 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Air-Ground Collaboration: A Progressive Cross-Task Benchmark and Socialized Learning Framework
Jun 17, 2026Air-ground collaborative perception is crucial for robust visual understanding in real-world dynamic environments. However, existing studies typically formulate collaboration as single-task cross-view fusion, overlooking the functional dependencies among localization, target association, and fine-grained parsing. In addition, the heterogeneous nature of aerial and ground views introduces substantial geometric, scale, and occlusion discrepancies, making uniform feature sharing vulnerable to negative transfer. To tackle these issues, we model air-ground perception as a progressive cross-task collaboration task and construct the Air-Ground Progressive Collaboration (AGPC) benchmark, a spatio-temporally aligned benchmark comprising more than 745K raw video frames. Built upon this benchmark, we propose Socialized Co-Perception (SCP), a coarse-to-fine framework that organizes collaboration progressively from aerial global localization to ground target association and identity-aware parsing. Its core module, the Dual-Layer Router (DLR), decouples input-side multi-scale expert selection from output-side task-conditioned modulation, enabling selective cross-view and cross-task interaction while suppressing harmful interference. Extensive experiments demonstrate the effectiveness of SCP. It achieves a 3.73\% coevolutionary gain and a 7.86\% improvement in average downstream performance. These results show that task-conditioned collaboration is more effective than uniform fusion for heterogeneous air-ground perception. The code is available at https://github.com/g1136639260-spec/AGSCP.
RGBX-R1: Visual Modality Chain-of-Thought Guided Reinforcement Learning for Multimodal Grounding
Jan 31, 2026Multimodal Large Language Models (MLLM) are primarily pre-trained on the RGB modality, thereby limiting their performance on other modalities, such as infrared, depth, and event data, which are crucial for complex scenarios. To address this, we propose RGBX-R1, a framework to enhance MLLM's perception and reasoning capacities across various X visual modalities. Specifically, we employ an Understand-Associate-Validate (UAV) prompting strategy to construct the Visual Modality Chain-of-Thought (VM-CoT), which aims to expand the MLLMs' RGB understanding capability into X modalities. To progressively enhance reasoning capabilities, we introduce a two-stage training paradigm: Cold-Start Supervised Fine-Tuning (CS-SFT) and Spatio-Temporal Reinforcement Fine-Tuning (ST-RFT). CS-SFT supervises the reasoning process with the guidance of VM-CoT, equipping the MLLM with fundamental modality cognition. Building upon GRPO, ST-RFT employs a Modality-understanding Spatio-Temporal (MuST) reward to reinforce modality reasoning. Notably, we construct the first RGBX-Grounding benchmark, and extensive experiments verify our superiority in multimodal understanding and spatial perception, outperforming baselines by 22.71% on three RGBX grounding tasks.
Reversible Efficient Diffusion for Image Fusion
Jan 28, 2026Multi-modal image fusion aims to consolidate complementary information from diverse source images into a unified representation. The fused image is expected to preserve fine details and maintain high visual fidelity. While diffusion models have demonstrated impressive generative capabilities in image generation, they often suffer from detail loss when applied to image fusion tasks. This issue arises from the accumulation of noise errors inherent in the Markov process, leading to inconsistency and degradation in the fused results. However, incorporating explicit supervision into end-to-end training of diffusion-based image fusion introduces challenges related to computational efficiency. To address these limitations, we propose the Reversible Efficient Diffusion (RED) model - an explicitly supervised training framework that inherits the powerful generative capability of diffusion models while avoiding the distribution estimation.
