 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
ArchCAD-400K: An Open Large-Scale Architectural CAD Dataset and New Baseline for Panoptic Symbol Spotting
Apr 02, 2025Recognizing symbols in architectural CAD drawings is critical for various advanced engineering applications. In this paper, we propose a novel CAD data annotation engine that leverages intrinsic attributes from systematically archived CAD drawings to automatically generate high-quality annotations, thus significantly reducing manual labeling efforts. Utilizing this engine, we construct ArchCAD-400K, a large-scale CAD dataset consisting of 413,062 chunks from 5538 highly standardized drawings, making it over 26 times larger than the largest existing CAD dataset. ArchCAD-400K boasts an extended drawing diversity and broader categories, offering line-grained annotations. Furthermore, we present a new baseline model for panoptic symbol spotting, termed Dual-Pathway Symbol Spotter (DPSS). It incorporates an adaptive fusion module to enhance primitive features with complementary image features, achieving state-of-the-art performance and enhanced robustness. Extensive experiments validate the effectiveness of DPSS, demonstrating the value of ArchCAD-400K and its potential to drive innovation in architectural design and construction.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025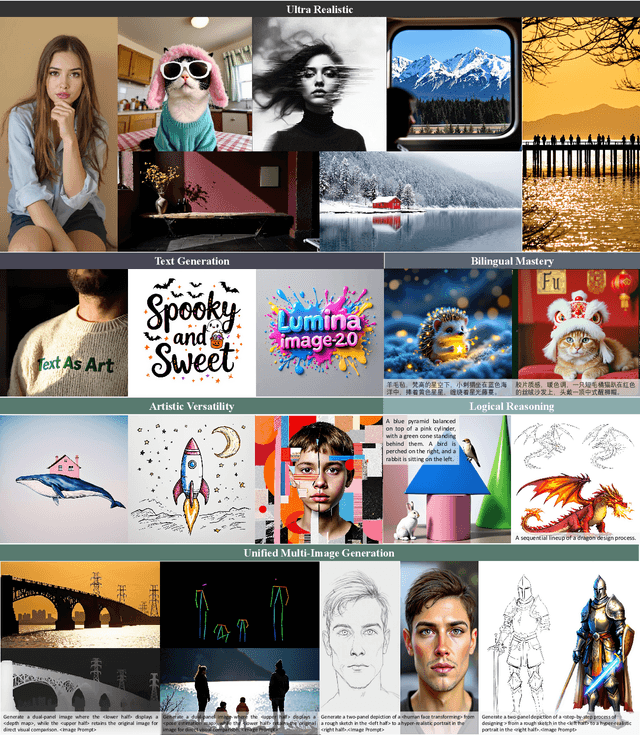
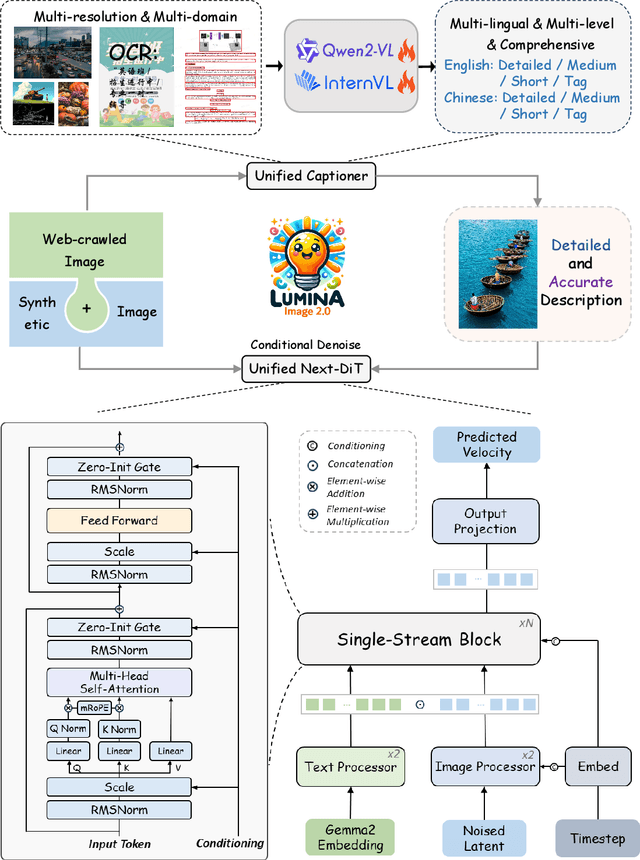

