 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Translation between Sign Languages
May 20, 2026The field of sign language translation has witnessed significant progress in the translation between sign and spoken languages, but the translation between sign languages remains largely unexplored and out of reach. The latter can help 1.5 billion deaf and hard-of-hearing (DHH) people worldwide communicate across language barriers without relying on hearing interpreters or written-language fluency. The cascade approach composing separate sign-to-text, text-to-text, and text-to-sign systems suffers from error propagation and extra latency as well as the loss of information unique in the visual modality. We aim to develop direct sign-to-sign translation. However, a large-scale open-domain parallel corpus has not been curated between sign languages. To enable direct translation between sign language utterances, we use back-translation to produce synthetic sign-sign pairs from unaligned individual language utterance-sign corpora. Using this data, we jointly train a single MBART-based model for both text->sign (T2S) and sign->sign (S2S). On synthetically generated paired sets between American Sign Language (ASL), Chinese Sign Language (CSL), and German Sign Language (DGS), our direct S2S method outperforms the cascaded baseline on geometric sign error metrics (20% lower DTW-aligned MPJPE) and language matching metrics after predicted sign utterances are translated back to sentences (50% high BLEU-4) while achieving a roughly 2.3* speedup. On a small set of pre-existing cross-lingual sign data, we find similar improvements for our proposed method.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
AlayaLaser: Efficient Index Layout and Search Strategy for Large-scale High-dimensional Vector Similarity Search
Feb 26, 2026On-disk graph-based approximate nearest neighbor search (ANNS) is essential for large-scale, high-dimensional vector retrieval, yet its performance is widely recognized to be limited by the prohibitive I/O costs. Interestingly, we observed that the performance of on-disk graph-based index systems is compute-bound, not I/O-bound, with the rising of the vector data dimensionality (e.g., hundreds or thousands). This insight uncovers a significant optimization opportunity: existing on-disk graph-based index systems universally target I/O reduction and largely overlook computational overhead, which leaves a substantial performance improvement space. In this work, we propose AlayaLaser, an efficient on-disk graph-based index system for large-scale high-dimensional vector similarity search. In particular, we first conduct performance analysis on existing on-disk graph-based index systems via the adapted roofline model, then we devise a novel on-disk data layout in AlayaLaser to effectively alleviate the compute-bound, which is revealed by the above roofline model analysis, by exploiting SIMD instructions on modern CPUs. We next design a suite of optimization techniques (e.g., degree-based node cache, cluster-based entry point selection, and early dispatch strategy) to further improve the performance of AlayaLaser. We last conduct extensive experimental studies on a wide range of large-scale high-dimensional vector datasets to verify the superiority of AlayaLaser. Specifically, AlayaLaser not only surpasses existing on-disk graph-based index systems but also matches or even exceeds the performance of in-memory index systems.
Designing RNAs with Language Models
Feb 12, 2026RNA design, the task of finding a sequence that folds into a target secondary structure, has broad biological and biomedical impact but remains computationally challenging due to the exponentially large sequence space and exponentially many competing folds. Traditional approaches treat it as an optimization problem, relying on per-instance heuristics or constraint-based search. We instead reframe RNA design as conditional sequence generation and introduce a reusable neural approximator, instantiated as an autoregressive language model (LM), that maps target structures directly to sequences. We first train our model in a supervised setting on random-induced structure-sequence pairs, and then use reinforcement learning (RL) to optimize end-to-end metrics. We also propose methods to select a small subset for RL that greatly improves RL efficiency and quality. Across four datasets, our approach outperforms state-of-the-art systems on key metrics such as Boltzmann probability while being 1.7x faster, establishing conditional LM generation as a scalable, task-agnostic alternative to per-instance optimization for RNA design. Our code and data are available at https://github.com/KuNyaa/RNA-Design-LM.
Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support
Feb 26, 2025Large language models (LLMs), particularly those with reasoning capabilities, have rapidly advanced in recent years, demonstrating significant potential across a wide range of applications. However, their deployment in healthcare, especially in disease reasoning tasks, is hindered by the challenge of acquiring expert-level cognitive data. In this paper, we introduce Citrus, a medical language model that bridges the gap between clinical expertise and AI reasoning by emulating the cognitive processes of medical experts. The model is trained on a large corpus of simulated expert disease reasoning data, synthesized using a novel approach that accurately captures the decision-making pathways of clinicians. This approach enables Citrus to better simulate the complex reasoning processes involved in diagnosing and treating medical conditions. To further address the lack of publicly available datasets for medical reasoning tasks, we release the last-stage training data, including a custom-built medical diagnostic dialogue dataset. This open-source contribution aims to support further research and development in the field. Evaluations using authoritative benchmarks such as MedQA, covering tasks in medical reasoning and language understanding, show that Citrus achieves superior performance compared to other models of similar size. These results highlight Citrus potential to significantly enhance medical decision support systems, providing a more accurate and efficient tool for clinical decision-making.
