 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGENTCL: Toward Rigorous Evaluation of Continual Learning in Language Agents
Jun 01, 2026Language agents spend substantial inference time solving individual tasks, yet the experience acquired in one episode is often underutilized in future episodes. Continual learning expects an agent to accumulate reusable experience across a stream of tasks, improve over time, and avoid interference from irrelevant experiences. Unfortunately, existing benchmarks struggle to evaluate continual learning in language agents rigorously. Most efforts focus on retrieval and reasoning over long-context conversations or documents, while recent lifelong-adaptation benchmarks often rely on naive task streams with limited analysis of cross-task relationships, making it difficult to understand what an agent learns and reuses over time. This paper presents an evaluation framework AgentCL for continual learning in agents, centered on controlled task streams and metrics for transfer gains. AGENTCL constructs compositional streams where earlier sub-solutions, evidence, or workflows are intentionally reusable in later tasks, and contrasts them with naive streams where such reusability is not guaranteed. We use the benchmark to evaluate non-parametric memory designs for continual learning. To diagnose how memory design choices affect continual learning, we develop MemProbe, a probing method that stores interactions, insights, and skills, while filtering unreliable experiences during consolidation. Empirical analysis across coding, deep research, and language understanding/reasoning tasks shows that naive streams offer limited ability to distinguish memory designs, whereas controlled streams more clearly distinguish their plasticity. Meanwhile, naive and held-out settings often yield limited gains and can expose memory-induced degradation. These results highlight the need for stronger memory designs that balance plasticity and stable reuse.
Visual prompting reimagined: The power of the Activation Prompts
Apr 07, 2026Visual prompting (VP) has emerged as a popular method to repurpose pretrained vision models for adaptation to downstream tasks. Unlike conventional model fine-tuning techniques, VP introduces a universal perturbation directly into the input data to facilitate task-specific fine-tuning rather than modifying model parameters. However, there exists a noticeable performance gap between VP and conventional fine-tuning methods, highlighting an unexplored realm in theory and practice to understand and advance the input-level VP to reduce its current performance gap. Towards this end, we introduce a generalized concept, termed activation prompt (AP), which extends the scope of the input-level VP by enabling universal perturbations to be applied to activation maps within the intermediate layers of the model. By using AP to revisit the problem of VP and employing it as an analytical tool, we demonstrate the intrinsic limitations of VP in both performance and efficiency, revealing why input-level prompting may lack effectiveness compared to AP, which exhibits a model-dependent layer preference. We show that AP is closely related to normalization tuning in convolutional neural networks and vision transformers, although each model type has distinct layer preferences for prompting. We also theoretically elucidate the rationale behind such a preference by analyzing global features across layers. Through extensive experiments across 29 datasets and various model architectures, we provide a comprehensive performance analysis of AP, comparing it with VP and parameter-efficient fine-tuning baselines. Our results demonstrate AP's superiority in both accuracy and efficiency, considering factors such as time, parameters, memory usage, and throughput.
Jailbreaks on Vision Language Model via Multimodal Reasoning
Jan 29, 2026Vision-language models (VLMs) have become central to tasks such as visual question answering, image captioning, and text-to-image generation. However, their outputs are highly sensitive to prompt variations, which can reveal vulnerabilities in safety alignment. In this work, we present a jailbreak framework that exploits post-training Chain-of-Thought (CoT) prompting to construct stealthy prompts capable of bypassing safety filters. To further increase attack success rates (ASR), we propose a ReAct-driven adaptive noising mechanism that iteratively perturbs input images based on model feedback. This approach leverages the ReAct paradigm to refine adversarial noise in regions most likely to activate safety defenses, thereby enhancing stealth and evasion. Experimental results demonstrate that the proposed dual-strategy significantly improves ASR while maintaining naturalness in both text and visual domains.
