 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
OneRec Technical Report
Jun 16, 2025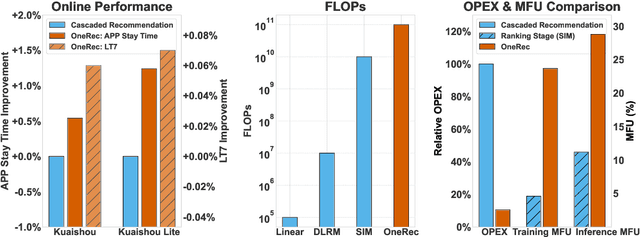

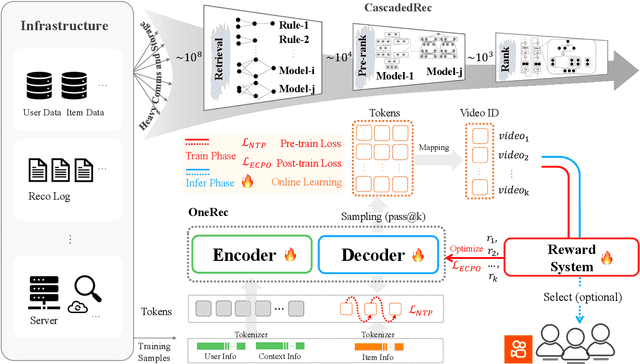
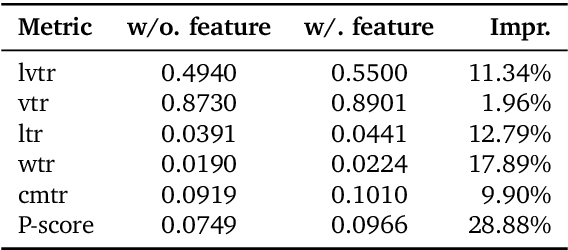
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving
Jun 13, 2025



Autoregressive Transformers are increasingly being deployed as end-to-end robot and autonomous vehicle (AV) policy architectures, owing to their scalability and potential to leverage internet-scale pretraining for generalization. Accordingly, tokenizing sensor data efficiently is paramount to ensuring the real-time feasibility of such architectures on embedded hardware. To this end, we present an efficient triplane-based multi-camera tokenization strategy that leverages recent advances in 3D neural reconstruction and rendering to produce sensor tokens that are agnostic to the number of input cameras and their resolution, while explicitly accounting for their geometry around an AV. Experiments on a large-scale AV dataset and state-of-the-art neural simulator demonstrate that our approach yields significant savings over current image patch-based tokenization strategies, producing up to 72% fewer tokens, resulting in up to 50% faster policy inference while achieving the same open-loop motion planning accuracy and improved offroad rates in closed-loop driving simulations.
Mitigating Posterior Salience Attenuation in Long-Context LLMs with Positional Contrastive Decoding
Jun 11, 2025