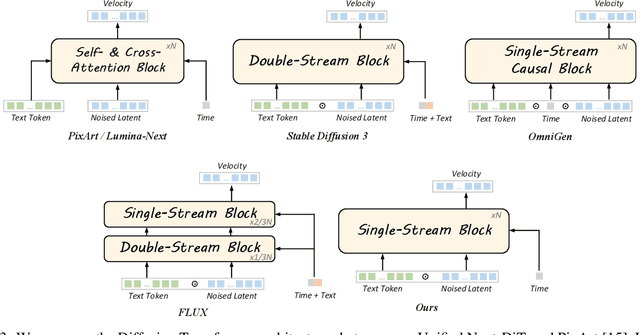
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.
AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
Mar 25, 2025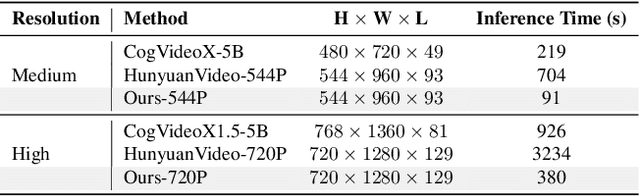
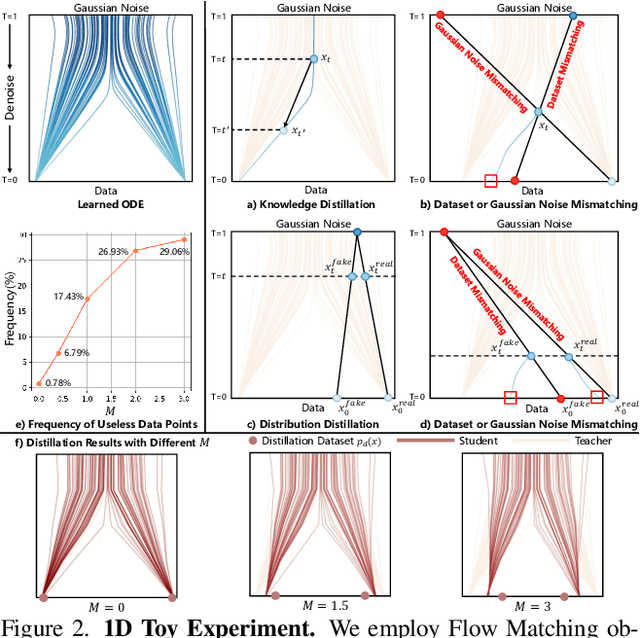

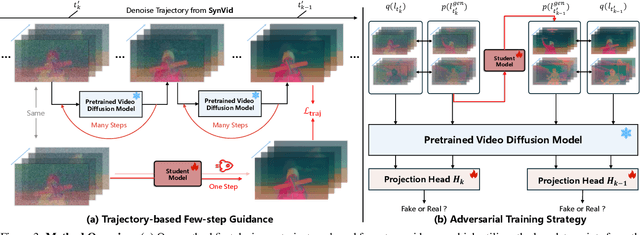
Diffusion models have achieved remarkable progress in the field of video generation. However, their iterative denoising nature requires a large number of inference steps to generate a video, which is slow and computationally expensive. In this paper, we begin with a detailed analysis of the challenges present in existing diffusion distillation methods and propose a novel efficient method, namely AccVideo, to reduce the inference steps for accelerating video diffusion models with synthetic dataset. We leverage the pretrained video diffusion model to generate multiple valid denoising trajectories as our synthetic dataset, which eliminates the use of useless data points during distillation. Based on the synthetic dataset, we design a trajectory-based few-step guidance that utilizes key data points from the denoising trajectories to learn the noise-to-video mapping, enabling video generation in fewer steps. Furthermore, since the synthetic dataset captures the data distribution at each diffusion timestep, we introduce an adversarial training strategy to align the output distribution of the student model with that of our synthetic dataset, thereby enhancing the video quality. Extensive experiments demonstrate that our model achieves 8.5x improvements in generation speed compared to the teacher model while maintaining comparable performance. Compared to previous accelerating methods, our approach is capable of generating videos with higher quality and resolution, i.e., 5-seconds, 720x1280, 24fps.
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
MSWAL: 3D Multi-class Segmentation of Whole Abdominal Lesions Dataset
Mar 17, 2025



