 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model
Nov 21, 2022



Large-scale Transformer models bring significant improvements for various downstream vision language tasks with a unified architecture. The performance improvements come with increasing model size, resulting in slow inference speed and increased cost for severing. While some certain predictions benefit from the full complexity of the large-scale model, not all of inputs need the same amount of computation to conduct, potentially leading to computation resource waste. To handle this challenge, early exiting is proposed to adaptively allocate computational power in term of input complexity to improve inference efficiency. The existing early exiting strategies usually adopt output confidence based on intermediate layers as a proxy of input complexity to incur the decision of skipping following layers. However, such strategies cannot apply to encoder in the widely-used unified architecture with both encoder and decoder due to difficulty of output confidence estimation in the encoder. It is suboptimal in term of saving computation power to ignore the early exiting in encoder component. To handle this challenge, we propose a novel early exiting strategy for unified visual language models, which allows dynamically skip the layers in encoder and decoder simultaneously in term of input layer-wise similarities with multiple times of early exiting, namely \textbf{MuE}. By decomposing the image and text modalities in the encoder, MuE is flexible and can skip different layers in term of modalities, advancing the inference efficiency while minimizing performance drop. Experiments on the SNLI-VE and MS COCO datasets show that the proposed approach MuE can reduce expected inference time by up to 50\% and 40\% while maintaining 99\% and 96\% performance respectively.
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training
Nov 19, 2022



Vision transformers (ViTs) have recently obtained success in many applications, but their intensive computation and heavy memory usage at both training and inference time limit their generalization. Previous compression algorithms usually start from the pre-trained dense models and only focus on efficient inference, while time-consuming training is still unavoidable. In contrast, this paper points out that the million-scale training data is redundant, which is the fundamental reason for the tedious training. To address the issue, this paper aims to introduce sparsity into data and proposes an end-to-end efficient training framework from three sparse perspectives, dubbed Tri-Level E-ViT. Specifically, we leverage a hierarchical data redundancy reduction scheme, by exploring the sparsity under three levels: number of training examples in the dataset, number of patches (tokens) in each example, and number of connections between tokens that lie in attention weights. With extensive experiments, we demonstrate that our proposed technique can noticeably accelerate training for various ViT architectures while maintaining accuracy. Remarkably, under certain ratios, we are able to improve the ViT accuracy rather than compromising it. For example, we can achieve 15.2% speedup with 72.6% (+0.4) Top-1 accuracy on Deit-T, and 15.7% speedup with 79.9% (+0.1) Top-1 accuracy on Deit-S. This proves the existence of data redundancy in ViT.
HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers
Nov 15, 2022



While vision transformers (ViTs) have continuously achieved new milestones in the field of computer vision, their sophisticated network architectures with high computation and memory costs have impeded their deployment on resource-limited edge devices. In this paper, we propose a hardware-efficient image-adaptive token pruning framework called HeatViT for efficient yet accurate ViT acceleration on embedded FPGAs. By analyzing the inherent computational patterns in ViTs, we first design an effective attention-based multi-head token selector, which can be progressively inserted before transformer blocks to dynamically identify and consolidate the non-informative tokens from input images. Moreover, we implement the token selector on hardware by adding miniature control logic to heavily reuse existing hardware components built for the backbone ViT. To improve the hardware efficiency, we further employ 8-bit fixed-point quantization, and propose polynomial approximations with regularization effect on quantization error for the frequently used nonlinear functions in ViTs. Finally, we propose a latency-aware multi-stage training strategy to determine the transformer blocks for inserting token selectors and optimize the desired (average) pruning rates for inserted token selectors, in order to improve both the model accuracy and inference latency on hardware. Compared to existing ViT pruning studies, under the similar computation cost, HeatViT can achieve 0.7%$\sim$8.9% higher accuracy; while under the similar model accuracy, HeatViT can achieve more than 28.4%$\sim$65.3% computation reduction, for various widely used ViTs, including DeiT-T, DeiT-S, DeiT-B, LV-ViT-S, and LV-ViT-M, on the ImageNet dataset. Compared to the baseline hardware accelerator, our implementations of HeatViT on the Xilinx ZCU102 FPGA achieve 3.46$\times$$\sim$4.89$\times$ speedup.
The Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022



The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.
Advancing Model Pruning via Bi-level Optimization
Oct 12, 2022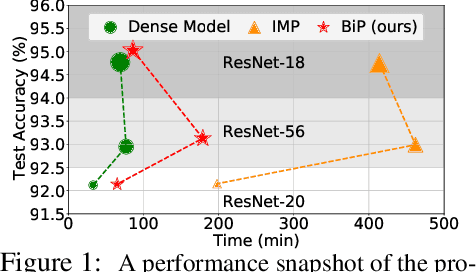
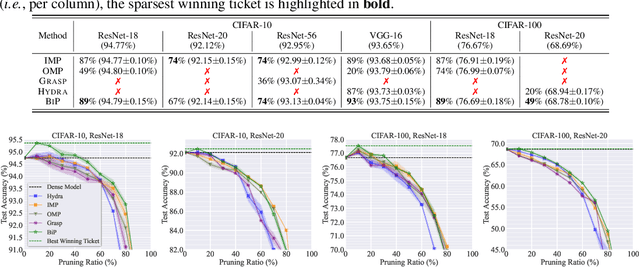
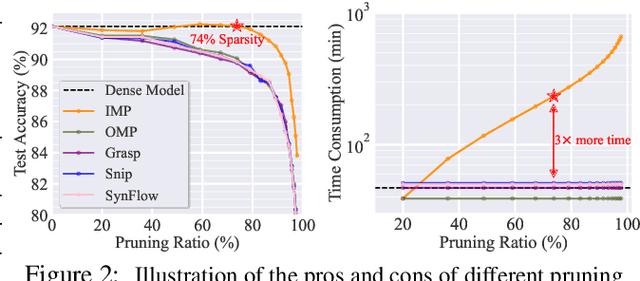
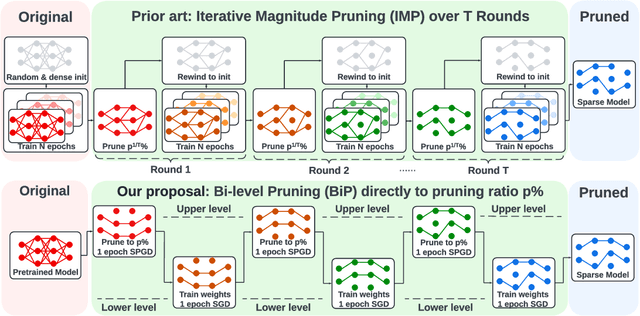
The deployment constraints in practical applications necessitate the pruning of large-scale deep learning models, i.e., promoting their weight sparsity. As illustrated by the Lottery Ticket Hypothesis (LTH), pruning also has the potential of improving their generalization ability. At the core of LTH, iterative magnitude pruning (IMP) is the predominant pruning method to successfully find 'winning tickets'. Yet, the computation cost of IMP grows prohibitively as the targeted pruning ratio increases. To reduce the computation overhead, various efficient 'one-shot' pruning methods have been developed, but these schemes are usually unable to find winning tickets as good as IMP. This raises the question of how to close the gap between pruning accuracy and pruning efficiency? To tackle it, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BiP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BiP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. Through extensive experiments on both structured and unstructured pruning with 5 model architectures and 4 data sets, we demonstrate that BiP can find better winning tickets than IMP in most cases, and is computationally as efficient as the one-shot pruning schemes, demonstrating 2-7 times speedup over IMP for the same level of model accuracy and sparsity.
