 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Model Sparsification by Scheduled Grow-and-Prune Methods
Jun 18, 2021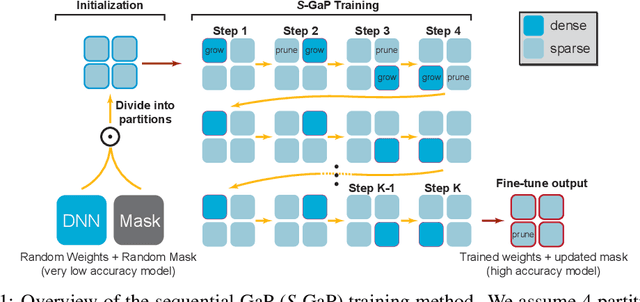

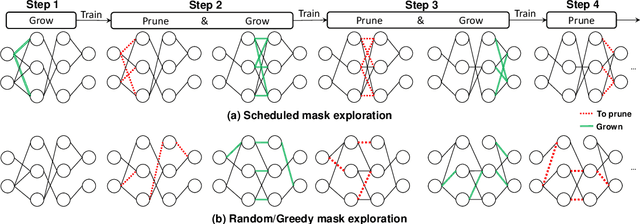
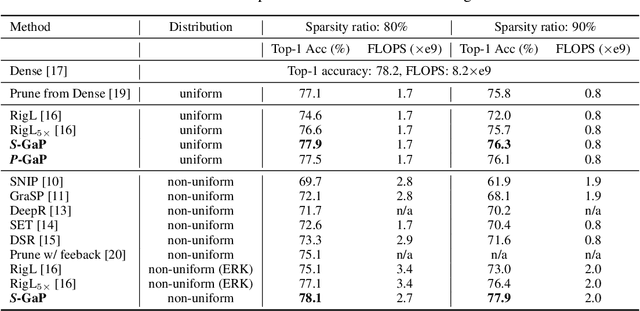
Deep neural networks (DNNs) are effective in solving many real-world problems. Larger DNN models usually exhibit better quality (e.g., accuracy) but their excessive computation results in long training and inference time. Model sparsification can reduce the computation and memory cost while maintaining model quality. Most existing sparsification algorithms unidirectionally remove weights, while others randomly or greedily explore a small subset of weights in each layer. The inefficiency of the algorithms reduces the achievable sparsity level. In addition, many algorithms still require pre-trained dense models and thus suffer from large memory footprint and long training time. In this paper, we propose a novel scheduled grow-and-prune (GaP) methodology without pre-training the dense models. It addresses the shortcomings of the previous works by repeatedly growing a subset of layers to dense and then pruning back to sparse after some training. Experiments have shown that such models can match or beat the quality of highly optimized dense models at 80% sparsity on a variety of tasks, such as image classification, objective detection, 3D object part segmentation, and translation. They also outperform other state-of-the-art (SOTA) pruning methods, including pruning from pre-trained dense models. As an example, a 90% sparse ResNet-50 obtained via GaP achieves 77.9% top-1 accuracy on ImageNet, improving the SOTA results by 1.5%.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021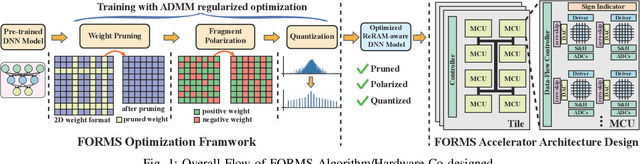
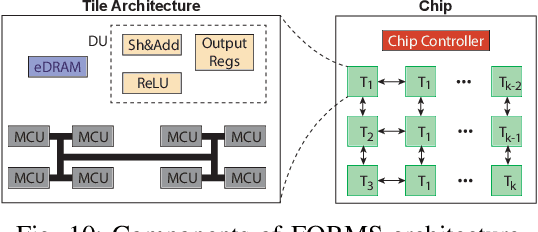
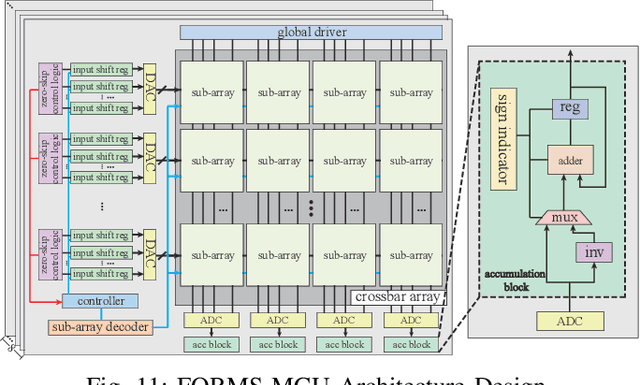

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.
