 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventPrune: Cascaded Event-Assisted Token Pruning for Efficient First-Person Dynamic Spatial Reasoning
May 19, 2026First-person dynamic spatial reasoning requires models to track continuous motion and precise geometric structure, but the quadratic attention cost of Transformer-based Video-LLMs makes dense visual tokens computationally expensive. Existing token pruning paradigms predominantly rely on discrete static snapshots, failing to preserve the motion and geometric cues essential for reasoning. We propose Event Cascade Pruning (ECP), to our knowledge the first training-free framework that leverages the high-frequency motion cues from event cameras as a continuous event-guided motion prior to guide token selection. ECP combines three stages: Event-Triggered Causal Sampling to anchor motion-informative keyframes, Event-guided Motion Saliency Filtering to suppress event-inactive visual tokens, and Event-Attention Ranking Fusion to calibrate spatial attention with motion-salient dynamics. With 80% visual token reduction, ECP outperforms the full-token baseline (37.62% vs. 36.31%) while achieving 1.89x inference speedup and 52% GFLOPs reduction. We further introduce ESR-Real, the first real-world RGB-event benchmark for first-person spatial reasoning, where ECP improves accuracy by 2.68 percentage points over full-token baselines.
$x^2$-Fusion: Cross-Modality and Cross-Dimension Flow Estimation in Event Edge Space
Mar 17, 2026Estimating dense 2D optical flow and 3D scene flow is essential for dynamic scene understanding. Recent work combines images, LiDAR, and event data to jointly predict 2D and 3D motion, yet most approaches operate in separate heterogeneous feature spaces. Without a shared latent space that all modalities can align to, these systems rely on multiple modality-specific blocks, leaving cross-sensor mismatches unresolved and making fusion unnecessarily complex.Event cameras naturally provide a spatiotemporal edge signal, which we can treat as an intrinsic edge field to anchor a unified latent representation, termed the Event Edge Space. Building on this idea, we introduce $x^2$-Fusion, which reframes multimodal fusion as representation unification: event-derived spatiotemporal edges define an edge-centric homogeneous space, and image and LiDAR features are explicitly aligned in this shared representation.Within this space, we perform reliability-aware adaptive fusion to estimate modality reliability and emphasize stable cues under degradation. We further employ cross-dimension contrast learning to tightly couple 2D optical flow with 3D scene flow. Extensive experiments on both synthetic and real benchmarks show that $x^2$-Fusion achieves state-of-the-art accuracy under standard conditions and delivers substantial improvements in challenging scenarios.
PRE-Mamba: A 4D State Space Model for Ultra-High-Frequent Event Camera Deraining
May 08, 2025Event cameras excel in high temporal resolution and dynamic range but suffer from dense noise in rainy conditions. Existing event deraining methods face trade-offs between temporal precision, deraining effectiveness, and computational efficiency. In this paper, we propose PRE-Mamba, a novel point-based event camera deraining framework that fully exploits the spatiotemporal characteristics of raw event and rain. Our framework introduces a 4D event cloud representation that integrates dual temporal scales to preserve high temporal precision, a Spatio-Temporal Decoupling and Fusion module (STDF) that enhances deraining capability by enabling shallow decoupling and interaction of temporal and spatial information, and a Multi-Scale State Space Model (MS3M) that captures deeper rain dynamics across dual-temporal and multi-spatial scales with linear computational complexity. Enhanced by frequency-domain regularization, PRE-Mamba achieves superior performance (0.95 SR, 0.91 NR, and 0.4s/M events) with only 0.26M parameters on EventRain-27K, a comprehensive dataset with labeled synthetic and real-world sequences. Moreover, our method generalizes well across varying rain intensities, viewpoints, and even snowy conditions.
EDmamba: A Simple yet Effective Event Denoising Method with State Space Model
May 08, 2025Event cameras excel in high-speed vision due to their high temporal resolution, high dynamic range, and low power consumption. However, as dynamic vision sensors, their output is inherently noisy, making efficient denoising essential to preserve their ultra-low latency and real-time processing capabilities. Existing event denoising methods struggle with a critical dilemma: computationally intensive approaches compromise the sensor's high-speed advantage, while lightweight methods often lack robustness across varying noise levels. To address this, we propose a novel event denoising framework based on State Space Models (SSMs). Our approach represents events as 4D event clouds and includes a Coarse Feature Extraction (CFE) module that extracts embedding features from both geometric and polarity-aware subspaces. The model is further composed of two essential components: A Spatial Mamba (S-SSM) that models local geometric structures and a Temporal Mamba (T-SSM) that captures global temporal dynamics, efficiently propagating spatiotemporal features across events. Experiments demonstrate that our method achieves state-of-the-art accuracy and efficiency, with 88.89K parameters, 0.0685s per 100K events inference time, and a 0.982 accuracy score, outperforming Transformer-based methods by 2.08% in denoising accuracy and 36X faster.