With the significantly increasing incidence and prevalence of abdominal diseases, there is a need to embrace greater use of new innovations and technology for the diagnosis and treatment of patients. Although deep-learning methods have notably been developed to assist radiologists in diagnosing abdominal diseases, existing models have the restricted ability to segment common lesions in the abdomen due to missing annotations for typical abdominal pathologies in their training datasets. To address the limitation, we introduce MSWAL, the first 3D Multi-class Segmentation of the Whole Abdominal Lesions dataset, which broadens the coverage of various common lesion types, such as gallstones, kidney stones, liver tumors, kidney tumors, pancreatic cancer, liver cysts, and kidney cysts. With CT scans collected from 694 patients (191,417 slices) of different genders across various scanning phases, MSWAL demonstrates strong robustness and generalizability. The transfer learning experiment from MSWAL to two public datasets, LiTS and KiTS, effectively demonstrates consistent improvements, with Dice Similarity Coefficient (DSC) increase of 3.00% for liver tumors and 0.89% for kidney tumors, demonstrating that the comprehensive annotations and diverse lesion types in MSWAL facilitate effective learning across different domains and data distributions. Furthermore, we propose Inception nnU-Net, a novel segmentation framework that effectively integrates an Inception module with the nnU-Net architecture to extract information from different receptive fields, achieving significant enhancement in both voxel-level DSC and region-level F1 compared to the cutting-edge public algorithms on MSWAL. Our dataset will be released after being accepted, and the code is publicly released at https://github.com/tiuxuxsh76075/MSWAL-.
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning
Mar 13, 2025



We introduce VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, which improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families with Best-of-N (BoN) evaluation strategies. Specifically, our model improves the reasoning performance of three types of MLLMs and four different model scales. Even when applied to the highly capable InternVL2.5-78B, it achieves a 5.9-point improvement across seven multimodal reasoning benchmarks. Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation. To facilitate the training of multimodal PRMs, we construct a multimodal process supervision dataset VisualPRM400K using an automated data pipeline. For the evaluation of multimodal PRMs, we propose VisualProcessBench, a benchmark with human-annotated step-wise correctness labels, to measure the abilities of PRMs to detect erroneous steps in multimodal reasoning tasks. We hope that our work can inspire more future research and contribute to the development of MLLMs. Our model, data, and benchmark are released in https://internvl.github.io/blog/2025-03-13-VisualPRM/.
Exploring Mutual Empowerment Between Wireless Networks and RL-based LLMs: A Survey
Mar 13, 2025

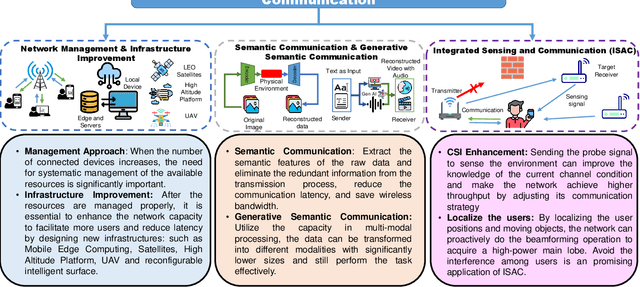
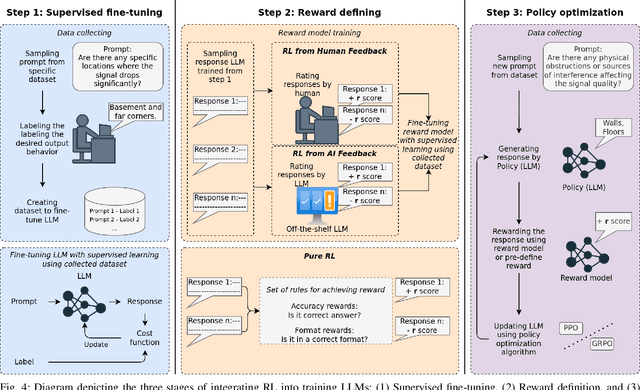
Reinforcement learning (RL)-based large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, have gained significant attention for their exceptional capabilities in natural language processing and multimodal data understanding. Meanwhile, the rapid expansion of information services has driven the growing need for intelligence, efficient, and adaptable wireless networks. Wireless networks require the empowerment of RL-based LLMs while these models also benefit from wireless networks to broaden their application scenarios. Specifically, RL-based LLMs can enhance wireless communication systems through intelligent resource allocation, adaptive network optimization, and real-time decision-making. Conversely, wireless networks provide a vital infrastructure for the efficient training, deployment, and distributed inference of RL-based LLMs, especially in decentralized and edge computing environments. This mutual empowerment highlights the need for a deeper exploration of the interplay between these two domains. We first review recent advancements in wireless communications, highlighting the associated challenges and potential solutions. We then discuss the progress of RL-based LLMs, focusing on key technologies for LLM training, challenges, and potential solutions. Subsequently, we explore the mutual empowerment between these two fields, highlighting key motivations, open challenges, and potential solutions. Finally, we provide insights into future directions, applications, and their societal impact to further explore this intersection, paving the way for next-generation intelligent communication systems. Overall, this survey provides a comprehensive overview of the relationship between RL-based LLMs and wireless networks, offering a vision where these domains empower each other to drive innovations.