Sampling-based Continuous Optimization with Coupled Variables for RNA Design
Dec 11, 2024The task of RNA design given a target structure aims to find a sequence that can fold into that structure. It is a computationally hard problem where some version(s) have been proven to be NP-hard. As a result, heuristic methods such as local search have been popular for this task, but by only exploring a fixed number of candidates. They can not keep up with the exponential growth of the design space, and often perform poorly on longer and harder-to-design structures. We instead formulate these discrete problems as continuous optimization, which starts with a distribution over all possible candidate sequences, and uses gradient descent to improve the expectation of an objective function. We define novel distributions based on coupled variables to rule out invalid sequences given the target structure and to model the correlation between nucleotides. To make it universally applicable to any objective function, we use sampling to approximate the expected objective function, to estimate the gradient, and to select the final candidate. Compared to the state-of-the-art methods, our work consistently outperforms them in key metrics such as Boltzmann probability, ensemble defect, and energy gap, especially on long and hard-to-design puzzles in the Eterna100 benchmark. Our code is available at: http://github.com/weiyutang1010/ncrna_design.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024



Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Messenger and Non-Coding RNA Design via Expected Partition Function and Continuous Optimization
Dec 29, 2023



The tasks of designing messenger RNAs and non-coding RNAs are discrete optimization problems, and several versions of these problems are NP-hard. As an alternative to commonly used local search methods, we formulate these problems as continuous optimization and develop a general framework for this optimization based on a new concept of "expected partition function". The basic idea is to start with a distribution over all possible candidate sequences, and extend the objective function from a sequence to a distribution. We then use gradient descent-based optimization methods to improve the extended objective function, and the distribution will gradually shrink towards a one-hot sequence (i.e., a single sequence). We consider two important case studies within this framework, the mRNA design problem optimizing for partition function (i.e., ensemble free energy) and the non-coding RNA design problem optimizing for conditional (i.e., Boltzmann) probability. In both cases, our approach demonstrate promising preliminary results. We make our code available at https://github.com/KuNyaa/RNA_Design_codebase.
ERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022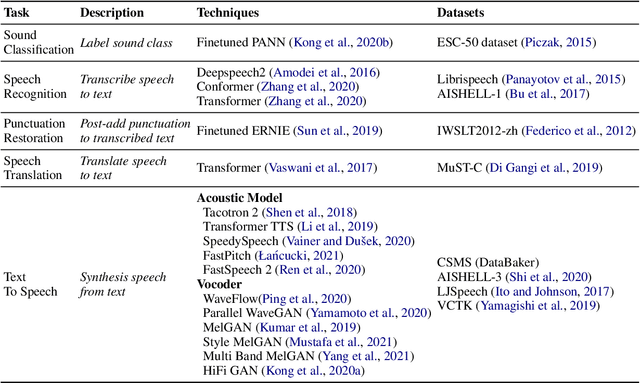
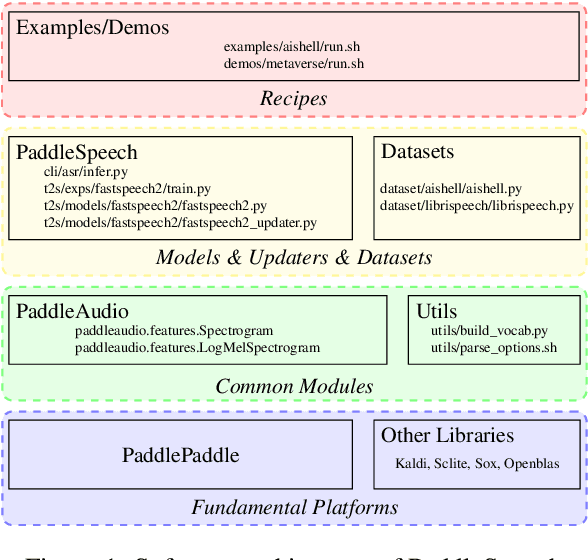
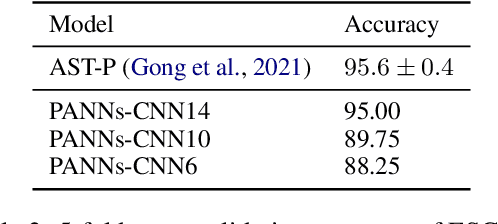
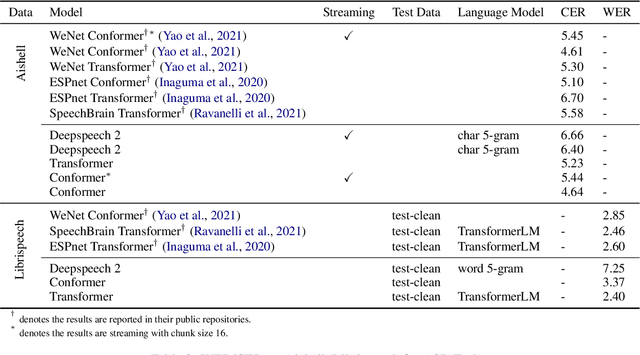
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.