 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperOcc: Toward Cohesive Temporal Modeling for Superquadric-based Occupancy Prediction
Jan 22, 20263D occupancy prediction plays a pivotal role in the realm of autonomous driving, as it provides a comprehensive understanding of the driving environment. Most existing methods construct dense scene representations for occupancy prediction, overlooking the inherent sparsity of real-world driving scenes. Recently, 3D superquadric representation has emerged as a promising sparse alternative to dense scene representations due to the strong geometric expressiveness of superquadrics. However, existing superquadric frameworks still suffer from insufficient temporal modeling, a challenging trade-off between query sparsity and geometric expressiveness, and inefficient superquadric-to-voxel splatting. To address these issues, we propose SuperOcc, a novel framework for superquadric-based 3D occupancy prediction. SuperOcc incorporates three key designs: (1) a cohesive temporal modeling mechanism to simultaneously exploit view-centric and object-centric temporal cues; (2) a multi-superquadric decoding strategy to enhance geometric expressiveness without sacrificing query sparsity; and (3) an efficient superquadric-to-voxel splatting scheme to improve computational efficiency. Extensive experiments on the SurroundOcc and Occ3D benchmarks demonstrate that SuperOcc achieves state-of-the-art performance while maintaining superior efficiency. The code is available at https://github.com/Yzichen/SuperOcc.
FQ-PETR: Fully Quantized Position Embedding Transformation for Multi-View 3D Object Detection
Nov 14, 2025Camera-based multi-view 3D detection is crucial for autonomous driving. PETR and its variants (PETRs) excel in benchmarks but face deployment challenges due to high computational cost and memory footprint. Quantization is an effective technique for compressing deep neural networks by reducing the bit width of weights and activations. However, directly applying existing quantization methods to PETRs leads to severe accuracy degradation. This issue primarily arises from two key challenges: (1) significant magnitude disparity between multi-modal features-specifically, image features and camera-ray positional embeddings (PE), and (2) the inefficiency and approximation error of quantizing non-linear operators, which commonly rely on hardware-unfriendly computations. In this paper, we propose FQ-PETR, a fully quantized framework for PETRs, featuring three key innovations: (1) Quantization-Friendly LiDAR-ray Position Embedding (QFPE): Replacing multi-point sampling with LiDAR-prior-guided single-point sampling and anchor-based embedding eliminates problematic non-linearities (e.g., inverse-sigmoid) and aligns PE scale with image features, preserving accuracy. (2) Dual-Lookup Table (DULUT): This algorithm approximates complex non-linear functions using two cascaded linear LUTs, achieving high fidelity with minimal entries and no specialized hardware. (3) Quantization After Numerical Stabilization (QANS): Performing quantization after softmax numerical stabilization mitigates attention distortion from large inputs. On PETRs (e.g. PETR, StreamPETR, PETRv2, MV2d), FQ-PETR under W8A8 achieves near-floating-point accuracy (1% degradation) while reducing latency by up to 75%, significantly outperforming existing PTQ and QAT baselines.
Q-PETR: Quant-aware Position Embedding Transformation for Multi-View 3D Object Detection
Feb 21, 2025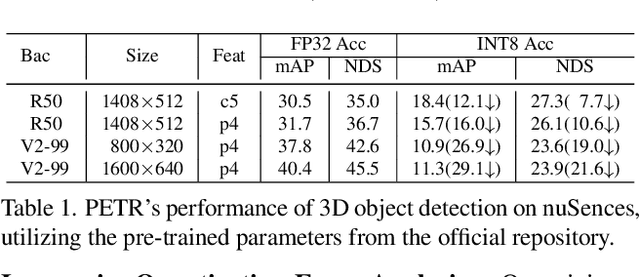