ToolPRMBench: Evaluating and Advancing Process Reward Models for Tool-using Agents
Jan 18, 2026Reward-guided search methods have demonstrated strong potential in enhancing tool-using agents by effectively guiding sampling and exploration over complex action spaces. As a core design, those search methods utilize process reward models (PRMs) to provide step-level rewards, enabling more fine-grained monitoring. However, there is a lack of systematic and reliable evaluation benchmarks for PRMs in tool-using settings. In this paper, we introduce ToolPRMBench, a large-scale benchmark specifically designed to evaluate PRMs for tool-using agents. ToolPRMBench is built on top of several representative tool-using benchmarks and converts agent trajectories into step-level test cases. Each case contains the interaction history, a correct action, a plausible but incorrect alternative, and relevant tool metadata. We respectively utilize offline sampling to isolate local single-step errors and online sampling to capture realistic multi-step failures from full agent rollouts. A multi-LLM verification pipeline is proposed to reduce label noise and ensure data quality. We conduct extensive experiments across large language models, general PRMs, and tool-specialized PRMs on ToolPRMBench. The results reveal clear differences in PRM effectiveness and highlight the potential of specialized PRMs for tool-using. Code and data will be released at https://github.com/David-Li0406/ToolPRMBench.
RIMRULE: Improving Tool-Using Language Agents via MDL-Guided Rule Learning
Jan 05, 2026Large language models (LLMs) often struggle to use tools reliably in domain-specific settings, where APIs may be idiosyncratic, under-documented, or tailored to private workflows. This highlights the need for effective adaptation to task-specific tools. We propose RIMRULE, a neuro-symbolic approach for LLM adaptation based on dynamic rule injection. Compact, interpretable rules are distilled from failure traces and injected into the prompt during inference to improve task performance. These rules are proposed by the LLM itself and consolidated using a Minimum Description Length (MDL) objective that favors generality and conciseness. Each rule is stored in both natural language and a structured symbolic form, supporting efficient retrieval at inference time. Experiments on tool-use benchmarks show that this approach improves accuracy on both seen and unseen tools without modifying LLM weights. It outperforms prompting-based adaptation methods and complements finetuning. Moreover, rules learned from one LLM can be reused to improve others, including long reasoning LLMs, highlighting the portability of symbolic knowledge across architectures.
SuperFlow: Training Flow Matching Models with RL on the Fly
Dec 17, 2025Recent progress in flow-based generative models and reinforcement learning (RL) has improved text-image alignment and visual quality. However, current RL training for flow models still has two main problems: (i) GRPO-style fixed per-prompt group sizes ignore variation in sampling importance across prompts, which leads to inefficient sampling and slower training; and (ii) trajectory-level advantages are reused as per-step estimates, which biases credit assignment along the flow. We propose SuperFlow, an RL training framework for flow-based models that adjusts group sizes with variance-aware sampling and computes step-level advantages in a way that is consistent with continuous-time flow dynamics. Empirically, SuperFlow reaches promising performance while using only 5.4% to 56.3% of the original training steps and reduces training time by 5.2% to 16.7% without any architectural changes. On standard text-to-image (T2I) tasks, including text rendering, compositional image generation, and human preference alignment, SuperFlow improves over SD3.5-M by 4.6% to 47.2%, and over Flow-GRPO by 1.7% to 16.0%.
LaTtE-Flow: Layerwise Timestep-Expert Flow-based Transformer
Jun 08, 2025Recent advances in multimodal foundation models unifying image understanding and generation have opened exciting avenues for tackling a wide range of vision-language tasks within a single framework. Despite progress, existing unified models typically require extensive pretraining and struggle to achieve the same level of performance compared to models dedicated to each task. Additionally, many of these models suffer from slow image generation speeds, limiting their practical deployment in real-time or resource-constrained settings. In this work, we propose Layerwise Timestep-Expert Flow-based Transformer (LaTtE-Flow), a novel and efficient architecture that unifies image understanding and generation within a single multimodal model. LaTtE-Flow builds upon powerful pretrained Vision-Language Models (VLMs) to inherit strong multimodal understanding capabilities, and extends them with a novel Layerwise Timestep Experts flow-based architecture for efficient image generation. LaTtE-Flow distributes the flow-matching process across specialized groups of Transformer layers, each responsible for a distinct subset of timesteps. This design significantly improves sampling efficiency by activating only a small subset of layers at each sampling timestep. To further enhance performance, we propose a Timestep-Conditioned Residual Attention mechanism for efficient information reuse across layers. Experiments demonstrate that LaTtE-Flow achieves strong performance on multimodal understanding tasks, while achieving competitive image generation quality with around 6x faster inference speed compared to recent unified multimodal models.
