD) to generate a novel priority metric, bridging these methods up in the workflow. Experiments show that EPD can make augmentation or attack flexibly and achieve comparable or superior performance to other counterparts with less time overhead.
A Comprehensive Survey on Distributed Training of Graph Neural Networks
Nov 11, 2022Graph neural networks (GNNs) have been demonstrated to be a powerful algorithmic model in broad application fields for their effectiveness in learning over graphs. To scale GNN training up for large-scale and ever-growing graphs, the most promising solution is distributed training which distributes the workload of training across multiple computing nodes. However, the workflows, computational patterns, communication patterns, and optimization techniques of distributed GNN training remain preliminarily understood. In this paper, we provide a comprehensive survey of distributed GNN training by investigating various optimization techniques used in distributed GNN training. First, distributed GNN training is classified into several categories according to their workflows. In addition, their computational patterns and communication patterns, as well as the optimization techniques proposed by recent work are introduced. Second, the software frameworks and hardware platforms of distributed GNN training are also introduced for a deeper understanding. Third, distributed GNN training is compared with distributed training of deep neural networks, emphasizing the uniqueness of distributed GNN training. Finally, interesting issues and opportunities in this field are discussed.
Rethinking Efficiency and Redundancy in Training Large-scale Graphs
Sep 02, 2022
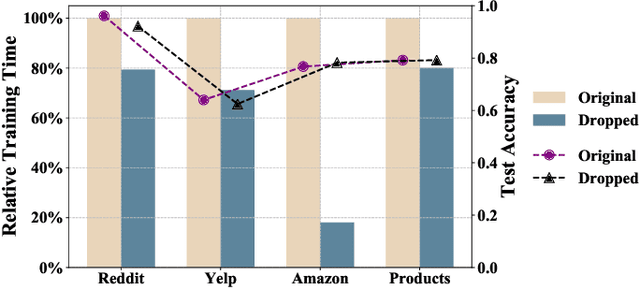
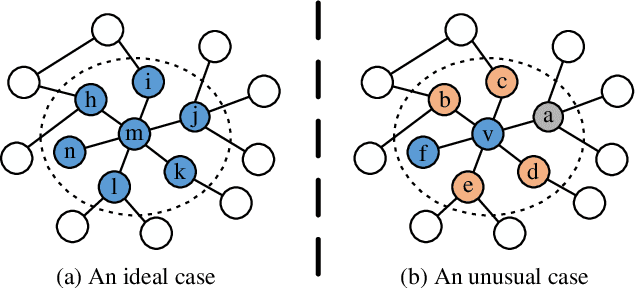
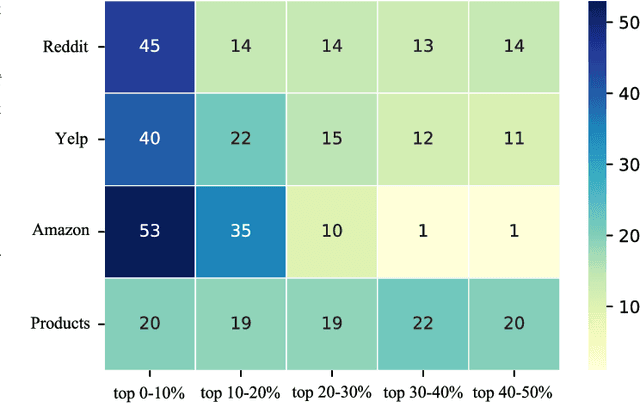
Large-scale graphs are ubiquitous in real-world scenarios and can be trained by Graph Neural Networks (GNNs) to generate representation for downstream tasks. Given the abundant information and complex topology of a large-scale graph, we argue that redundancy exists in such graphs and will degrade the training efficiency. Unfortunately, the model scalability severely restricts the efficiency of training large-scale graphs via vanilla GNNs. Despite recent advances in sampling-based training methods, sampling-based GNNs generally overlook the redundancy issue. It still takes intolerable time to train these models on large-scale graphs. Thereby, we propose to drop redundancy and improve efficiency of training large-scale graphs with GNNs, by rethinking the inherent characteristics in a graph. In this paper, we pioneer to propose a once-for-all method, termed DropReef, to drop the redundancy in large-scale graphs. Specifically, we first conduct preliminary experiments to explore potential redundancy in large-scale graphs. Next, we present a metric to quantify the neighbor heterophily of all nodes in a graph. Based on both experimental and theoretical analysis, we reveal the redundancy in a large-scale graph, i.e., nodes with high neighbor heterophily and a great number of neighbors. Then, we propose DropReef to detect and drop the redundancy in large-scale graphs once and for all, helping reduce the training time while ensuring no sacrifice in the model accuracy. To demonstrate the effectiveness of DropReef, we apply it to recent state-of-the-art sampling-based GNNs for training large-scale graphs, owing to the high precision of such models. With DropReef leveraged, the training efficiency of models can be greatly promoted. DropReef is highly compatible and is offline performed, benefiting the state-of-the-art sampling-based GNNs in the present and future to a significant extent.