 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis
Jan 31, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities, yet their performance is often capped by the coarse nature of existing alignment techniques. A critical bottleneck remains the lack of effective reward models (RMs): existing RMs are predominantly vision-centric, return opaque scalar scores, and rely on costly human annotations. We introduce \textbf{Omni-RRM}, the first open-source rubric-grounded reward model that produces structured, multi-dimension preference judgments with dimension-wise justifications across \textbf{text, image, video, and audio}. At the core of our approach is \textbf{Omni-Preference}, a large-scale dataset built via a fully automated pipeline: we synthesize candidate response pairs by contrasting models of different capabilities, and use strong teacher models to \emph{reconcile and filter} preferences while providing a modality-aware \emph{rubric-grounded rationale} for each pair. This eliminates the need for human-labeled training preferences. Omni-RRM is trained in two stages: supervised fine-tuning to learn the rubric-grounded outputs, followed by reinforcement learning (GRPO) to sharpen discrimination on difficult, low-contrast pairs. Comprehensive evaluations show that Omni-RRM achieves state-of-the-art accuracy on video (80.2\% on ShareGPT-V) and audio (66.8\% on Audio-HH-RLHF) benchmarks, and substantially outperforms existing open-source RMs on image tasks, with a 17.7\% absolute gain over its base model on overall accuracy. Omni-RRM also improves downstream performance via Best-of-$N$ selection and transfers to text-only preference benchmarks. Our data, code, and models are available at https://anonymous.4open.science/r/Omni-RRM-CC08.
S$^3$-Attention:Attention-Aligned Endogenous Retrieval for Memory-Bounded Long-Context Inference
Jan 25, 2026Large language models are increasingly applied to multi-document and long-form inputs, yet long-context inference remains memory- and noise-inefficient. Key-value (KV) caching scales linearly with context length, while external retrieval methods often return lexically similar but causally irrelevant passages. We present S3-Attention, a memory-first inference-time framework that treats long-context processing as attention-aligned endogenous retrieval. S3-Attention decodes transient key and query projections into top-k sparse feature identifiers using lightweight sparse autoencoders, and constructs a CPU-based inverted index mapping features to token positions or spans during a single streaming scan. This design allows the KV cache to be discarded entirely and bounds GPU memory usage by the scan chunk size. At generation time, feature co-activation is used to retrieve compact evidence spans, optionally fused with BM25 for exact lexical matching. Under a unified LongBench evaluation protocol with fixed prompting, decoding, and matched token budgets, S3-Hybrid closely matches full-context inference across multiple model families and improves robustness in several information-dense settings. We also report an engineering limitation of the current prototype, which incurs higher wall-clock latency than optimized full-KV baselines, motivating future kernel-level optimization.
Interpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
Dec 29, 2025Parameter-efficient fine-tuning has become the dominant paradigm for adapting large language models to downstream tasks. Low-rank adaptation methods such as LoRA operate under the assumption that task-relevant weight updates reside in a low-rank subspace, yet this subspace is learned implicitly from data in a black-box manner, offering no interpretability or direct control. We hypothesize that this difficulty stems from polysemanticity--individual dimensions encoding multiple entangled concepts. To address this, we leverage pre-trained Sparse Autoencoders (SAEs) to identify task-relevant features in a disentangled feature space, then construct an explicit, interpretable low-rank subspace to guide adapter initialization. We provide theoretical analysis proving that under monosemanticity assumptions, SAE-based subspace identification achieves arbitrarily small recovery error, while direct identification in polysemantic space suffers an irreducible error floor. On safety alignment, our method achieves up to 99.6% safety rate--exceeding full fine-tuning by 7.4 percentage points and approaching RLHF-based methods--while updating only 0.19-0.24% of parameters. Crucially, our method provides interpretable insights into the learned alignment subspace through the semantic grounding of SAE features. Our work demonstrates that incorporating mechanistic interpretability into the fine-tuning process can simultaneously improve both performance and transparency.