While Large Language Models (LLMs) support long contexts, they struggle with performance degradation within the context window. Current solutions incur prohibitive training costs, leaving statistical behaviors and cost-effective approaches underexplored. From the decoding perspective, we identify the Posterior Salience Attenuation (PSA) phenomenon, where the salience ratio correlates with long-text performance degradation. Notably, despite the attenuation, gold tokens still occupy high-ranking positions in the decoding space. Motivated by it, we propose the training-free Positional Contrastive Decoding (PCD) that contrasts the logits derived from long-aware attention with those from designed local-aware attention, enabling the model to focus on the gains introduced by large-scale short-to-long training. Through the analysis of long-term decay simulation, we demonstrate that PCD effectively alleviates attention score degradation. Experimental results show that PCD achieves state-of-the-art performance on long-context benchmarks.
RKEFino1: A Regulation Knowledge-Enhanced Large Language Model
Jun 06, 2025Recent advances in large language models (LLMs) hold great promise for financial applications but introduce critical accuracy and compliance challenges in Digital Regulatory Reporting (DRR). To address these issues, we propose RKEFino1, a regulation knowledge-enhanced financial reasoning model built upon Fino1, fine-tuned with domain knowledge from XBRL, CDM, and MOF. We formulate two QA tasks-knowledge-based and mathematical reasoning-and introduce a novel Numerical NER task covering financial entities in both sentences and tables. Experimental results demonstrate the effectiveness and generalization capacity of RKEFino1 in compliance-critical financial tasks. We have released our model on Hugging Face.
UniPTMs: The First Unified Multi-type PTM Site Prediction Model via Master-Slave Architecture-Based Multi-Stage Fusion Strategy and Hierarchical Contrastive Loss
Jun 05, 2025As a core mechanism of epigenetic regulation in eukaryotes, protein post-translational modifications (PTMs) require precise prediction to decipher dynamic life activity networks. To address the limitations of existing deep learning models in cross-modal feature fusion, domain generalization, and architectural optimization, this study proposes UniPTMs: the first unified framework for multi-type PTM prediction. The framework innovatively establishes a "Master-Slave" dual-path collaborative architecture: The master path dynamically integrates high-dimensional representations of protein sequences, structures, and evolutionary information through a Bidirectional Gated Cross-Attention (BGCA) module, while the slave path optimizes feature discrepancies and recalibration between structural and traditional features using a Low-Dimensional Fusion Network (LDFN). Complemented by a Multi-scale Adaptive convolutional Pyramid (MACP) for capturing local feature patterns and a Bidirectional Hierarchical Gated Fusion Network (BHGFN) enabling multi-level feature integration across paths, the framework employs a Hierarchical Dynamic Weighting Fusion (HDWF) mechanism to intelligently aggregate multimodal features. Enhanced by a novel Hierarchical Contrastive loss function for feature consistency optimization, UniPTMs demonstrates significant performance improvements (3.2%-11.4% MCC and 4.2%-14.3% AP increases) over state-of-the-art models across five modification types and transcends the Single-Type Prediction Paradigm. To strike a balance between model complexity and performance, we have also developed a lightweight variant named UniPTMs-mini.
Magic Mushroom: A Customizable Benchmark for Fine-grained Analysis of Retrieval Noise Erosion in RAG Systems
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external retrieved information, mitigating issues such as hallucination and outdated knowledge. However, RAG systems are highly sensitive to retrieval noise prevalent in real-world scenarios. Existing benchmarks fail to emulate the complex and heterogeneous noise distributions encountered in real-world retrieval environments, undermining reliable robustness assessment. In this paper, we define four categories of retrieval noise based on linguistic properties and noise characteristics, aiming to reflect the heterogeneity of noise in real-world scenarios. Building on this, we introduce Magic Mushroom, a benchmark for replicating "magic mushroom" noise: contexts that appear relevant on the surface but covertly mislead RAG systems. Magic Mushroom comprises 7,468 single-hop and 3,925 multi-hop question-answer pairs. More importantly, Magic Mushroom enables researchers to flexibly configure combinations of retrieval noise according to specific research objectives or application scenarios, allowing for highly controlled evaluation setups. We evaluate LLM generators of varying parameter scales and classic RAG denoising strategies under diverse noise distributions to investigate their performance dynamics during progressive noise encroachment. Our analysis reveals that both generators and denoising strategies have significant room for improvement and exhibit extreme sensitivity to noise distributions. Magic Mushroom emerges as a promising tool for evaluating and advancing noise-robust RAG systems, accelerating their widespread deployment in real-world applications. The Magic Mushroom benchmark is available at https://drive.google.com/file/d/1aP5kyPuk4L-L_uoI6T9UhxuTyt8oMqjT/view?usp=sharing.
FinTagging: An LLM-ready Benchmark for Extracting and Structuring Financial Information
May 27, 2025We introduce FinTagging, the first full-scope, table-aware XBRL benchmark designed to evaluate the structured information extraction and semantic alignment capabilities of large language models (LLMs) in the context of XBRL-based financial reporting. Unlike prior benchmarks that oversimplify XBRL tagging as flat multi-class classification and focus solely on narrative text, FinTagging decomposes the XBRL tagging problem into two subtasks: FinNI for financial entity extraction and FinCL for taxonomy-driven concept alignment. It requires models to jointly extract facts and align them with the full 10k+ US-GAAP taxonomy across both unstructured text and structured tables, enabling realistic, fine-grained evaluation. We assess a diverse set of LLMs under zero-shot settings, systematically analyzing their performance on both subtasks and overall tagging accuracy. Our results reveal that, while LLMs demonstrate strong generalization in information extraction, they struggle with fine-grained concept alignment, particularly in disambiguating closely related taxonomy entries. These findings highlight the limitations of existing LLMs in fully automating XBRL tagging and underscore the need for improved semantic reasoning and schema-aware modeling to meet the demands of accurate financial disclosure. Code is available at our GitHub repository and data is at our Hugging Face repository.
Simultaneous Modeling of Protein Conformation and Dynamics via Autoregression
May 23, 2025Understanding protein dynamics is critical for elucidating their biological functions. The increasing availability of molecular dynamics (MD) data enables the training of deep generative models to efficiently explore the conformational space of proteins. However, existing approaches either fail to explicitly capture the temporal dependencies between conformations or do not support direct generation of time-independent samples. To address these limitations, we introduce ConfRover, an autoregressive model that simultaneously learns protein conformation and dynamics from MD trajectories, supporting both time-dependent and time-independent sampling. At the core of our model is a modular architecture comprising: (i) an encoding layer, adapted from protein folding models, that embeds protein-specific information and conformation at each time frame into a latent space; (ii) a temporal module, a sequence model that captures conformational dynamics across frames; and (iii) an SE(3) diffusion model as the structure decoder, generating conformations in continuous space. Experiments on ATLAS, a large-scale protein MD dataset of diverse structures, demonstrate the effectiveness of our model in learning conformational dynamics and supporting a wide range of downstream tasks. ConfRover is the first model to sample both protein conformations and trajectories within a single framework, offering a novel and flexible approach for learning from protein MD data.
Causal-Invariant Cross-Domain Out-of-Distribution Recommendation
May 22, 2025Cross-Domain Recommendation (CDR) aims to leverage knowledge from a relatively data-richer source domain to address the data sparsity problem in a relatively data-sparser target domain. While CDR methods need to address the distribution shifts between different domains, i.e., cross-domain distribution shifts (CDDS), they typically assume independent and identical distribution (IID) between training and testing data within the target domain. However, this IID assumption rarely holds in real-world scenarios due to single-domain distribution shift (SDDS). The above two co-existing distribution shifts lead to out-of-distribution (OOD) environments that hinder effective knowledge transfer and generalization, ultimately degrading recommendation performance in CDR. To address these co-existing distribution shifts, we propose a novel Causal-Invariant Cross-Domain Out-of-distribution Recommendation framework, called CICDOR. In CICDOR, we first learn dual-level causal structures to infer domain-specific and domain-shared causal-invariant user preferences for tackling both CDDS and SDDS under OOD environments in CDR. Then, we propose an LLM-guided confounder discovery module that seamlessly integrates LLMs with a conventional causal discovery method to extract observed confounders for effective deconfounding, thereby enabling accurate causal-invariant preference inference. Extensive experiments on two real-world datasets demonstrate the superior recommendation accuracy of CICDOR over state-of-the-art methods across various OOD scenarios.