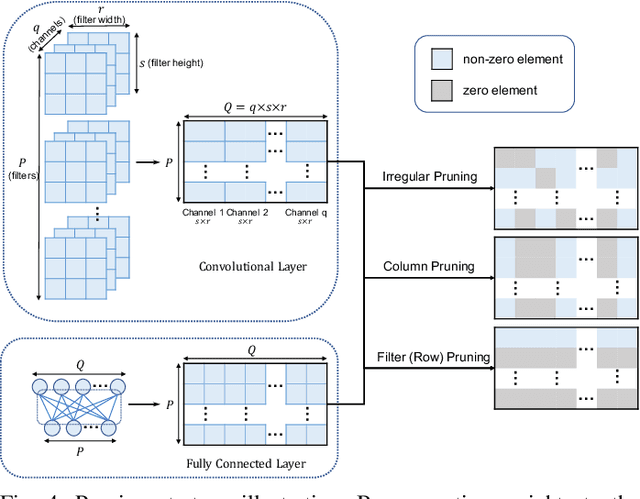
Efficient Micro-Structured Weight Unification and Pruning for Neural Network Compression
Jun 16, 2021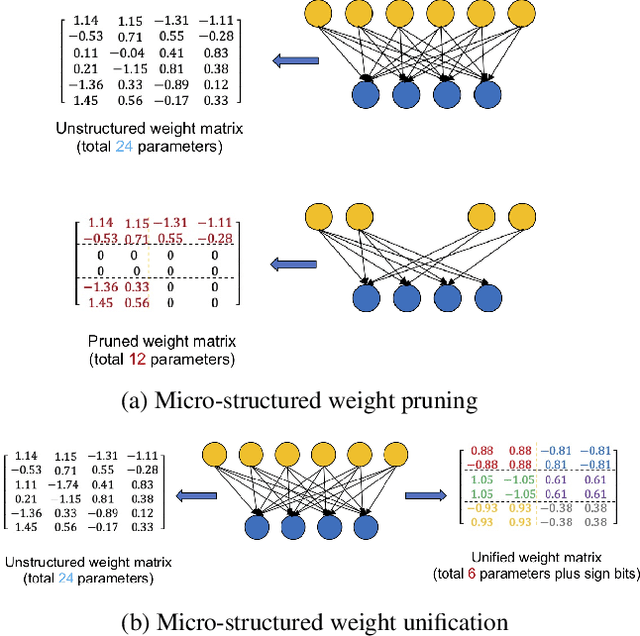

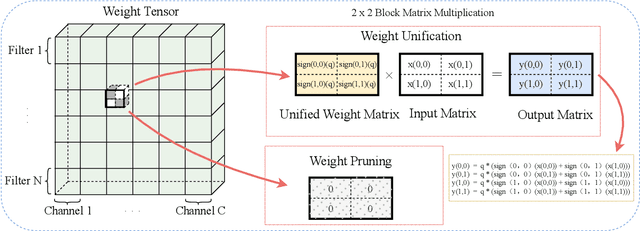
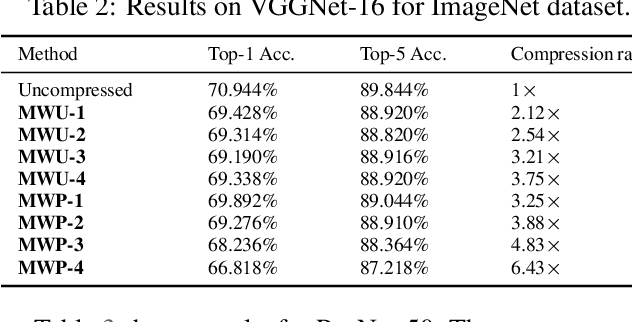
Compressing Deep Neural Network (DNN) models to alleviate the storage and computation requirements is essential for practical applications, especially for resource limited devices. Although capable of reducing a reasonable amount of model parameters, previous unstructured or structured weight pruning methods can hardly truly accelerate inference, either due to the poor hardware compatibility of the unstructured sparsity or due to the low sparse rate of the structurally pruned network. Aiming at reducing both storage and computation, as well as preserving the original task performance, we propose a generalized weight unification framework at a hardware compatible micro-structured level to achieve high amount of compression and acceleration. Weight coefficients of a selected micro-structured block are unified to reduce the storage and computation of the block without changing the neuron connections, which turns to a micro-structured