Unlocking the Address Book: Dissecting the Sparse Semantic Structure of LLM Key-Value Caches via Sparse Autoencoders
Dec 11, 2025



The Key-Value (KV) cache is the primary memory bottleneck in long-context Large Language Models, yet it is typically treated as an opaque numerical tensor. In this work, we propose \textbf{STA-Attention}, a framework that utilizes Top-K Sparse Autoencoders (SAEs) to decompose the KV cache into interpretable ``semantic atoms.'' Unlike standard $L_1$-regularized SAEs, our Top-K approach eliminates shrinkage bias, preserving the precise dot-product geometry required for attention. Our analysis uncovers a fundamental \textbf{Key-Value Asymmetry}: while Key vectors serve as highly sparse routers dominated by a ``Semantic Elbow,'' deep Value vectors carry dense content payloads requiring a larger budget. Based on this structure, we introduce a Dual-Budget Strategy that selectively preserves the most informative semantic components while filtering representational noise. Experiments on Yi-6B, Mistral-7B, Qwen2.5-32B, and others show that our semantic reconstructions maintain perplexity and zero-shot performance comparable to the original models, effectively bridging the gap between mechanistic interpretability and faithful attention modeling.
Beyond Darkness: Thermal-Supervised 3D Gaussian Splatting for Low-Light Novel View Synthesis
Nov 17, 2025Under extremely low-light conditions, novel view synthesis (NVS) faces severe degradation in terms of geometry, color consistency, and radiometric stability. Standard 3D Gaussian Splatting (3DGS) pipelines fail when applied directly to underexposed inputs, as independent enhancement across views causes illumination inconsistencies and geometric distortion. To address this, we present DTGS, a unified framework that tightly couples Retinex-inspired illumination decomposition with thermal-guided 3D Gaussian Splatting for illumination-invariant reconstruction. Unlike prior approaches that treat enhancement as a pre-processing step, DTGS performs joint optimization across enhancement, geometry, and thermal supervision through a cyclic enhancement-reconstruction mechanism. A thermal supervisory branch stabilizes both color restoration and geometry learning by dynamically balancing enhancement, structural, and thermal losses. Moreover, a Retinex-based decomposition module embedded within the 3DGS loop provides physically interpretable reflectance-illumination separation, ensuring consistent color and texture across viewpoints. To evaluate our method, we construct RGBT-LOW, a new multi-view low-light thermal dataset capturing severe illumination degradation. Extensive experiments show that DTGS significantly outperforms existing low-light enhancement and 3D reconstruction baselines, achieving superior radiometric consistency, geometric fidelity, and color stability under extreme illumination.
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