Non-Invasive Diagnosis for Clubroot Using Terahertz Time-Domain Spectroscopy and Physics-Constrained Neural Networks
Jan 19, 2026Clubroot, a major soilborne disease affecting canola and other cruciferous crops, is characterized by the development of large galls on the roots of susceptible hosts. In this study, we present the first application of terahertz time-domain spectroscopy (THz-TDS) as a non-invasive diagnosis tool in plant pathology. Compared with conventional molecular, spectroscopic, and immunoassay-based methods, THz-TDS offers distinct advantages, including non-contact, non-destructive, and preparation-free measurement, enabling rapid in situ screening of plant and soil samples. Our results demonstrate that THz-TDS can differentiate between healthy and clubroot-infected tissues by detecting both structural and biochemical alterations. Specifically, infected roots exhibit a blue shift in the refractive index in the low-frequency THz range, along with distinct peaks-indicative of disruptions in water transport and altered metabolic activity in both roots and leaves. Interestingly, the characteristic root swelling observed in infected plants reflects internal tissue disorganization rather than an actual increase in water content. Furthermore, a physics-constrained neural network is proposed to extract the main feature in THz-TDS. A comprehensive evaluation, including time-domain signals, amplitude and phase images, refractive index and absorption coefficient maps, and principal component analysis, provides enhanced contrast and spatial resolution compared to raw time-domain or frequency signals. These findings suggest that THz-TDS holds significant potential for early, non-destructive detection of plant diseases and may serve as a valuable tool to limit their spread in agricultural systems.
Principal Component Analysis-Based Terahertz Self-Supervised Denoising and Deblurring Deep Neural Networks
Jan 17, 2026Terahertz (THz) systems inherently introduce frequency-dependent degradation effects, resulting in low-frequency blurring and high-frequency noise in amplitude images. Conventional image processing techniques cannot simultaneously address both issues, and manual intervention is often required due to the unknown boundary between denoising and deblurring. To tackle this challenge, we propose a principal component analysis (PCA)-based THz self-supervised denoising and deblurring network (THz-SSDD). The network employs a Recorrupted-to-Recorrupted self-supervised learning strategy to capture the intrinsic features of noise by exploiting invariance under repeated corruption. PCA decomposition and reconstruction are then applied to restore images across both low and high frequencies. The performance of the THz-SSDD network was evaluated on four types of samples. Training requires only a small set of unlabeled noisy images, and testing across samples with different material properties and measurement modes demonstrates effective denoising and deblurring. Quantitative analysis further validates the network feasibility, showing improvements in image quality while preserving the physical characteristics of the original signals.
CtrlFuse: Mask-Prompt Guided Controllable Infrared and Visible Image Fusion
Jan 12, 2026Infrared and visible image fusion generates all-weather perception-capable images by combining complementary modalities, enhancing environmental awareness for intelligent unmanned systems. Existing methods either focus on pixel-level fusion while overlooking downstream task adaptability or implicitly learn rigid semantics through cascaded detection/segmentation models, unable to interactively address diverse semantic target perception needs. We propose CtrlFuse, a controllable image fusion framework that enables interactive dynamic fusion guided by mask prompts. The model integrates a multi-modal feature extractor, a reference prompt encoder (RPE), and a prompt-semantic fusion module (PSFM). The RPE dynamically encodes task-specific semantic prompts by fine-tuning pre-trained segmentation models with input mask guidance, while the PSFM explicitly injects these semantics into fusion features. Through synergistic optimization of parallel segmentation and fusion branches, our method achieves mutual enhancement between task performance and fusion quality. Experiments demonstrate state-of-the-art results in both fusion controllability and segmentation accuracy, with the adapted task branch even outperforming the original segmentation model.
Unleashing Degradation-Carrying Features in Symmetric U-Net: Simpler and Stronger Baselines for All-in-One Image Restoration
Dec 11, 2025All-in-one image restoration aims to handle diverse degradations (e.g., noise, blur, adverse weather) within a unified framework, yet existing methods increasingly rely on complex architectures (e.g., Mixture-of-Experts, diffusion models) and elaborate degradation prompt strategies. In this work, we reveal a critical insight: well-crafted feature extraction inherently encodes degradation-carrying information, and a symmetric U-Net architecture is sufficient to unleash these cues effectively. By aligning feature scales across encoder-decoder and enabling streamlined cross-scale propagation, our symmetric design preserves intrinsic degradation signals robustly, rendering simple additive fusion in skip connections sufficient for state-of-the-art performance. Our primary baseline, SymUNet, is built on this symmetric U-Net and achieves better results across benchmark datasets than existing approaches while reducing computational cost. We further propose a semantic enhanced variant, SE-SymUNet, which integrates direct semantic injection from frozen CLIP features via simple cross-attention to explicitly amplify degradation priors. Extensive experiments on several benchmarks validate the superiority of our methods. Both baselines SymUNet and SE-SymUNet establish simpler and stronger foundations for future advancements in all-in-one image restoration. The source code is available at https://github.com/WenlongJiao/SymUNet.