pruning special case when all unified coefficients are set to zero, where neuron connections (hence storage and computation) are completely removed. In addition, we developed an effective training framework based on the alternating direction method of multipliers (ADMM), which converts our complex constrained optimization into separately solvable subproblems. Through iteratively optimizing the subproblems, the desired micro-structure can be ensured with high compression ratio and low performance degradation. We extensively evaluated our method using a variety of benchmark models and datasets for different applications. Experimental results demonstrate state-of-the-art performance.
Towards Fast and Accurate Multi-Person Pose Estimation on Mobile Devices
Jun 06, 2021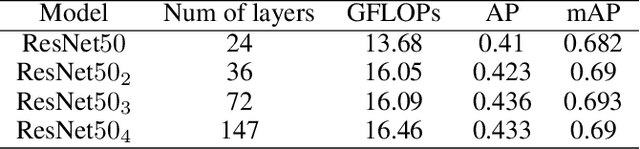


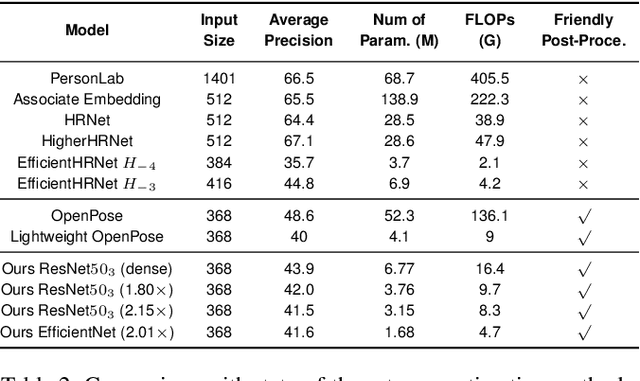
The rapid development of autonomous driving, abnormal behavior detection, and behavior recognition makes an increasing demand for multi-person pose estimation-based applications, especially on mobile platforms. However, to achieve high accuracy, state-of-the-art methods tend to have a large model size and complex post-processing algorithm, which costs