 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
NeuroCanvas: VLLM-Powered Robust Seizure Detection by Reformulating Multichannel EEG as Image
Feb 04, 2026Accurate and timely seizure detection from Electroencephalography (EEG) is critical for clinical intervention, yet manual review of long-term recordings is labor-intensive. Recent efforts to encode EEG signals into large language models (LLMs) show promise in handling neural signals across diverse patients, but two significant challenges remain: (1) multi-channel heterogeneity, as seizure-relevant information varies substantially across EEG channels, and (2) computing inefficiency, as the EEG signals need to be encoded into a massive number of tokens for the prediction. To address these issues, we draw the EEG signal and propose the novel NeuroCanvas framework. Specifically, NeuroCanvas consists of two modules: (i) The Entropy-guided Channel Selector (ECS) selects the seizure-relevant channels input to LLM and (ii) the following Canvas of Neuron Signal (CNS) converts selected multi-channel heterogeneous EEG signals into structured visual representations. The ECS module alleviates the multi-channel heterogeneity issue, and the CNS uses compact visual tokens to represent the EEG signals that improve the computing efficiency. We evaluate NeuroCanvas across multiple seizure detection datasets, demonstrating a significant improvement of $20\%$ in F1 score and reductions of $88\%$ in inference latency. These results highlight NeuroCanvas as a scalable and effective solution for real-time and resource-efficient seizure detection in clinical practice.The code will be released at https://github.com/Yanchen30247/seizure_detect.
FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning
Jan 26, 2026We propose FROST, an attention-aware method for efficient reasoning. Unlike traditional approaches, FROST leverages attention weights to prune uncritical reasoning paths, yielding shorter and more reliable reasoning trajectories. Methodologically, we introduce the concept of reasoning outliers and design an attention-based mechanism to remove them. Theoretically, FROST preserves and enhances the model's reasoning capacity while eliminating outliers at the sentence level. Empirically, we validate FROST on four benchmarks using two strong reasoning models (Phi-4-Reasoning and GPT-OSS-20B), outperforming state-of-the-art methods such as TALE and ThinkLess. Notably, FROST achieves an average 69.68% reduction in token usage and a 26.70% improvement in accuracy over the base model. Furthermore, in evaluations of attention outlier metrics, FROST reduces the maximum infinity norm by 15.97% and the average kurtosis by 91.09% compared to the base model. Code is available at https://github.com/robinzixuan/FROST
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Human-Human-AI Triadic Programming: Uncovering the Role of AI Agent and the Value of Human Partner in Collaborative Learning
Jan 17, 2026As AI assistance becomes embedded in programming practice, researchers have increasingly examined how these systems help learners generate code and work more efficiently. However, these studies often position AI as a replacement for human collaboration and overlook the social and learning-oriented aspects that emerge in collaborative programming. Our work introduces human-human-AI (HHAI) triadic programming, where an AI agent serves as an additional collaborator rather than a substitute for a human partner. Through a within-subjects study with 20 participants, we show that triadic collaboration enhances collaborative learning and social presence compared to the dyadic human-AI (HAI) baseline. In the triadic HHAI conditions, participants relied significantly less on AI-generated code in their work. This effect was strongest in the HHAI-shared condition, where participants had an increased sense of responsibility to understand AI suggestions before applying them. These findings demonstrate how triadic settings activate socially shared regulation of learning by making AI use visible and accountable to a human peer, suggesting that AI systems that augment rather than automate peer collaboration can better preserve the learning processes that collaborative programming relies on.
SoulSeek: Exploring the Use of Social Cues in LLM-based Information Seeking
Jan 03, 2026Social cues, which convey others' presence, behaviors, or identities, play a crucial role in human information seeking by helping individuals judge relevance and trustworthiness. However, existing LLM-based search systems primarily rely on semantic features, creating a misalignment with the socialized cognition underlying natural information seeking. To address this gap, we explore how the integration of social cues into LLM-based search influences users' perceptions, experiences, and behaviors. Focusing on social media platforms that are beginning to adopt LLM-based search, we integrate design workshops, the implementation of the prototype system (SoulSeek), a between-subjects study, and mixed-method analyses to examine both outcome- and process-level findings. The workshop informs the prototype's cue-integrated design. The study shows that social cues improve perceived outcomes and experiences, promote reflective information behaviors, and reveal limits of current LLM-based search. We propose design implications emphasizing better social-knowledge understanding, personalized cue settings, and controllable interactions.
