 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
ACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
TimeFormer: Capturing Temporal Relationships of Deformable 3D Gaussians for Robust Reconstruction
Nov 18, 2024Dynamic scene reconstruction is a long-term challenge in 3D vision. Recent methods extend 3D Gaussian Splatting to dynamic scenes via additional deformation fields and apply explicit constraints like motion flow to guide the deformation. However, they learn motion changes from individual timestamps independently, making it challenging to reconstruct complex scenes, particularly when dealing with violent movement, extreme-shaped geometries, or reflective surfaces. To address the above issue, we design a plug-and-play module called TimeFormer to enable existing deformable 3D Gaussians reconstruction methods with the ability to implicitly model motion patterns from a learning perspective. Specifically, TimeFormer includes a Cross-Temporal Transformer Encoder, which adaptively learns the temporal relationships of deformable 3D Gaussians. Furthermore, we propose a two-stream optimization strategy that transfers the motion knowledge learned from TimeFormer to the base stream during the training phase. This allows us to remove TimeFormer during inference, thereby preserving the original rendering speed. Extensive experiments in the multi-view and monocular dynamic scenes validate qualitative and quantitative improvement brought by TimeFormer. Project Page: https://patrickddj.github.io/TimeFormer/
Diffusion Transformer Policy
Oct 21, 2024



Recent large visual-language action models pretrained on diverse robot datasets have demonstrated the potential for generalizing to new environments with a few in-domain data. However, those approaches usually predict discretized or continuous actions by a small action head, which limits the ability in handling diverse action spaces. In contrast, we model the continuous action with a large multi-modal diffusion transformer, dubbed as Diffusion Transformer Policy, in which we directly denoise action chunks by a large transformer model rather than a small action head. By leveraging the scaling capability of transformers, the proposed approach can effectively model continuous end-effector actions across large diverse robot datasets, and achieve better generalization performance. Extensive experiments demonstrate Diffusion Transformer Policy pretrained on diverse robot data can generalize to different embodiments, including simulation environments like Maniskill2 and Calvin, as well as the real-world Franka arm. Specifically, without bells and whistles, the proposed approach achieves state-of-the-art performance with only a single third-view camera stream in the Calvin novel task setting (ABC->D), improving the average number of tasks completed in a row of 5 to 3.6, and the pretraining stage significantly facilitates the success sequence length on the Calvin by over 1.2. The code will be publicly available.
Large Point-to-Gaussian Model for Image-to-3D Generation
Aug 20, 2024



Recently, image-to-3D approaches have significantly advanced the generation quality and speed of 3D assets based on large reconstruction models, particularly 3D Gaussian reconstruction models. Existing large 3D Gaussian models directly map 2D image to 3D Gaussian parameters, while regressing 2D image to 3D Gaussian representations is challenging without 3D priors. In this paper, we propose a large Point-to-Gaussian model, that inputs the initial point cloud produced from large 3D diffusion model conditional on 2D image to generate the Gaussian parameters, for image-to-3D generation. The point cloud provides initial 3D geometry prior for Gaussian generation, thus significantly facilitating image-to-3D Generation. Moreover, we present the \textbf{A}ttention mechanism, \textbf{P}rojection mechanism, and \textbf{P}oint feature extractor, dubbed as \textbf{APP} block, for fusing the image features with point cloud features. The qualitative and quantitative experiments extensively demonstrate the effectiveness of the proposed approach on GSO and Objaverse datasets, and show the proposed method achieves state-of-the-art performance.
