 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
Dec 13, 2022



Software engineers working with the same programming language (PL) may speak different natural languages (NLs) and vice versa, erecting huge barriers to communication and working efficiency. Recent studies have demonstrated the effectiveness of generative pre-training in computer programs, yet they are always English-centric. In this work, we step towards bridging the gap between multilingual NLs and multilingual PLs for large language models (LLMs). We release ERNIE-Code, a unified pre-trained language model for 116 NLs and 6 PLs. We employ two methods for universal cross-lingual pre-training: span-corruption language modeling that learns patterns from monolingual NL or PL; and pivot-based translation language modeling that relies on parallel data of many NLs and PLs. Extensive results show that ERNIE-Code outperforms previous multilingual LLMs for PL or NL across a wide range of end tasks of code intelligence, including multilingual code-to-text, text-to-code, code-to-code, and text-to-text generation. We further show its advantage of zero-shot prompting on multilingual code summarization and text-to-text translation. We will make our code and pre-trained models publicly available.
X-PuDu at SemEval-2022 Task 6: Multilingual Learning for English and Arabic Sarcasm Detection
Nov 30, 2022Detecting sarcasm and verbal irony from people's subjective statements is crucial to understanding their intended meanings and real sentiments and positions in social scenarios. This paper describes the X-PuDu system that participated in SemEval-2022 Task 6, iSarcasmEval - Intended Sarcasm Detection in English and Arabic, which aims at detecting intended sarcasm in various settings of natural language understanding. Our solution finetunes pre-trained language models, such as ERNIE-M and DeBERTa, under the multilingual settings to recognize the irony from Arabic and English texts. Our system ranked second out of 43, and ninth out of 32 in Task A: one-sentence detection in English and Arabic; fifth out of 22 in Task B: binary multi-label classification in English; first out of 16, and fifth out of 13 in Task C: sentence-pair detection in English and Arabic.
X-PuDu at SemEval-2022 Task 7: A Replaced Token Detection Task Pre-trained Model with Pattern-aware Ensembling for Identifying Plausible Clarifications
Nov 27, 2022This paper describes our winning system on SemEval 2022 Task 7: Identifying Plausible Clarifications of Implicit and Underspecified Phrases in Instructional Texts. A replaced token detection pre-trained model is utilized with minorly different task-specific heads for SubTask-A: Multi-class Classification and SubTask-B: Ranking. Incorporating a pattern-aware ensemble method, our system achieves a 68.90% accuracy score and 0.8070 spearman's rank correlation score surpassing the 2nd place with a large margin by 2.7 and 2.2 percent points for SubTask-A and SubTask-B, respectively. Our approach is simple and easy to implement, and we conducted ablation studies and qualitative and quantitative analyses for the working strategies used in our system.
Coordinate-Based Seismic Interpolation in Irregular Land Survey: A Deep Internal Learning Approach
Nov 21, 2022



Physical and budget constraints often result in irregular sampling, which complicates accurate subsurface imaging. Pre-processing approaches, such as missing trace or shot interpolation, are typically employed to enhance seismic data in such cases. Recently, deep learning has been used to address the trace interpolation problem at the expense of large amounts of training data to adequately represent typical seismic events. Nonetheless, state-of-the-art works have mainly focused on trace reconstruction, with little attention having been devoted to shot interpolation. Furthermore, existing methods assume regularly spaced receivers/sources failing in approximating seismic data from real (irregular) surveys. This work presents a novel shot gather interpolation approach which uses a continuous coordinate-based representation of the acquired seismic wavefield parameterized by a neural network. The proposed unsupervised approach, which we call coordinate-based seismic interpolation (CoBSI), enables the prediction of specific seismic characteristics in irregular land surveys without using external data during neural network training. Experimental results on real and synthetic 3D data validate the ability of the proposed method to estimate continuous smooth seismic events in the time-space and frequency-wavenumber domains, improving sparsity or low rank-based interpolation methods.
ERNIE-UniX2: A Unified Cross-lingual Cross-modal Framework for Understanding and Generation
Nov 09, 2022Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
SDCL: Self-Distillation Contrastive Learning for Chinese Spell Checking
Nov 07, 2022Due to the ambiguity of homophones, Chinese Spell Checking (CSC) has widespread applications. Existing systems typically utilize BERT for text encoding. However, CSC requires the model to account for both phonetic and graphemic information. To adapt BERT to the CSC task, we propose a token-level self-distillation contrastive learning method. We employ BERT to encode both the corrupted and corresponding correct sentence. Then, we use contrastive learning loss to regularize corrupted tokens' hidden states to be closer to counterparts in the correct sentence. On three CSC datasets, we confirmed our method provides a significant improvement above baselines.
ERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
Oct 27, 2022



Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, which progressively upgrades the quality of generated images~by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves the state-of-the-art on MS-COCO with zero-shot FID score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300.
CPS-MEBR: Click Feedback-Aware Web Page Summarization for Multi-Embedding-Based Retrieval
Oct 19, 2022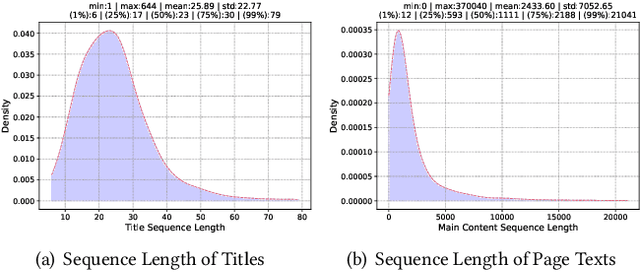
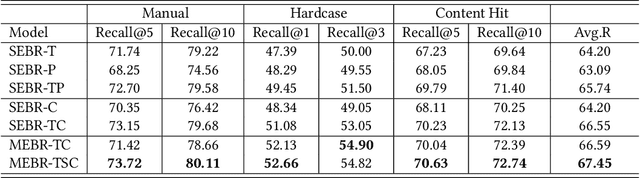

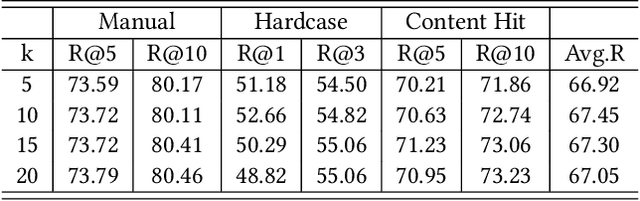
Embedding-based retrieval (EBR) is a technique to use embeddings to represent query and document, and then convert the retrieval problem into a nearest neighbor search problem in the embedding space. Some previous works have mainly focused on representing the web page with a single embedding, but in real web search scenarios, it is difficult to represent all the information of a long and complex structured web page as a single embedding. To address this issue, we design a click feedback-aware web page summarization for multi-embedding-based retrieval (CPS-MEBR) framework which is able to generate multiple embeddings for web pages to match different potential queries. Specifically, we use the click data of users in search logs to train a summary model to extract those sentences in web pages that are frequently clicked by users, which are more likely to answer those potential queries. Meanwhile, we introduce sentence-level semantic interaction to design a multi-embedding-based retrieval (MEBR) model, which can generate multiple embeddings to deal with different potential queries by using frequently clicked sentences in web pages. Offline experiments show that it can perform high quality candidate retrieval compared to single-embedding-based retrieval (SEBR) model.
ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022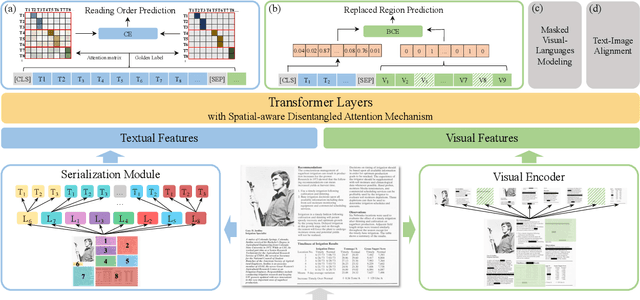
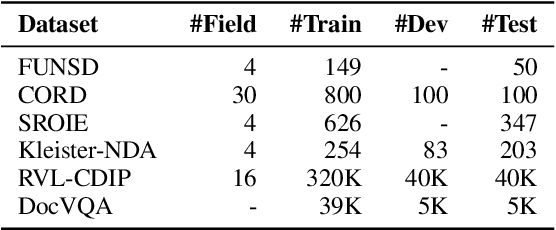
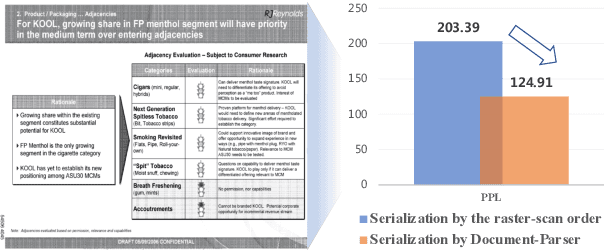
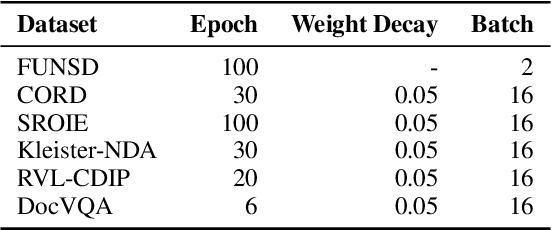
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.