FQ-PETR: Fully Quantized Position Embedding Transformation for Multi-View 3D Object Detection
Nov 14, 2025Camera-based multi-view 3D detection is crucial for autonomous driving. PETR and its variants (PETRs) excel in benchmarks but face deployment challenges due to high computational cost and memory footprint. Quantization is an effective technique for compressing deep neural networks by reducing the bit width of weights and activations. However, directly applying existing quantization methods to PETRs leads to severe accuracy degradation. This issue primarily arises from two key challenges: (1) significant magnitude disparity between multi-modal features-specifically, image features and camera-ray positional embeddings (PE), and (2) the inefficiency and approximation error of quantizing non-linear operators, which commonly rely on hardware-unfriendly computations. In this paper, we propose FQ-PETR, a fully quantized framework for PETRs, featuring three key innovations: (1) Quantization-Friendly LiDAR-ray Position Embedding (QFPE): Replacing multi-point sampling with LiDAR-prior-guided single-point sampling and anchor-based embedding eliminates problematic non-linearities (e.g., inverse-sigmoid) and aligns PE scale with image features, preserving accuracy. (2) Dual-Lookup Table (DULUT): This algorithm approximates complex non-linear functions using two cascaded linear LUTs, achieving high fidelity with minimal entries and no specialized hardware. (3) Quantization After Numerical Stabilization (QANS): Performing quantization after softmax numerical stabilization mitigates attention distortion from large inputs. On PETRs (e.g. PETR, StreamPETR, PETRv2, MV2d), FQ-PETR under W8A8 achieves near-floating-point accuracy (1% degradation) while reducing latency by up to 75%, significantly outperforming existing PTQ and QAT baselines.
DRPO: Efficient Reasoning via Decoupled Reward Policy Optimization
Oct 06, 2025Recent large reasoning models (LRMs) driven by reinforcement learning algorithms (e.g., GRPO) have achieved remarkable performance on challenging reasoning tasks. However, these models suffer from overthinking, generating unnecessarily long and redundant reasoning even for simple questions, which substantially increases computational cost and response latency. While existing methods incorporate length rewards to GRPO to promote concise reasoning, they incur significant performance degradation. We identify the root cause: when rewards for correct but long rollouts are penalized, GRPO's group-relative advantage function can assign them negative advantages, actively discouraging valid reasoning. To overcome this, we propose Decoupled Reward Policy Optimization (DRPO), a novel framework that decouples the length-based learning signal of correct rollouts from incorrect ones. DRPO ensures that reward signals for correct rollouts are normalized solely within the positive group, shielding them from interference by negative samples. The DRPO's objective is grounded in integrating an optimized positive data distribution, which maximizes length-based rewards under a KL regularization, into a discriminative objective. We derive a closed-form solution for this distribution, enabling efficient computation of the objective and its gradients using only on-policy data and importance weighting. Of independent interest, this formulation is general and can incorporate other preference rewards of positive data beyond length. Experiments on mathematical reasoning tasks demonstrate DRPO's significant superiority over six efficient reasoning baselines. Notably, with a 1.5B model, our method achieves 77\% length reduction with only 1.1\% performance loss on simple questions like GSM8k dataset, while the follow-up baseline sacrifices 4.3\% for 68\% length reduction.
Automating Modelica Module Generation Using Large Language Models: A Case Study on Building Control Description Language
Sep 18, 2025Dynamic energy systems and controls require advanced modeling frameworks to design and test supervisory and fault tolerant strategies. Modelica is a widely used equation based language, but developing control modules is labor intensive and requires specialized expertise. This paper examines the use of large language models (LLMs) to automate the generation of Control Description Language modules in the Building Modelica Library as a case study. We developed a structured workflow that combines standardized prompt scaffolds, library aware grounding, automated compilation with OpenModelica, and human in the loop evaluation. Experiments were carried out on four basic logic tasks (And, Or, Not, and Switch) and five control modules (chiller enable/disable, bypass valve control, cooling tower fan speed, plant requests, and relief damper control). The results showed that GPT 4o failed to produce executable Modelica code in zero shot mode, while Claude Sonnet 4 achieved up to full success for basic logic blocks with carefully engineered prompts. For control modules, success rates reached 83 percent, and failed outputs required medium level human repair (estimated one to eight hours). Retrieval augmented generation often produced mismatches in module selection (for example, And retrieved as Or), while a deterministic hard rule search strategy avoided these errors. Human evaluation also outperformed AI evaluation, since current LLMs cannot assess simulation results or validate behavioral correctness. Despite these limitations, the LLM assisted workflow reduced the average development time from 10 to 20 hours down to 4 to 6 hours per module, corresponding to 40 to 60 percent time savings. These results highlight both the potential and current limitations of LLM assisted Modelica generation, and point to future research in pre simulation validation, stronger grounding, and closed loop evaluation.