Towards Mobile Sensing with Event Cameras on High-mobility Resource-constrained Devices: A Survey
Mar 29, 2025With the increasing complexity of mobile device applications, these devices are evolving toward high mobility. This shift imposes new demands on mobile sensing, particularly in terms of achieving high accuracy and low latency. Event-based vision has emerged as a disruptive paradigm, offering high temporal resolution, low latency, and energy efficiency, making it well-suited for high-accuracy and low-latency sensing tasks on high-mobility platforms. However, the presence of substantial noisy events, the lack of inherent semantic information, and the large data volume pose significant challenges for event-based data processing on resource-constrained mobile devices. This paper surveys the literature over the period 2014-2024, provides a comprehensive overview of event-based mobile sensing systems, covering fundamental principles, event abstraction methods, algorithmic advancements, hardware and software acceleration strategies. We also discuss key applications of event cameras in mobile sensing, including visual odometry, object tracking, optical flow estimation, and 3D reconstruction, while highlighting the challenges associated with event data processing, sensor fusion, and real-time deployment. Furthermore, we outline future research directions, such as improving event camera hardware with advanced optics, leveraging neuromorphic computing for efficient processing, and integrating bio-inspired algorithms to enhance perception. To support ongoing research, we provide an open-source \textit{Online Sheet} with curated resources and recent developments. We hope this survey serves as a valuable reference, facilitating the adoption of event-based vision across diverse applications.
GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF
Oct 12, 2022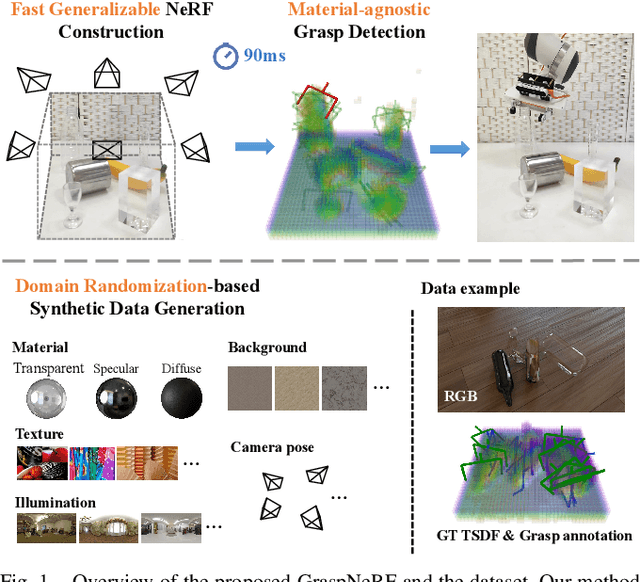
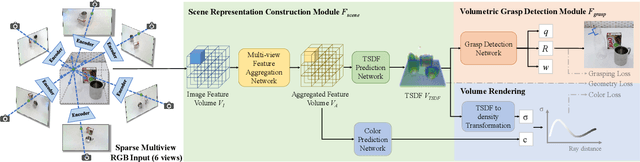
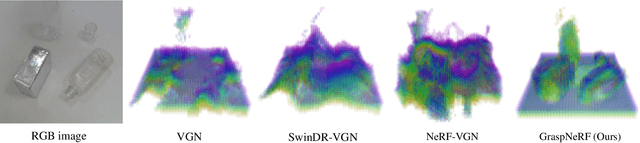
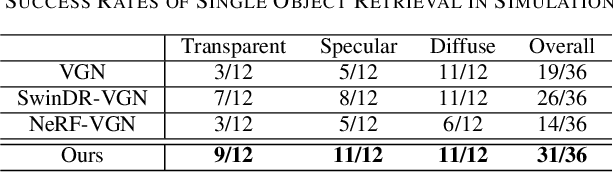
In this work, we tackle 6-DoF grasp detection for transparent and specular objects, which is an important yet challenging problem in vision-based robotic systems, due to the failure of depth cameras in sensing their geometry. We, for the first time, propose a multiview RGB-based 6-DoF grasp detection network, GraspNeRF, that leverages the generalizable neural radiance field (NeRF) to achieve material-agnostic object grasping in clutter. Compared to the existing NeRF-based 3-DoF grasp detection methods that rely on densely captured input images and time-consuming per-scene optimization, our system can perform zero-shot NeRF construction with sparse RGB inputs and reliably detect 6-DoF grasps, both in real-time. The proposed framework jointly learns generalizable NeRF and grasp detection in an end-to-end manner, optimizing the scene representation construction for the grasping. For training data, we generate a large-scale photorealistic domain-randomized synthetic dataset of grasping in cluttered tabletop scenes that enables direct transfer to the real world. Our extensive experiments in synthetic and real-world environments demonstrate that our method significantly outperforms all the baselines in all the experiments while remaining in real-time.