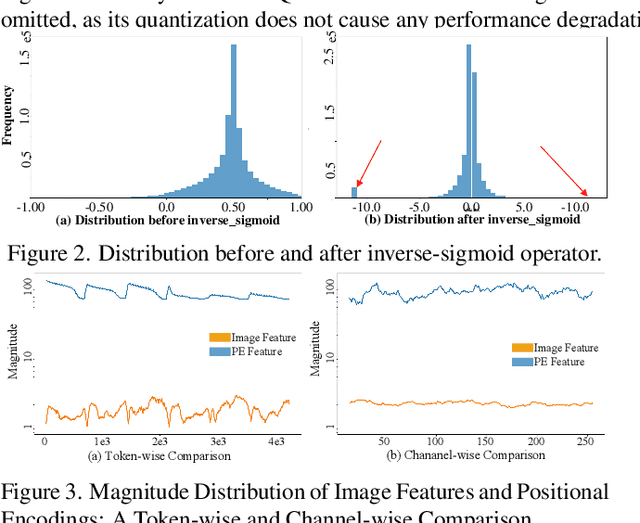
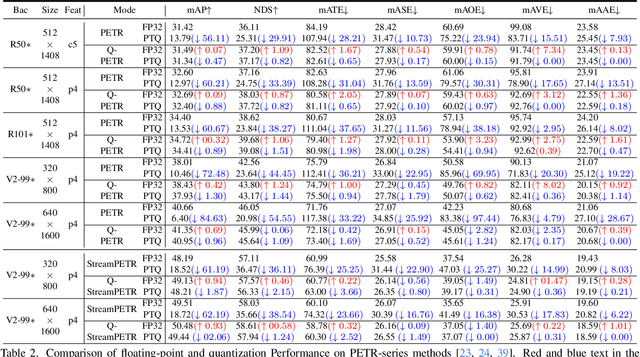
PETR-based methods have dominated benchmarks in 3D perception and are increasingly becoming a key component in modern autonomous driving systems. However, their quantization performance significantly degrades when INT8 inference is required, with a degradation of 58.2% in mAP and 36.9% in NDS on the NuScenes dataset. To address this issue, we propose a quantization-aware position embedding transformation for multi-view 3D object detection, termed Q-PETR. Q-PETR offers a quantizationfriendly and deployment-friendly architecture while preserving the original performance of PETR. It substantially narrows the accuracy gap between INT8 and FP32 inference for PETR-series methods. Without bells and whistles, our approach reduces the mAP and NDS drop to within 1% under standard 8-bit per-tensor post-training quantization. Furthermore, our method exceeds the performance of the original PETR in terms of floating-point precision. Extensive experiments across a variety of PETR-series models demonstrate its broad generalization.
Decoding the Flow: CauseMotion for Emotional Causality Analysis in Long-form Conversations
Jan 01, 2025



Long-sequence causal reasoning seeks to uncover causal relationships within extended time series data but is hindered by complex dependencies and the challenges of validating causal links. To address the limitations of large-scale language models (e.g., GPT-4) in capturing intricate emotional causality within extended dialogues, we propose CauseMotion, a long-sequence emotional causal reasoning framework grounded in Retrieval-Augmented Generation (RAG) and multimodal fusion. Unlike conventional methods relying only on textual information, CauseMotion enriches semantic representations by incorporating audio-derived features-vocal emotion, emotional intensity, and speech rate-into textual modalities. By integrating RAG with a sliding window mechanism, it effectively retrieves and leverages contextually relevant dialogue segments, thus enabling the inference of complex emotional causal chains spanning multiple conversational turns. To evaluate its effectiveness, we constructed the first benchmark dataset dedicated to long-sequence emotional causal reasoning, featuring dialogues with over 70 turns. Experimental results demonstrate that the proposed RAG-based multimodal integrated approach, the efficacy of substantially enhances both the depth of emotional understanding and the causal inference capabilities of large-scale language models. A GLM-4 integrated with CauseMotion achieves an 8.7% improvement in causal accuracy over the original model and surpasses GPT-4o by 1.2%. Additionally, on the publicly available DiaASQ dataset, CauseMotion-GLM-4 achieves state-of-the-art results in accuracy, F1 score, and causal reasoning accuracy.
GSRender: Deduplicated Occupancy Prediction via Weakly Supervised 3D Gaussian Splatting
Dec 19, 2024



3D occupancy perception is gaining increasing attention due to its capability to offer detailed and precise environment representations. Previous weakly-supervised NeRF methods balance efficiency and accuracy, with mIoU varying by 5-10 points due to sampling count along camera rays. Recently, real-time Gaussian splatting has gained widespread popularity in 3D reconstruction, and the occupancy prediction task can also be viewed as a reconstruction task. Consequently, we propose GSRender, which naturally employs 3D Gaussian Splatting for occupancy prediction, simplifying the sampling process. In addition, the limitations of 2D supervision result in duplicate predictions along the same camera ray. We implemented the Ray Compensation (RC) module, which mitigates this issue by compensating for features from adjacent frames. Finally, we redesigned the loss to eliminate the impact of dynamic objects from adjacent frames. Extensive experiments demonstrate that our approach achieves SOTA (state-of-the-art) results in RayIoU (+6.0), while narrowing the gap with 3D supervision methods. Our code will be released soon.
UltimateDO: An Efficient Framework to Marry Occupancy Prediction with 3D Object Detection via Channel2height
Sep 17, 2024