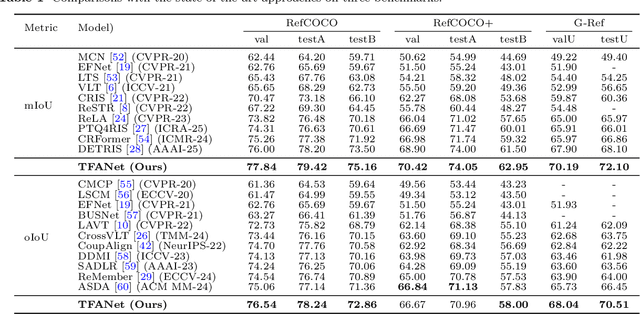
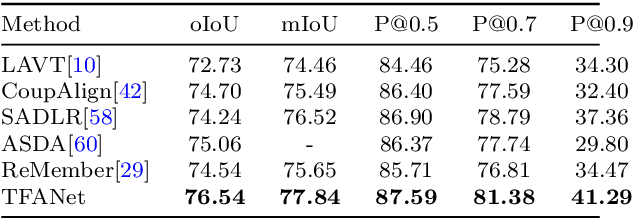
TFANet: Three-Stage Image-Text Feature Alignment Network for Robust Referring Image Segmentation
Sep 16, 2025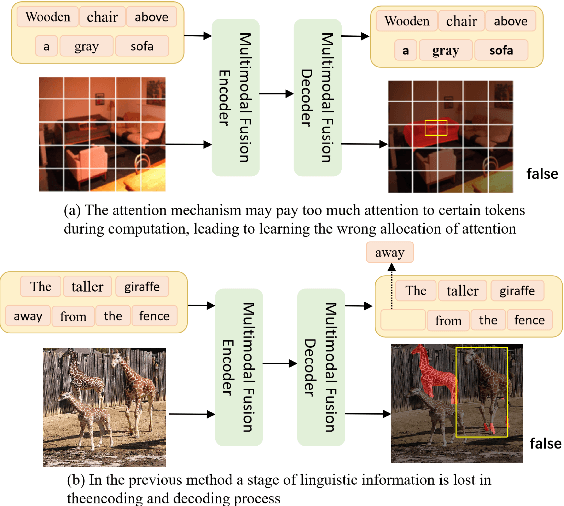
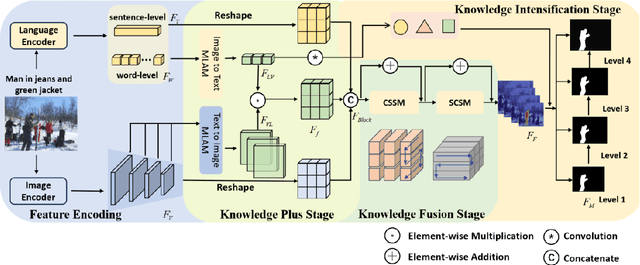
Referring Image Segmentation (RIS) is a task that segments image regions based on language expressions, requiring fine-grained alignment between two modalities. However, existing methods often struggle with multimodal misalignment and language semantic loss, especially in complex scenes containing multiple visually similar objects, where uniquely described targets are frequently mislocalized or incompletely segmented. To tackle these challenges, this paper proposes TFANet, a Three-stage Image-Text Feature Alignment Network that systematically enhances multimodal alignment through a hierarchical framework comprising three stages: Knowledge Plus Stage (KPS), Knowledge Fusion Stage (KFS), and Knowledge Intensification Stage (KIS). In the first stage, we design the Multiscale Linear Cross-Attention Module (MLAM), which facilitates bidirectional semantic exchange between visual features and textual representations across multiple scales. This establishes rich and efficient alignment between image regions and different granularities of linguistic descriptions. Subsequently, the KFS further strengthens feature alignment through the Cross-modal Feature Scanning Module (CFSM), which applies multimodal selective scanning to capture long-range dependencies and construct a unified multimodal representation. This is essential for modeling long-range cross-modal dependencies and enhancing alignment accuracy in complex scenes. Finally, in the KIS, we propose the Word-level Linguistic Feature-guided Semantic Deepening Module (WFDM) to compensate for semantic degradation introduced in earlier stages.