Pruning Adversarially Robust Neural Networks without Adversarial Examples
Oct 09, 2022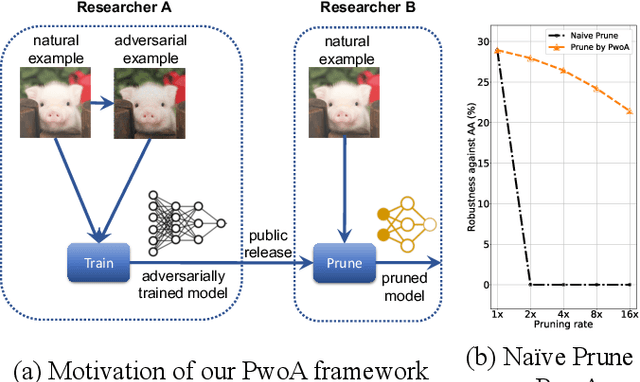
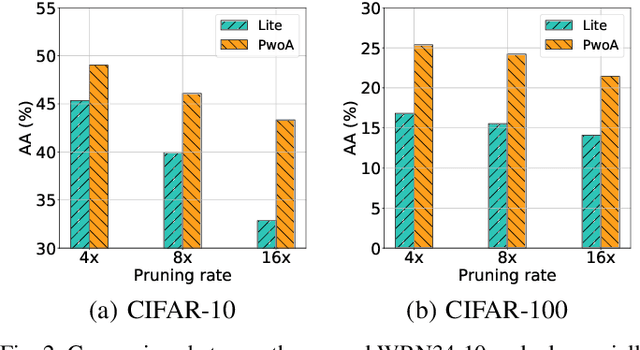
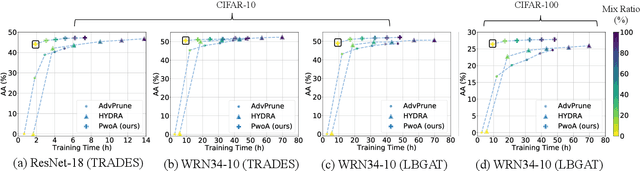
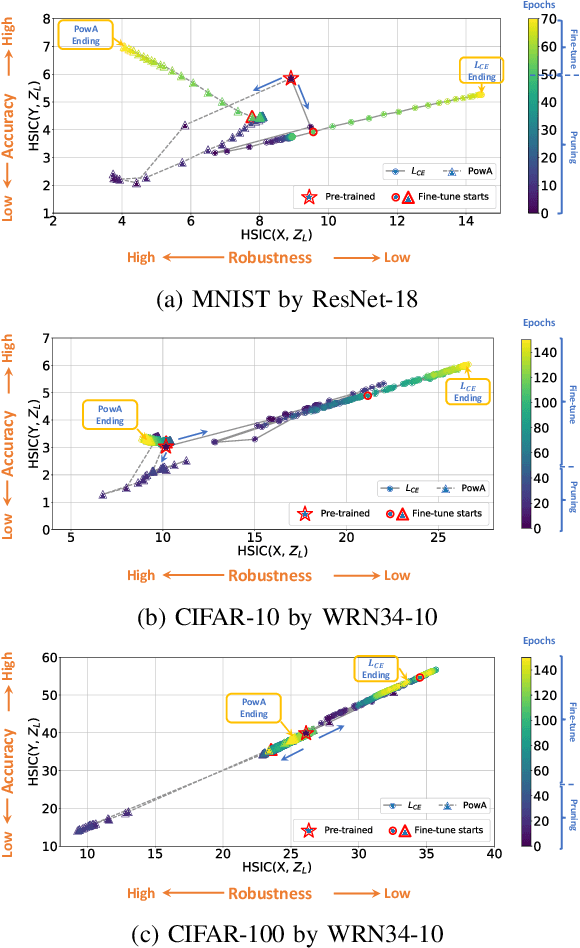
Adversarial pruning compresses models while preserving robustness. Current methods require access to adversarial examples during pruning. This significantly hampers training efficiency. Moreover, as new adversarial attacks and training methods develop at a rapid rate, adversarial pruning methods need to be modified accordingly to keep up. In this work, we propose a novel framework to prune a previously trained robust neural network while maintaining adversarial robustness, without further generating adversarial examples. We leverage concurrent self-distillation and pruning to preserve knowledge in the original model as well as regularizing the pruned model via the Hilbert-Schmidt Information Bottleneck. We comprehensively evaluate our proposed framework and show its superior performance in terms of both adversarial robustness and efficiency when pruning architectures trained on the MNIST, CIFAR-10, and CIFAR-100 datasets against five state-of-the-art attacks. Code is available at https://github.com/neu-spiral/PwoA/.