Oct 30, 2025Large vision language models (VLMs) have advanced graphical user interface (GUI) task automation but still lag behind humans. We hypothesize this gap stems from missing core GUI knowledge, which existing training schemes (such as supervised fine tuning and reinforcement learning) alone cannot fully address. By analyzing common failure patterns in GUI task execution, we distill GUI knowledge into three dimensions: (1) interface perception, knowledge about recognizing widgets and system states; (2) interaction prediction, knowledge about reasoning action state transitions; and (3) instruction understanding, knowledge about planning, verifying, and assessing task completion progress. We further introduce GUI Knowledge Bench, a benchmark with multiple choice and yes/no questions across six platforms (Web, Android, MacOS, Windows, Linux, IOS) and 292 applications. Our evaluation shows that current VLMs identify widget functions but struggle with perceiving system states, predicting actions, and verifying task completion. Experiments on real world GUI tasks further validate the close link between GUI knowledge and task success. By providing a structured framework for assessing GUI knowledge, our work supports the selection of VLMs with greater potential prior to downstream training and provides insights for building more capable GUI agents.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025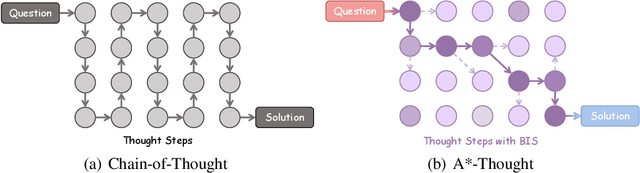
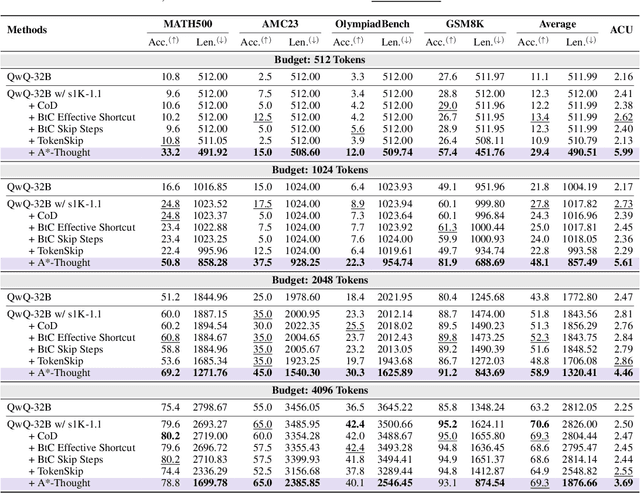
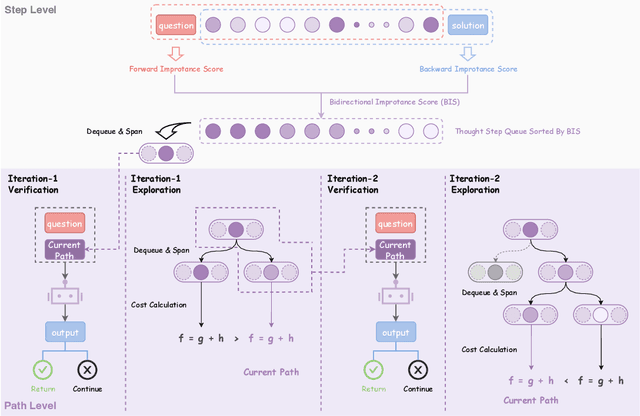

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
May 22, 2025In recent years, the rapid development of deepfake technology has given rise to an emerging and serious threat to public security: diffusion model-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency through multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the first large-scale multimodal digital human forgery dataset based on diffusion models. Employing five latest digital human generation methods (Sonic, Hallo, etc.) and voice cloning method, we systematically produce a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies show that the confusion rate between forged and real videos reaches 68%, and existing state-of-the-art (SOTA) detection models exhibit large drops in AUC values on DigiFakeAV, highlighting the challenge of the dataset. To address this problem, we further propose DigiShield, a detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves SOTA performance on both the DigiFakeAV and DF-TIMIT datasets. Experiments show that this method effectively identifies covert artifacts through fine-grained analysis of the temporal evolution of facial features in synthetic videos.
Generative Iris Prior Embedded Transformer for Iris Restoration
Jun 28, 2024



Iris restoration from complexly degraded iris images, aiming to improve iris recognition performance, is a challenging problem. Due to the complex degradation, directly training a convolutional neural network (CNN) without prior cannot yield satisfactory results. In this work, we propose a generative iris prior embedded Transformer model (Gformer), in which we build a hierarchical encoder-decoder network employing Transformer block and generative iris prior. First, we tame Transformer blocks to model long-range dependencies in target images. Second, we pretrain an iris generative adversarial network (GAN) to obtain the rich iris prior, and incorporate it into the iris restoration process with our iris feature modulator. Our experiments demonstrate that the proposed Gformer outperforms state-of-the-art methods. Besides, iris recognition performance has been significantly improved after applying Gformer.
* Our code is available at https://github.com/sawyercharlton/Gformer
GIEBench: Towards Holistic Evaluation of Group Identity-based Empathy for Large Language Models
Jun 24, 2024



As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.