 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025



Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
VaseVQA-3D: Benchmarking 3D VLMs on Ancient Greek Pottery
Oct 06, 2025



Vision-Language Models (VLMs) have achieved significant progress in multimodal understanding tasks, demonstrating strong capabilities particularly in general tasks such as image captioning and visual reasoning. However, when dealing with specialized cultural heritage domains like 3D vase artifacts, existing models face severe data scarcity issues and insufficient domain knowledge limitations. Due to the lack of targeted training data, current VLMs struggle to effectively handle such culturally significant specialized tasks. To address these challenges, we propose the VaseVQA-3D dataset, which serves as the first 3D visual question answering dataset for ancient Greek pottery analysis, collecting 664 ancient Greek vase 3D models with corresponding question-answer data and establishing a complete data construction pipeline. We further develop the VaseVLM model, enhancing model performance in vase artifact analysis through domain-adaptive training. Experimental results validate the effectiveness of our approach, where we improve by 12.8% on R@1 metrics and by 6.6% on lexical similarity compared with previous state-of-the-art on the VaseVQA-3D dataset, significantly improving the recognition and understanding of 3D vase artifacts, providing new technical pathways for digital heritage preservation research.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
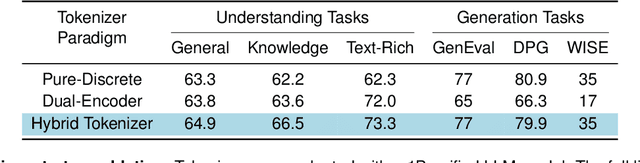
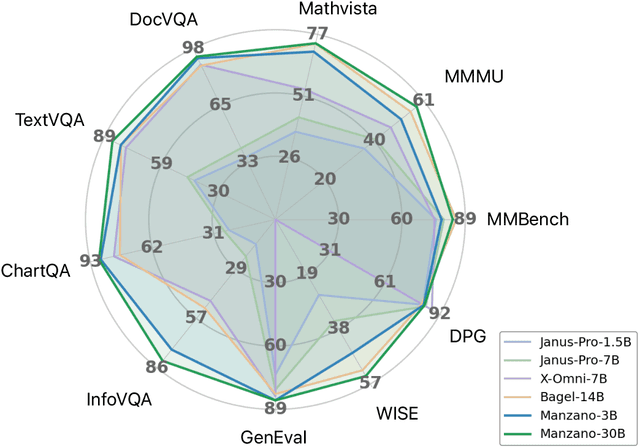
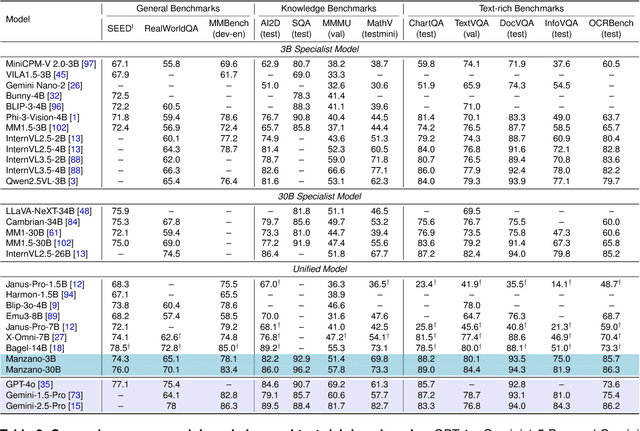
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
End-to-end image compression and reconstruction with ultrahigh speed and ultralow energy enabled by opto-electronic computing processor
Jul 30, 2025The rapid development of AR/VR, remote sensing, satellite radar, and medical equipment has created an imperative demand for ultra efficient image compression and reconstruction that exceed the capabilities of electronic processors. For the first time, we demonstrate an end to end image compression and reconstruction approach using an optoelectronic computing processor,achieving orders of magnitude higher speed and lower energy consumption than electronic counterparts. At its core is a 32X32 silicon photonic computing chip, which monolithically integrates 32 high speed modulators, 32 detectors, and a programmable photonic matrix core, copackaged with all necessary control electronics (TIA, ADC, DAC, FPGA etc.). Leveraging the photonic matrix core programmability, the processor generates trainable compressive matrices, enabling adjustable image compression ratios (from 2X to 256X) to meet diverse application needs. Deploying a custom lightweight photonic integrated circuit oriented network (LiPICO-Net) enables high quality reconstruction of compressed images. Our approach delivers an end to end latency of only 49.5ps/pixel while consuming only less than 10.6nJ/pixel-both metrics representing 2-3 orders of magnitude improvement compared with classical models running on state-of-the-art GPUs. We validate the system on a 130 million-pixel aerial imagery, enabling real time compression where electronic systems falter due to power and latency constraints. This work not only provides a transformative solution for massive image processing but also opens new avenues for photonic computing applications.
Lightweight Remote Sensing Scene Classification on Edge Devices via Knowledge Distillation and Early-exit
Jul 28, 2025