intense computation and long end-to-end latency. To solve this problem, we propose an architecture optimization and weight pruning framework to accelerate inference of multi-person pose estimation on mobile devices. With our optimization framework, we achieve up to 2.51x faster model inference speed with higher accuracy compared to representative lightweight multi-person pose estimator.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
Jun 06, 2021


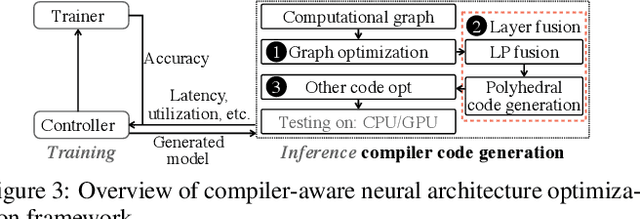
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
Teachers Do More Than Teach: Compressing Image-to-Image Models
Mar 05, 2021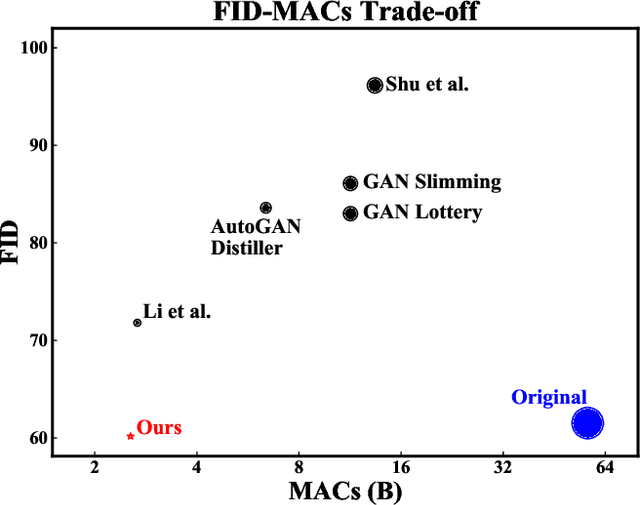
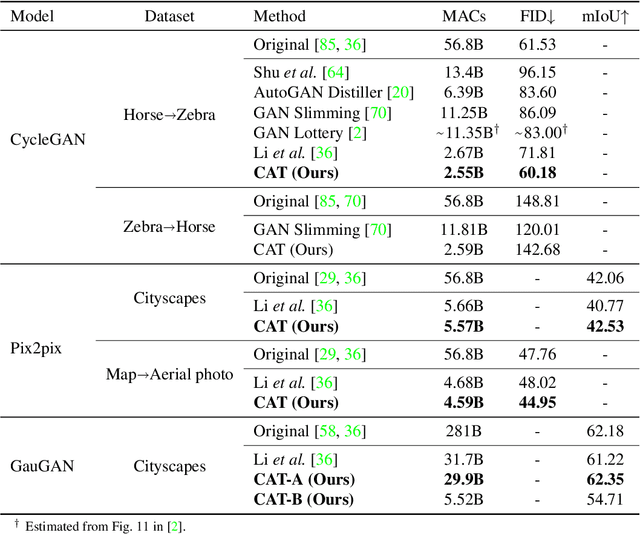
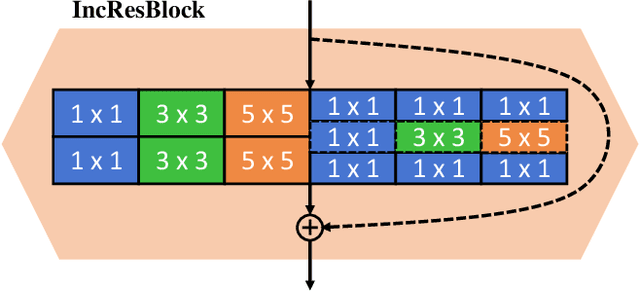
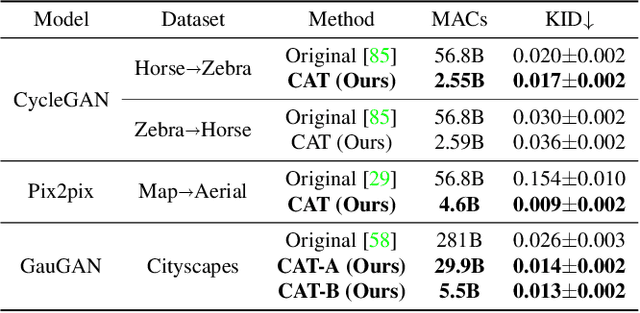
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process. In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no l1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via an index named Global Kernel Alignment (GKA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs. Code will be released at https://github.com/snap-research/CAT.
Lottery Ticket Implies Accuracy Degradation, Is It a Desirable Phenomenon?