Compositional 3D Human-Object Neural Animation
Apr 27, 2023



Human-object interactions (HOIs) are crucial for human-centric scene understanding applications such as human-centric visual generation, AR/VR, and robotics. Since existing methods mainly explore capturing HOIs, rendering HOI remains less investigated. In this paper, we address this challenge in HOI animation from a compositional perspective, i.e., animating novel HOIs including novel interaction, novel human and/or novel object driven by a novel pose sequence. Specifically, we adopt neural human-object deformation to model and render HOI dynamics based on implicit neural representations. To enable the interaction pose transferring among different persons and objects, we then devise a new compositional conditional neural radiance field (or CC-NeRF), which decomposes the interdependence between human and object using latent codes to enable compositionally animation control of novel HOIs. Experiments show that the proposed method can generalize well to various novel HOI animation settings. Our project page is https://zhihou7.github.io/CHONA/
AniPixel: Towards Animatable Pixel-Aligned Human Avatar
Feb 07, 2023Neural radiance field using pixel-aligned features can render photo-realistic novel views. However, when pixel-aligned features are directly introduced to human avatar reconstruction, the rendering can only be conducted for still humans, rather than animatable avatars. In this paper, we propose AniPixel, a novel animatable and generalizable human avatar reconstruction method that leverages pixel-aligned features for body geometry prediction and RGB color blending. Technically, to align the canonical space with the target space and the observation space, we propose a bidirectional neural skinning field based on skeleton-driven deformation to establish the target-to-canonical and canonical-to-observation correspondences. Then, we disentangle the canonical body geometry into a normalized neutral-sized body and a subject-specific residual for better generalizability. As the geometry and appearance are closely related, we introduce pixel-aligned features to facilitate the body geometry prediction and detailed surface normals to reinforce the RGB color blending. Moreover, we devise a pose-dependent and view direction-related shading module to represent the local illumination variance. Experiments show that our AniPixel renders comparable novel views while delivering better novel pose animation results than state-of-the-art methods. The code will be released.
BatchFormerV2: Exploring Sample Relationships for Dense Representation Learning
Apr 04, 2022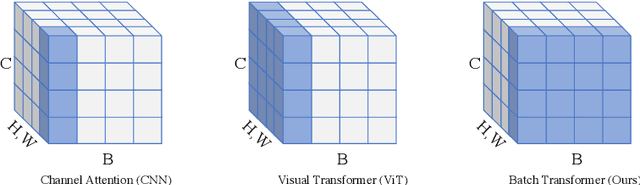
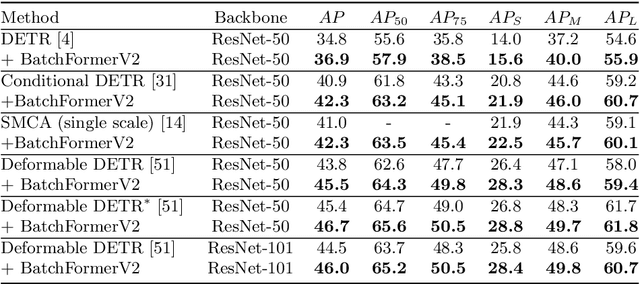
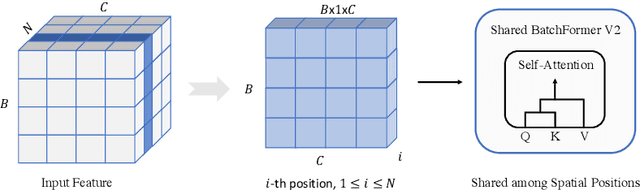

Attention mechanisms have been very popular in deep neural networks, where the Transformer architecture has achieved great success in not only natural language processing but also visual recognition applications. Recently, a new Transformer module, applying on batch dimension rather than spatial/channel dimension, i.e., BatchFormer [18], has been introduced to explore sample relationships for overcoming data scarcity challenges. However, it only works with image-level representations for classification. In this paper, we devise a more general batch Transformer module, BatchFormerV2, which further enables exploring sample relationships for dense representation learning. Specifically, when applying the proposed module, it employs a two-stream pipeline during training, i.e., either with or without a BatchFormerV2 module, where the batchformer stream can be removed for testing. Therefore, the proposed method is a plug-and-play module and can be easily integrated into different vision Transformers without any extra inference cost. Without bells and whistles, we show the effectiveness of the proposed method for a variety of popular visual recognition tasks, including image classification and two important dense prediction tasks: object detection and panoptic segmentation. Particularly, BatchFormerV2 consistently improves current DETR-based detection methods (e.g., DETR, Deformable-DETR, Conditional DETR, and SMCA) by over 1.3%. Code will be made publicly available.
BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning
Mar 29, 2022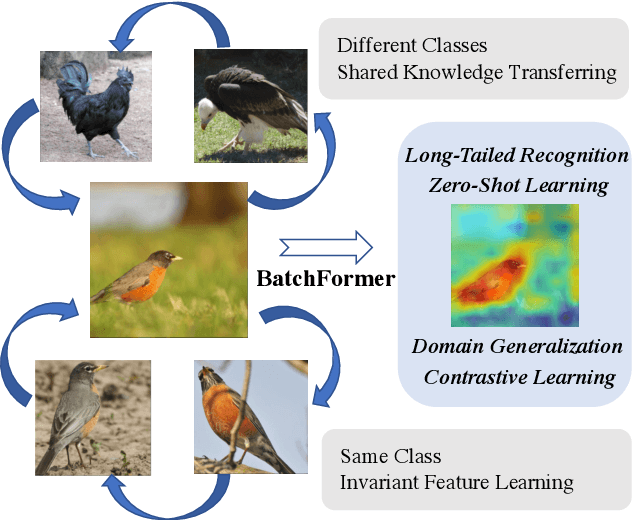
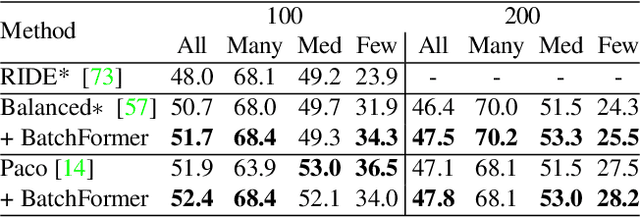
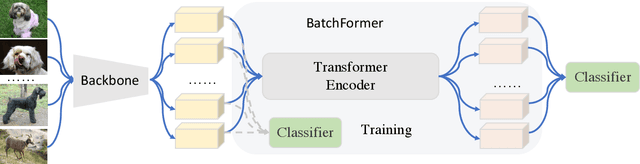
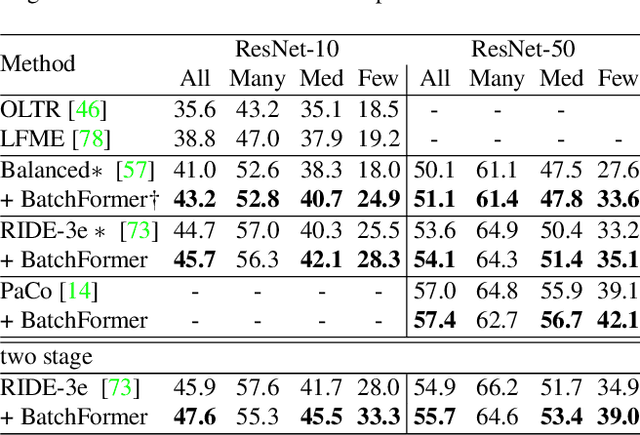
Despite the success of deep neural networks, there are still many challenges in deep representation learning due to the data scarcity issues such as data imbalance, unseen distribution, and domain shift. To address the above-mentioned issues, a variety of methods have been devised to explore the sample relationships in a vanilla way (i.e., from the perspectives of either the input or the loss function), failing to explore the internal structure of deep neural networks for learning with sample relationships. Inspired by this, we propose to enable deep neural networks themselves with the ability to learn the sample relationships from each mini-batch. Specifically, we introduce a batch transformer module or BatchFormer, which is then applied into the batch dimension of each mini-batch to implicitly explore sample relationships during training. By doing this, the proposed method enables the collaboration of different samples, e.g., the head-class samples can also contribute to the learning of the tail classes for long-tailed recognition. Furthermore, to mitigate the gap between training and testing, we share the classifier between with or without the BatchFormer during training, which can thus be removed during testing. We perform extensive experiments on over ten datasets and the proposed method achieves significant improvements on different data scarcity applications without any bells and whistles, including the tasks of long-tailed recognition, compositional zero-shot learning, domain generalization, and contrastive learning. Code will be made publicly available at https://github.com/zhihou7/BatchFormer.