Occupancy and 3D object detection are characterized as two standard tasks in modern autonomous driving system. In order to deploy them on a series of edge chips with better precision and time-consuming trade-off, contemporary approaches either deploy standalone models for individual tasks, or design a multi-task paradigm with separate heads. However, they might suffer from deployment difficulties (i.e., 3D convolution, transformer and so on) or deficiencies in task coordination. Instead, we argue that a favorable framework should be devised in pursuit of ease deployment on diverse chips and high precision with little time-consuming. Oriented at this, we revisit the paradigm for interaction between 3D object detection and occupancy prediction, reformulate the model with 2D convolution and prioritize the tasks such that each contributes to other. Thus, we propose a method to achieve fast 3D object detection and occupancy prediction (UltimateDO), wherein the light occupancy prediction head in FlashOcc is married to 3D object detection network, with negligible additional timeconsuming of only 1.1ms while facilitating each other. We instantiate UltimateDO on the challenging nuScenes-series benchmarks.
PolarBEVDet: Exploring Polar Representation for Multi-View 3D Object Detection in Bird's-Eye-View
Aug 29, 2024



Recently, LSS-based multi-view 3D object detection provides an economical and deployment-friendly solution for autonomous driving. However, all the existing LSS-based methods transform multi-view image features into a Cartesian Bird's-Eye-View(BEV) representation, which does not take into account the non-uniform image information distribution and hardly exploits the view symmetry. In this paper, in order to adapt the image information distribution and preserve the view symmetry by regular convolution, we propose to employ the polar BEV representation to substitute the Cartesian BEV representation. To achieve this, we elaborately tailor three modules: a polar view transformer to generate the polar BEV representation, a polar temporal fusion module for fusing historical polar BEV features and a polar detection head to predict the polar-parameterized representation of the object. In addition, we design a 2D auxiliary detection head and a spatial attention enhancement module to improve the quality of feature extraction in perspective view and BEV, respectively. Finally, we integrate the above improvements into a novel multi-view 3D object detector, PolarBEVDet. Experiments on nuScenes show that PolarBEVDet achieves the superior performance. The code is available at https://github.com/Yzichen/PolarBEVDet.git.
Panoptic-FlashOcc: An Efficient Baseline to Marry Semantic Occupancy with Panoptic via Instance Center
Jun 15, 2024Panoptic occupancy poses a novel challenge by aiming to integrate instance occupancy and semantic occupancy within a unified framework. However, there is still a lack of efficient solutions for panoptic occupancy. In this paper, we propose Panoptic-FlashOcc, a straightforward yet robust 2D feature framework that enables realtime panoptic occupancy. Building upon the lightweight design of FlashOcc, our approach simultaneously learns semantic occupancy and class-aware instance clustering in a single network, these outputs are jointly incorporated through panoptic occupancy procession for panoptic occupancy. This approach effectively addresses the drawbacks of high memory and computation requirements associated with three-dimensional voxel-level representations. With its straightforward and efficient design that facilitates easy deployment, Panoptic-FlashOcc demonstrates remarkable achievements in panoptic occupancy prediction. On the Occ3D-nuScenes benchmark, it achieves exceptional performance, with 38.5 RayIoU and 29.1 mIoU for semantic occupancy, operating at a rapid speed of 43.9 FPS. Furthermore, it attains a notable score of 16.0 RayPQ for panoptic occupancy, accompanied by a fast inference speed of 30.2 FPS. These results surpass the performance of existing methodologies in terms of both speed and accuracy. The source code and trained models can be found at the following github repository: https://github.com/Yzichen/FlashOCC.
FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Nov 18, 2023



Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.
DALNet: A Rail Detection Network Based on Dynamic Anchor Line
Aug 24, 2023



Rail detection is one of the key factors for intelligent train. In the paper, motivated by the anchor line-based lane detection methods, we propose a rail detection network called DALNet based on dynamic anchor line. Aiming to solve the problem that the predefined anchor line is image agnostic, we design a novel dynamic anchor line mechanism. It utilizes a dynamic anchor line generator to dynamically generate an appropriate anchor line for each rail instance based on the position and shape of the rails in the input image. These dynamically generated anchor lines can be considered as better position references to accurately localize the rails than the predefined anchor lines. In addition, we present a challenging urban rail detection dataset DL-Rail with high-quality annotations and scenario diversity. DL-Rail contains 7000 pairs of images and annotations along with scene tags, and it is expected to encourage the development of rail detection. We extensively compare DALNet with many competitive lane methods. The results show that our DALNet achieves state-of-the-art performance on our DL-Rail rail detection dataset and the popular Tusimple and LLAMAS lane detection benchmarks. The code will be released at https://github.com/Yzichen/mmLaneDet.