Layer Freezing & Data Sieving: Missing Pieces of a Generic Framework for Sparse Training
Sep 22, 2022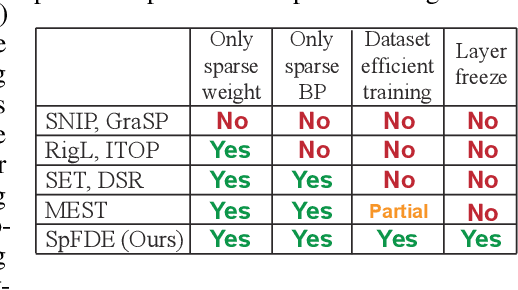
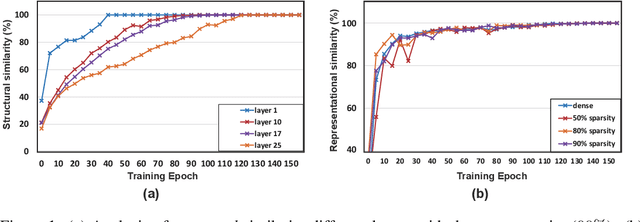
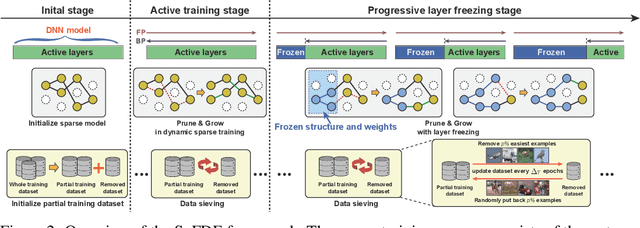
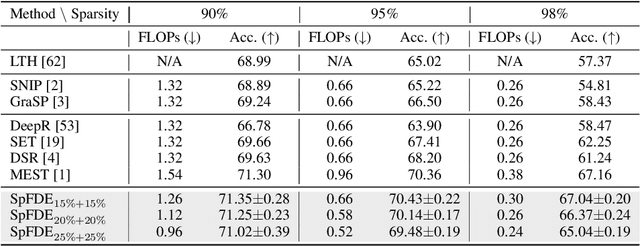
Recently, sparse training has emerged as a promising paradigm for efficient deep learning on edge devices. The current research mainly devotes efforts to reducing training costs by further increasing model sparsity. However, increasing sparsity is not always ideal since it will inevitably introduce severe accuracy degradation at an extremely high sparsity level. This paper intends to explore other possible directions to effectively and efficiently reduce sparse training costs while preserving accuracy. To this end, we investigate two techniques, namely, layer freezing and data sieving. First, the layer freezing approach has shown its success in dense model training and fine-tuning, yet it has never been adopted in the sparse training domain. Nevertheless, the unique characteristics of sparse training may hinder the incorporation of layer freezing techniques. Therefore, we analyze the feasibility and potentiality of using the layer freezing technique in sparse training and find it has the potential to save considerable training costs. Second, we propose a data sieving method for dataset-efficient training, which further reduces training costs by ensuring only a partial dataset is used throughout the entire training process. We show that both techniques can be well incorporated into the sparse training algorithm to form a generic framework, which we dub SpFDE. Our extensive experiments demonstrate that SpFDE can significantly reduce training costs while preserving accuracy from three dimensions: weight sparsity, layer freezing, and dataset sieving.