Feb 19, 2021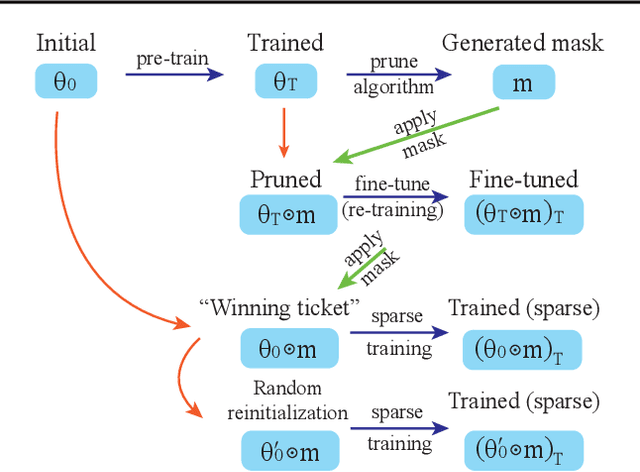
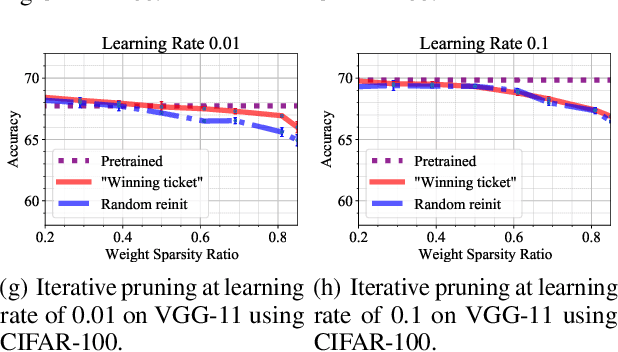
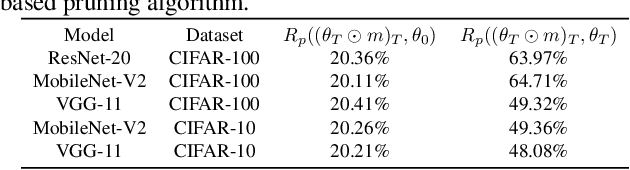
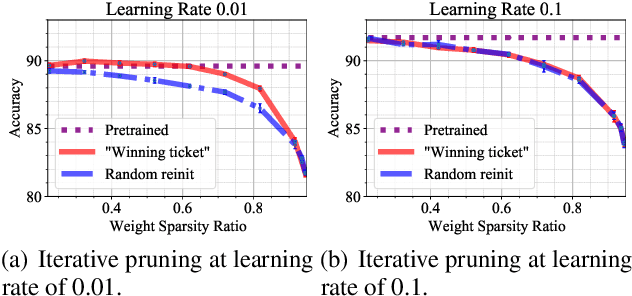
In deep model compression, the recent finding "Lottery Ticket Hypothesis" (LTH) (Frankle & Carbin, 2018) pointed out that there could exist a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance than the original dense network. However, it is not easy to observe such winning property in many scenarios, where for example, a relatively large learning rate is used even if it benefits training the original dense model. In this work, we investigate the underlying condition and rationale behind the winning property, and find that the underlying reason is largely attributed to the correlation between initialized weights and final-trained weights when the learning rate is not sufficiently large. Thus, the existence of winning property is correlated with an insufficient DNN pretraining, and is unlikely to occur for a well-trained DNN. To overcome this limitation, we propose the "pruning & fine-tuning" method that consistently outperforms lottery ticket sparse training under the same pruning algorithm and the same total training epochs. Extensive experiments over multiple deep models (VGG, ResNet, MobileNet-v2) on different datasets have been conducted to justify our proposals.