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

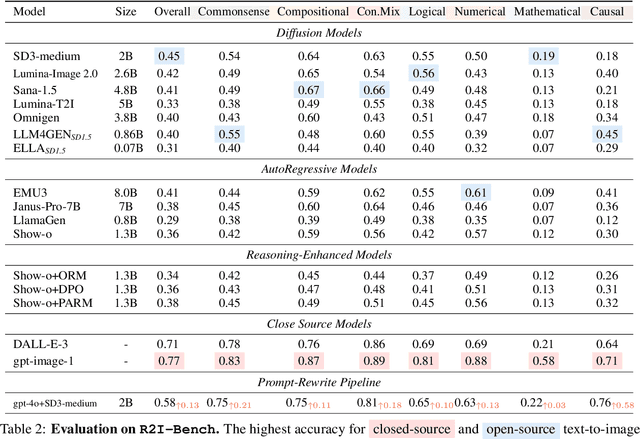

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
Safety Mirage: How Spurious Correlations Undermine VLM Safety Fine-tuning
Mar 14, 2025Recent vision-language models (VLMs) have made remarkable strides in generative modeling with multimodal inputs, particularly text and images. However, their susceptibility to generating harmful content when exposed to unsafe queries raises critical safety concerns. While current alignment strategies primarily rely on supervised safety fine-tuning with curated datasets, we identify a fundamental limitation we call the "safety mirage" where supervised fine-tuning inadvertently reinforces spurious correlations between superficial textual patterns and safety responses, rather than fostering deep, intrinsic mitigation of harm. We show that these spurious correlations leave fine-tuned VLMs vulnerable even to a simple one-word modification-based attack, where substituting a single word in text queries with a spurious correlation-inducing alternative can effectively bypass safeguards. Additionally, these correlations contribute to the over prudence, causing fine-tuned VLMs to refuse benign queries unnecessarily. To address this issue, we show machine unlearning (MU) as a powerful alternative to supervised safety fine-tuning as it avoids biased feature-label mappings and directly removes harmful knowledge from VLMs while preserving their general capabilities. Extensive evaluations across safety benchmarks show that under one-word attacks, MU-based alignment reduces the attack success rate by up to 60.17% and cuts unnecessary rejections by over 84.20%. Codes are available at https://github.com/OPTML-Group/VLM-Safety-MU. WARNING: There exist AI generations that may be offensive in nature.
FairSkin: Fair Diffusion for Skin Disease Image Generation
Oct 31, 2024



Image generation is a prevailing technique for clinical data augmentation for advancing diagnostic accuracy and reducing healthcare disparities. Diffusion Model (DM) has become a leading method in generating synthetic medical images, but it suffers from a critical twofold bias: (1) The quality of images generated for Caucasian individuals is significantly higher, as measured by the Frechet Inception Distance (FID). (2) The ability of the downstream-task learner to learn critical features from disease images varies across different skin tones. These biases pose significant risks, particularly in skin disease detection, where underrepresentation of certain skin tones can lead to misdiagnosis or neglect of specific conditions. To address these challenges, we propose FairSkin, a novel DM framework that mitigates these biases through a three-level resampling mechanism, ensuring fairer representation across racial and disease categories. Our approach significantly improves the diversity and quality of generated images, contributing to more equitable skin disease detection in clinical settings.