 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Gait Learning for Humanoid Robots Using Reinforcement Learning with Selective Adversarial Motion Prior
Apr 21, 2026Learning diverse locomotion skills for humanoid robots in a unified reinforcement learning framework remains challenging due to the conflicting requirements of stability and dynamic expressiveness across different gaits. We present a multi-gait learning approach that enables a humanoid robot to master five distinct gaits -- walking, goose-stepping, running, stair climbing, and jumping -- using a consistent policy structure, action space, and reward formulation. The key contribution is a selective Adversarial Motion Prior (AMP) strategy: AMP is applied to periodic, stability-critical gaits (walking, goose-stepping, stair climbing) where it accelerates convergence and suppresses erratic behavior, while being deliberately omitted for highly dynamic gaits (running, jumping) where its regularization would over-constrain the motion. Policies are trained via PPO with domain randomization in simulation and deployed on a physical 12-DOF humanoid robot through zero-shot sim-to-real transfer. Quantitative comparisons demonstrate that selective AMP outperforms a uniform AMP policy across all five gaits, achieving faster convergence, lower tracking error, and higher success rates on stability-focused gaits without sacrificing the agility required for dynamic ones.
SEA-Eval: A Benchmark for Evaluating Self-Evolving Agents Beyond Episodic Assessment
Apr 14, 2026Current LLM-based agents demonstrate strong performance in episodic task execution but remain constrained by static toolsets and episodic amnesia, failing to accumulate experience across task boundaries. This paper presents the first formal definition of the Self-Evolving Agent (SEA), formalizes the Evolutionary Flywheel as its minimal sufficient architecture, and introduces SEA-Eval -- the first benchmark designed specifically for evaluating SEAs. Grounded in Flywheel theory, SEA-Eval establishes $SR$ and $T$ as primary metrics and enables through sequential task stream design the independent quantification of evolutionary gain, evolutionary stability, and implicit alignment convergence. Empirical evaluation reveals that under identical success rates, token consumption differs by up to 31.2$\times$ across frameworks, with divergent evolutionary trajectories under sequential analysis -- demonstrating that success rate alone creates a capability illusion and that the sequential convergence of $T$ is the key criterion for distinguishing genuine evolution from pseudo-evolution.
Reasoning Models Ace the CFA Exams
Dec 09, 2025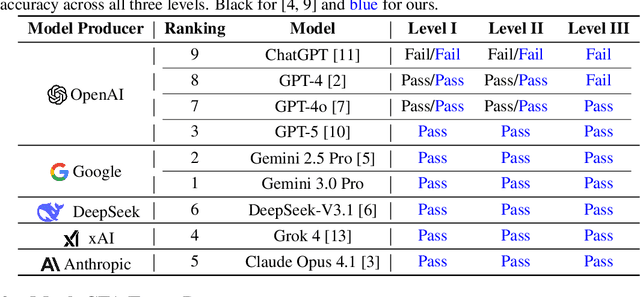
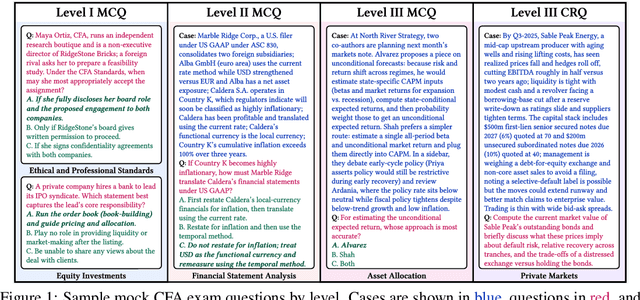
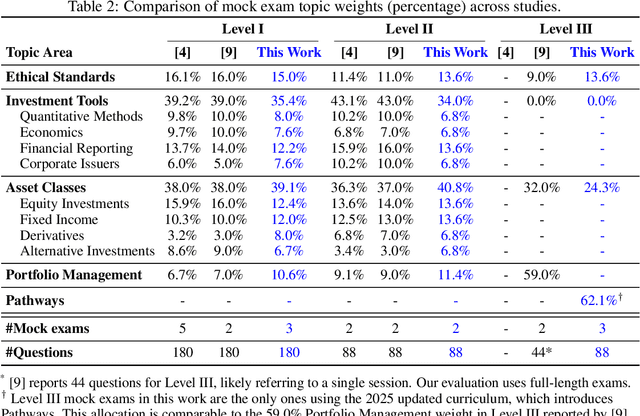
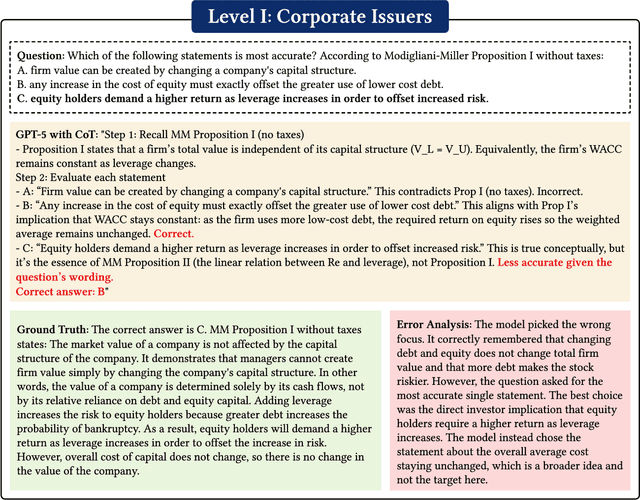