Achieving Real-Time LiDAR 3D Object Detection on a Mobile Device
Dec 26, 2020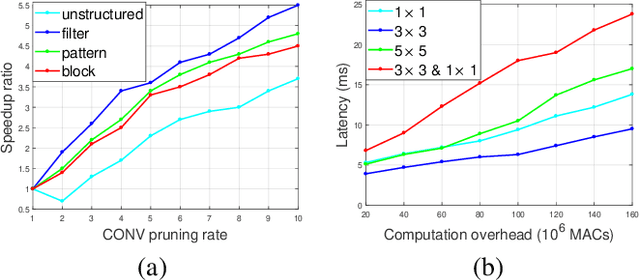
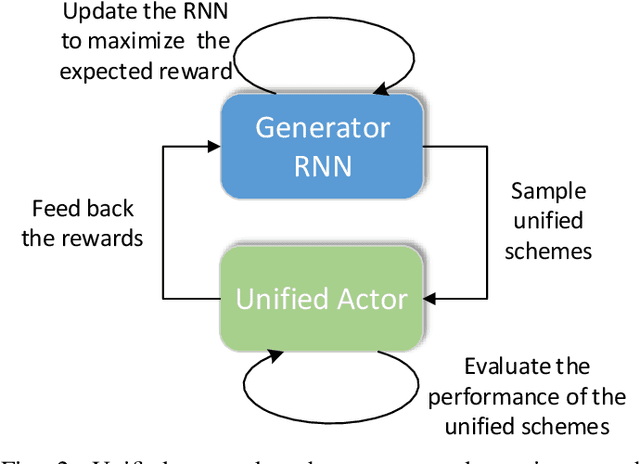
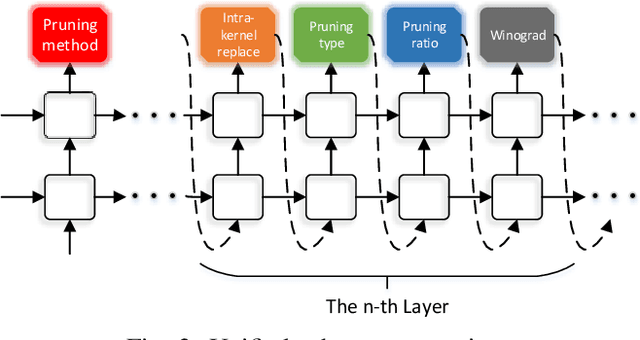

3D object detection is an important task, especially in the autonomous driving application domain. However, it is challenging to support the real-time performance with the limited computation and memory resources on edge-computing devices in self-driving cars. To achieve this, we propose a compiler-aware unified framework incorporating network enhancement and pruning search with the reinforcement learning techniques, to enable real-time inference of 3D object detection on the resource-limited edge-computing devices. Specifically, a generator Recurrent Neural Network (RNN) is employed to provide the unified scheme for both network enhancement and pruning search automatically, without human expertise and assistance. And the evaluated performance of the unified schemes can be fed back to train the generator RNN. The experimental results demonstrate that the proposed framework firstly achieves real-time 3D object detection on mobile devices (Samsung Galaxy S20 phone) with competitive detection performance.
Learn-Prune-Share for Lifelong Learning
Dec 13, 2020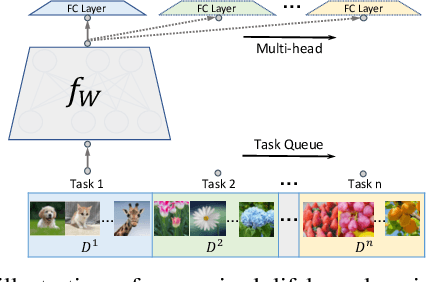
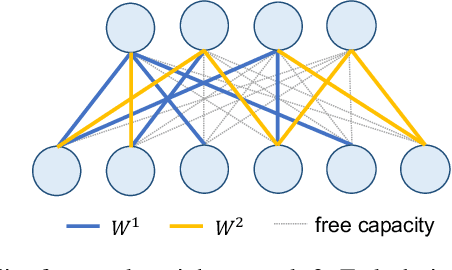
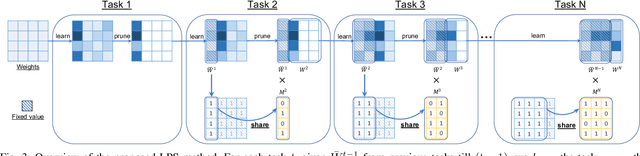
In lifelong learning, we wish to maintain and update a model (e.g., a neural network classifier) in the presence of new classification tasks that arrive sequentially. In this paper, we propose a learn-prune-share (LPS) algorithm which addresses the challenges of catastrophic forgetting, parsimony, and knowledge reuse simultaneously. LPS splits the network into task-specific partitions via an ADMM-based pruning strategy. This leads to no forgetting, while maintaining parsimony. Moreover, LPS integrates a novel selective knowledge sharing scheme into this ADMM optimization framework. This enables adaptive knowledge sharing in an end-to-end fashion. Comprehensive experimental results on two lifelong learning benchmark datasets and a challenging real-world radio frequency fingerprinting dataset are provided to demonstrate the effectiveness of our approach. Our experiments show that LPS consistently outperforms multiple state-of-the-art competitors.
Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework
Dec 12, 2020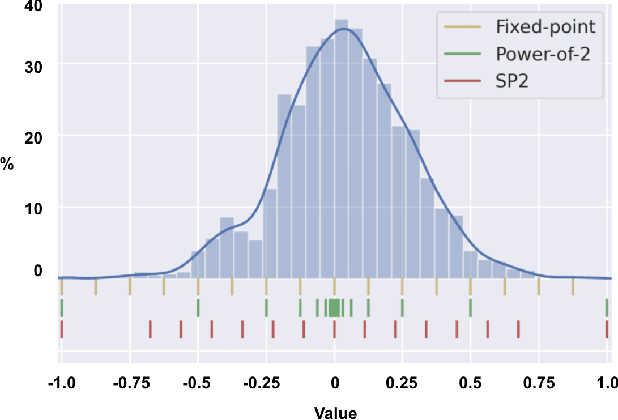
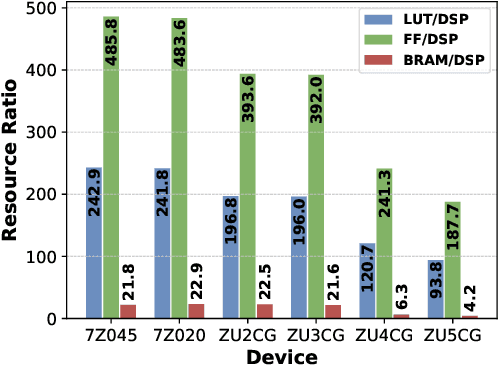
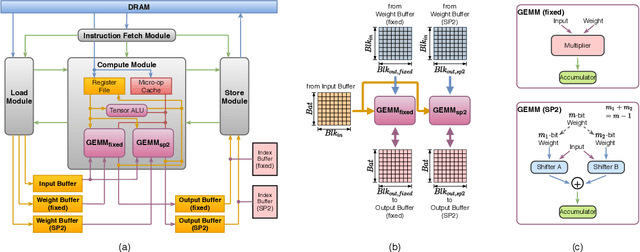
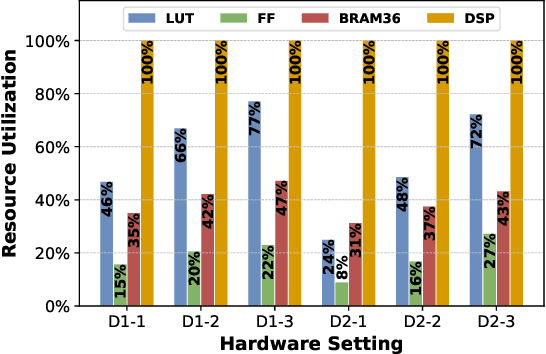
Deep Neural Networks (DNNs) have achieved extraordinary performance in various application domains. To support diverse DNN models, efficient implementations of DNN inference on edge-computing platforms, e.g., ASICs, FPGAs, and embedded systems, are extensively investigated. Due to the huge model size and computation amount, model compression is a critical step to deploy DNN models on edge devices. This paper focuses on weight quantization, a hardware-friendly model compression approach that is complementary to weight pruning. Unlike existing methods that use the same quantization scheme for all weights, we propose the first solution that applies different quantization schemes for different rows of the weight matrix. It is motivated by (1) the distribution of the weights in the different rows are not the same; and (2) the potential of achieving better utilization of heterogeneous FPGA hardware resources. To achieve that, we first propose a hardware-friendly quantization scheme named sum-of-power-of-2 (SP2) suitable for Gaussian-like weight distribution, in which the multiplication arithmetic can be replaced with logic shifter and adder, thereby enabling highly efficient implementations with the FPGA LUT resources. In contrast, the existing fixed-point quantization is suitable for Uniform-like weight distribution and can be implemented efficiently by DSP. Then to fully explore the resources, we propose an FPGA-centric mixed scheme quantization (MSQ) with an ensemble of the proposed SP2 and the fixed-point schemes. Combining the two schemes can maintain, or even increase accuracy due to better matching with weight distributions.