As the development of lightweight deep learning algorithms, various deep neural network (DNN) models have been proposed for the remote sensing scene classification (RSSC) application. However, it is still challenging for these RSSC models to achieve optimal performance among model accuracy, inference latency, and energy consumption on resource-constrained edge devices. In this paper, we propose a lightweight RSSC framework, which includes a distilled global filter network (GFNet) model and an early-exit mechanism designed for edge devices to achieve state-of-the-art performance. Specifically, we first apply frequency domain distillation on the GFNet model to reduce model size. Then we design a dynamic early-exit model tailored for DNN models on edge devices to further improve model inference efficiency. We evaluate our E3C model on three edge devices across four datasets. Extensive experimental results show that it achieves an average of 1.3x speedup on model inference and over 40% improvement on energy efficiency, while maintaining high classification accuracy.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025



We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
Single-to-mix Modality Alignment with Multimodal Large Language Model for Document Image Machine Translation
Jul 10, 2025Document Image Machine Translation (DIMT) aims to translate text within document images, facing generalization challenges due to limited training data and the complex interplay between visual and textual information. To address these challenges, we introduce M4Doc, a novel single-to-mix modality alignment framework leveraging Multimodal Large Language Models (MLLMs). M4Doc aligns an image-only encoder with the multimodal representations of an MLLM, pre-trained on large-scale document image datasets. This alignment enables a lightweight DIMT model to learn crucial visual-textual correlations during training. During inference, M4Doc bypasses the MLLM, maintaining computational efficiency while benefiting from its multimodal knowledge. Comprehensive experiments demonstrate substantial improvements in translation quality, especially in cross-domain generalization and challenging document image scenarios.
Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search
Jul 03, 2025Complex information needs in real-world search scenarios demand deep reasoning and knowledge synthesis across diverse sources, which traditional retrieval-augmented generation (RAG) pipelines struggle to address effectively. Current reasoning-based approaches suffer from a fundamental limitation: they use a single model to handle both high-level planning and detailed execution, leading to inefficient reasoning and limited scalability. In this paper, we introduce HiRA, a hierarchical framework that separates strategic planning from specialized execution. Our approach decomposes complex search tasks into focused subtasks, assigns each subtask to domain-specific agents equipped with external tools and reasoning capabilities, and coordinates the results through a structured integration mechanism. This separation prevents execution details from disrupting high-level reasoning while enabling the system to leverage specialized expertise for different types of information processing. Experiments on four complex, cross-modal deep search benchmarks demonstrate that HiRA significantly outperforms state-of-the-art RAG and agent-based systems. Our results show improvements in both answer quality and system efficiency, highlighting the effectiveness of decoupled planning and execution for multi-step information seeking tasks. Our code is available at https://github.com/ignorejjj/HiRA.
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
Jun 23, 2025



This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model's (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at https://tar.csuhan.com