SparCL: Sparse Continual Learning on the Edge
Sep 20, 2022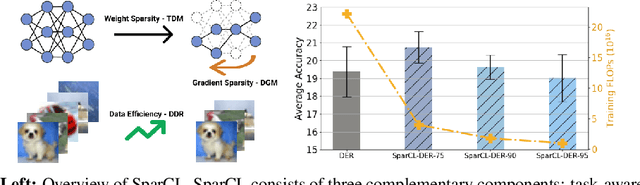
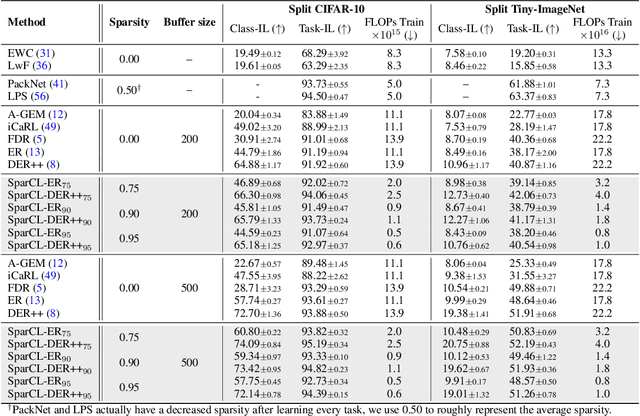
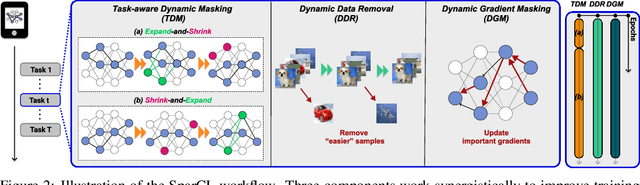
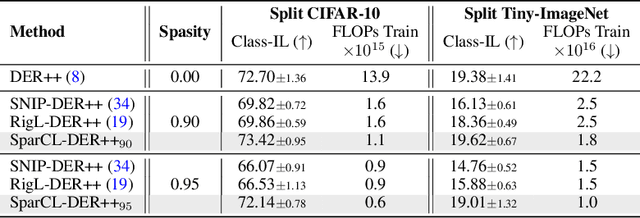
Existing work in continual learning (CL) focuses on mitigating catastrophic forgetting, i.e., model performance deterioration on past tasks when learning a new task. However, the training efficiency of a CL system is under-investigated, which limits the real-world application of CL systems under resource-limited scenarios. In this work, we propose a novel framework called Sparse Continual Learning(SparCL), which is the first study that leverages sparsity to enable cost-effective continual learning on edge devices. SparCL achieves both training acceleration and accuracy preservation through the synergy of three aspects: weight sparsity, data efficiency, and gradient sparsity. Specifically, we propose task-aware dynamic masking (TDM) to learn a sparse network throughout the entire CL process, dynamic data removal (DDR) to remove less informative training data, and dynamic gradient masking (DGM) to sparsify the gradient updates. Each of them not only improves efficiency, but also further mitigates catastrophic forgetting. SparCL consistently improves the training efficiency of existing state-of-the-art (SOTA) CL methods by at most 23X less training FLOPs, and, surprisingly, further improves the SOTA accuracy by at most 1.7%. SparCL also outperforms competitive baselines obtained from adapting SOTA sparse training methods to the CL setting in both efficiency and accuracy. We also evaluate the effectiveness of SparCL on a real mobile phone, further indicating the practical potential of our method.
PIM-QAT: Neural Network Quantization for Processing-In-Memory (PIM) Systems
Sep 18, 2022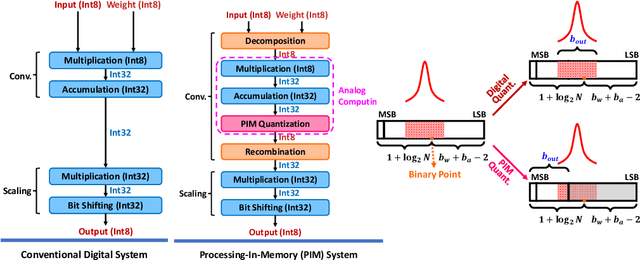

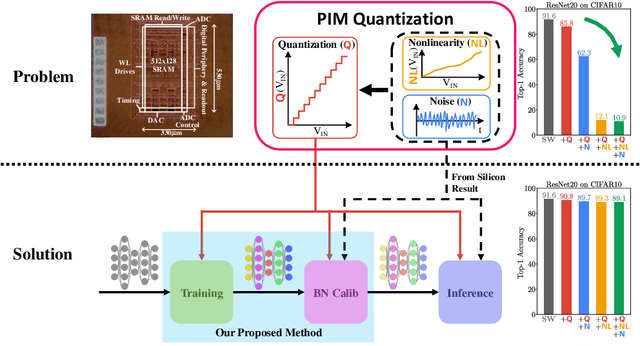

Processing-in-memory (PIM), an increasingly studied neuromorphic hardware, promises orders of energy and throughput improvements for deep learning inference. Leveraging the massively parallel and efficient analog computing inside memories, PIM circumvents the bottlenecks of data movements in conventional digital hardware. However, an extra quantization step (i.e. PIM quantization), typically with limited resolution due to hardware constraints, is required to convert the analog computing results into digital domain. Meanwhile, non-ideal effects extensively exist in PIM quantization because of the imperfect analog-to-digital interface, which further compromises the inference accuracy. In this paper, we propose a method for training quantized networks to incorporate PIM quantization, which is ubiquitous to all PIM systems. Specifically, we propose a PIM quantization aware training (PIM-QAT) algorithm, and introduce rescaling techniques during backward and forward propagation by analyzing the training dynamics to facilitate training convergence. We also propose two techniques, namely batch normalization (BN) calibration and adjusted precision training, to suppress the adverse effects of non-ideal linearity and stochastic thermal noise involved in real PIM chips. Our method is validated on three mainstream PIM decomposition schemes, and physically on a prototype chip. Comparing with directly deploying conventionally trained quantized model on PIM systems, which does not take into account this extra quantization step and thus fails, our method provides significant improvement. It also achieves comparable inference accuracy on PIM systems as that of conventionally quantized models on digital hardware, across CIFAR10 and CIFAR100 datasets using various network depths for the most popular network topology.