Point Cloud Quantization through Multimodal Prompting for 3D Understanding
Nov 19, 2025Vector quantization has emerged as a powerful tool in large-scale multimodal models, unifying heterogeneous representations through discrete token encoding. However, its effectiveness hinges on robust codebook design. Current prototype-based approaches relying on trainable vectors or clustered centroids fall short in representativeness and interpretability, even as multimodal alignment demonstrates its promise in vision-language models. To address these limitations, we propose a simple multimodal prompting-driven quantization framework for point cloud analysis. Our methodology is built upon two core insights: 1) Text embeddings from pre-trained models inherently encode visual semantics through many-to-one contrastive alignment, naturally serving as robust prototype priors; and 2) Multimodal prompts enable adaptive refinement of these prototypes, effectively mitigating vision-language semantic gaps. The framework introduces a dual-constrained quantization space, enforced by compactness and separation regularization, which seamlessly integrates visual and prototype features, resulting in hybrid representations that jointly encode geometric and semantic information. Furthermore, we employ Gumbel-Softmax relaxation to achieve differentiable discretization while maintaining quantization sparsity. Extensive experiments on the ModelNet40 and ScanObjectNN datasets clearly demonstrate the superior effectiveness of the proposed method.
BasicAVSR: Arbitrary-Scale Video Super-Resolution via Image Priors and Enhanced Motion Compensation
Oct 30, 2025Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we propose a strong baseline BasicAVSR for AVSR by integrating four key components: 1) adaptive multi-scale frequency priors generated from image Laplacian pyramids, 2) a flow-guided propagation unit to aggregate spatiotemporal information from adjacent frames, 3) a second-order motion compensation unit for more accurate spatial alignment of adjacent frames, and 4) a hyper-upsampling unit to generate scale-aware and content-independent upsampling kernels. To meet diverse application demands, we instantiate three propagation variants: (i) a unidirectional RNN unit for strictly online inference, (ii) a unidirectional RNN unit empowered with a limited lookahead that tolerates a small output delay, and (iii) a bidirectional RNN unit designed for offline tasks where computational resources are less constrained. Experimental results demonstrate the effectiveness and adaptability of our model across these different scenarios. Through extensive experiments, we show that BasicAVSR significantly outperforms existing methods in terms of super-resolution quality, generalization ability, and inference speed. Our work not only advances the state-of-the-art in AVSR but also extends its core components to multiple frameworks for diverse scenarios. The code is available at https://github.com/shangwei5/BasicAVSR.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025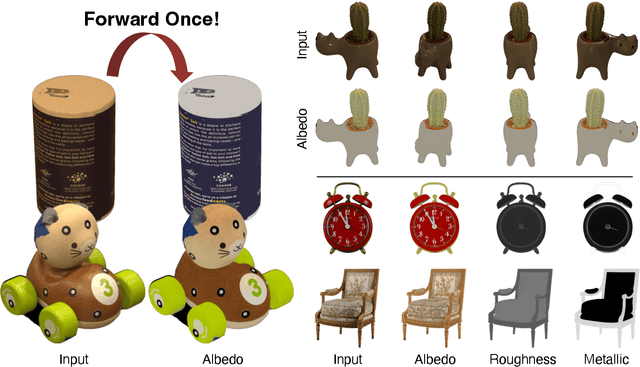



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.