 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBraveGuard: From Open-World Threats to Safer Computer-Use Agents
May 31, 2026Computer-use agents extend language models from text generation to sustained interaction with files, terminals, browsers, and external tools. This shift creates safety risks that are difficult to detect from isolated prompts or final responses, because harm often emerges only through multi-step execution traces whose individual actions appear locally benign. We introduce BraveGuard, a self-evolving defense framework for training guard models from open-world threat signals and realistic agent trajectories. BraveGuard mines recent research sources to identify emerging risks and attack patterns, instantiates them as executable computer-use tasks, collects agent rollouts, and derives trajectory-level supervision for guard model training. As new threats and validation failures appear, the pipeline can be repeated, yielding an adaptive defense loop rather than a static, benchmark-driven training process. We instantiate BraveGuard by training multiple guard backbones, including Qwen3-Guard and Llama-Guard variants, and evaluate the resulting guards on trajectory-level agent-safety benchmarks. BraveGuard consistently improves safety detection across computer-use trajectories. On AgentHazard, it substantially improves detection accuracy over off-the-shelf guard models, with accuracy increasing from 38.79% to 82.38% under the averaged guard-model setting. These results show that guard supervision grounded in open-world threat discovery and realistic agent execution can improve safety monitoring beyond fixed taxonomies and synthetic prompt-level data. BraveGuard offers a scalable path toward adaptive defenses for computer-use agents facing evolving real-world risks.
TFANet: Three-Stage Image-Text Feature Alignment Network for Robust Referring Image Segmentation
Sep 16, 2025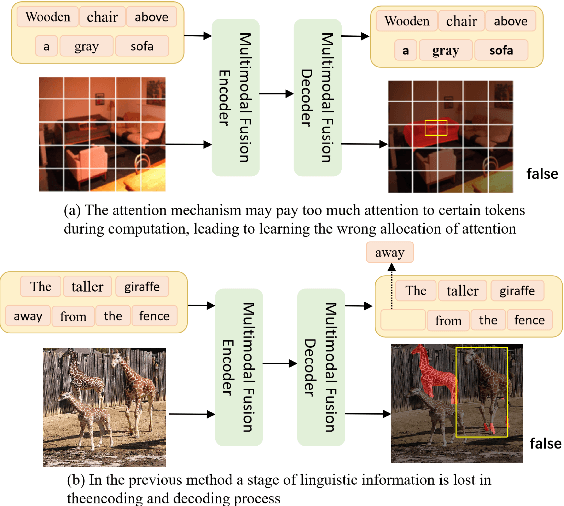
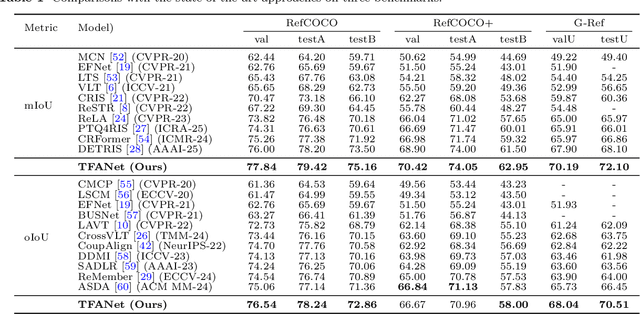
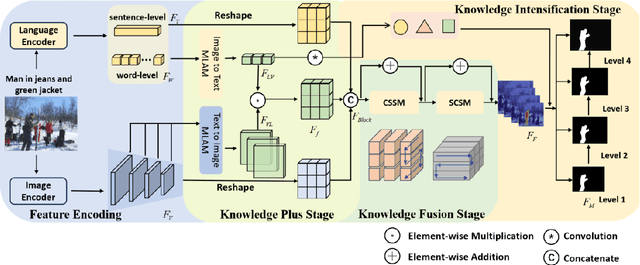
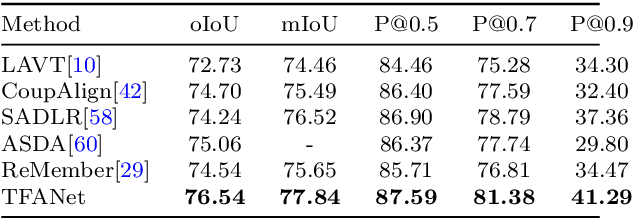
Referring Image Segmentation (RIS) is a task that segments image regions based on language expressions, requiring fine-grained alignment between two modalities. However, existing methods often struggle with multimodal misalignment and language semantic loss, especially in complex scenes containing multiple visually similar objects, where uniquely described targets are frequently mislocalized or incompletely segmented. To tackle these challenges, this paper proposes TFANet, a Three-stage Image-Text Feature Alignment Network that systematically enhances multimodal alignment through a hierarchical framework comprising three stages: Knowledge Plus Stage (KPS), Knowledge Fusion Stage (KFS), and Knowledge Intensification Stage (KIS). In the first stage, we design the Multiscale Linear Cross-Attention Module (MLAM), which facilitates bidirectional semantic exchange between visual features and textual representations across multiple scales. This establishes rich and efficient alignment between image regions and different granularities of linguistic descriptions. Subsequently, the KFS further strengthens feature alignment through the Cross-modal Feature Scanning Module (CFSM), which applies multimodal selective scanning to capture long-range dependencies and construct a unified multimodal representation. This is essential for modeling long-range cross-modal dependencies and enhancing alignment accuracy in complex scenes. Finally, in the KIS, we propose the Word-level Linguistic Feature-guided Semantic Deepening Module (WFDM) to compensate for semantic degradation introduced in earlier stages.