StereoVoxelNet: Real-Time Obstacle Detection Based on Occupancy Voxels from a Stereo Camera Using Deep Neural Networks
Sep 18, 2022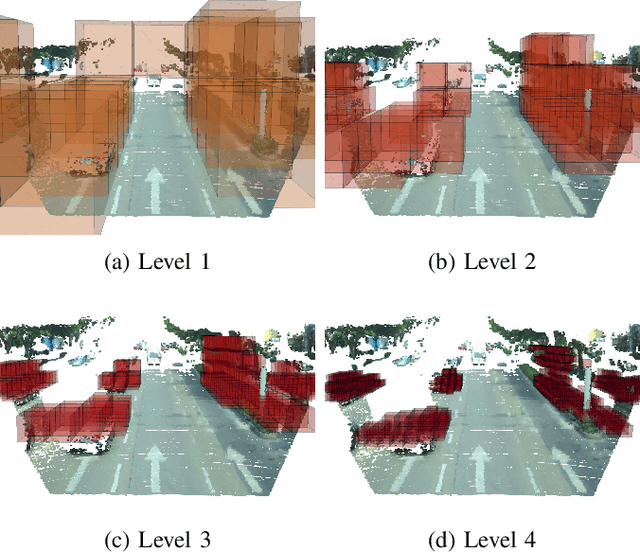

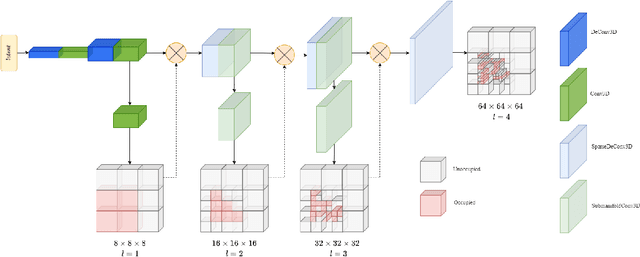

Obstacle detection is a safety-critical problem in robot navigation, where stereo matching is a popular vision-based approach. While deep neural networks have shown impressive results in computer vision, most of the previous obstacle detection works only leverage traditional stereo matching techniques to meet the computational constraints for real-time feedback. This paper proposes a computationally efficient method that leverages a deep neural network to detect occupancy from stereo images directly. Instead of learning the point cloud correspondence from the stereo data, our approach extracts the compact obstacle distribution based on volumetric representations. In addition, we prune the computation of safety irrelevant spaces in a coarse-to-fine manner based on octrees generated by the decoder. As a result, we achieve real-time performance on the onboard computer (NVIDIA Jetson TX2). Our approach detects obstacles accurately in the range of 32 meters and achieves better IoU (Intersection over Union) and CD (Chamfer Distance) scores with only 2% of the computation cost of the state-of-the-art stereo model. Furthermore, we validate our method's robustness and real-world feasibility through autonomous navigation experiments with a real robot. Hence, our work contributes toward closing the gap between the stereo-based system in robot perception and state-of-the-art stereo models in computer vision. To counter the scarcity of high-quality real-world indoor stereo datasets, we collect a 1.36 hours stereo dataset with a Jackal robot which is used to fine-tune our model. The dataset, the code, and more visualizations are available at https://lhy.xyz/stereovoxelnet/