Previous research has reported that large language models (LLMs) demonstrate poor performance on the Chartered Financial Analyst (CFA) exams. However, recent reasoning models have achieved strong results on graduate-level academic and professional examinations across various disciplines. In this paper, we evaluate state-of-the-art reasoning models on a set of mock CFA exams consisting of 980 questions across three Level I exams, two Level II exams, and three Level III exams. Using the same pass/fail criteria from prior studies, we find that most models clear all three levels. The models that pass, ordered by overall performance, are Gemini 3.0 Pro, Gemini 2.5 Pro, GPT-5, Grok 4, Claude Opus 4.1, and DeepSeek-V3.1. Specifically, Gemini 3.0 Pro achieves a record score of 97.6% on Level I. Performance is also strong on Level II, led by GPT-5 at 94.3%. On Level III, Gemini 2.5 Pro attains the highest score with 86.4% on multiple-choice questions while Gemini 3.0 Pro achieves 92.0% on constructed-response questions.
FinTagging: An LLM-ready Benchmark for Extracting and Structuring Financial Information
May 27, 2025We introduce FinTagging, the first full-scope, table-aware XBRL benchmark designed to evaluate the structured information extraction and semantic alignment capabilities of large language models (LLMs) in the context of XBRL-based financial reporting. Unlike prior benchmarks that oversimplify XBRL tagging as flat multi-class classification and focus solely on narrative text, FinTagging decomposes the XBRL tagging problem into two subtasks: FinNI for financial entity extraction and FinCL for taxonomy-driven concept alignment. It requires models to jointly extract facts and align them with the full 10k+ US-GAAP taxonomy across both unstructured text and structured tables, enabling realistic, fine-grained evaluation. We assess a diverse set of LLMs under zero-shot settings, systematically analyzing their performance on both subtasks and overall tagging accuracy. Our results reveal that, while LLMs demonstrate strong generalization in information extraction, they struggle with fine-grained concept alignment, particularly in disambiguating closely related taxonomy entries. These findings highlight the limitations of existing LLMs in fully automating XBRL tagging and underscore the need for improved semantic reasoning and schema-aware modeling to meet the demands of accurate financial disclosure. Code is available at our GitHub repository and data is at our Hugging Face repository.
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading
Feb 19, 2025



Large language models (LLMs) fine-tuned on multimodal financial data have demonstrated impressive reasoning capabilities in various financial tasks. However, they often struggle with multi-step, goal-oriented scenarios in interactive financial markets, such as trading, where complex agentic approaches are required to improve decision-making. To address this, we propose \textsc{FLAG-Trader}, a unified architecture integrating linguistic processing (via LLMs) with gradient-driven reinforcement learning (RL) policy optimization, in which a partially fine-tuned LLM acts as the policy network, leveraging pre-trained knowledge while adapting to the financial domain through parameter-efficient fine-tuning. Through policy gradient optimization driven by trading rewards, our framework not only enhances LLM performance in trading but also improves results on other financial-domain tasks. We present extensive empirical evidence to validate these enhancements.
Revisiting Ensemble Methods for Stock Trading and Crypto Trading Tasks at ACM ICAIF FinRL Contest 2023-2024
Jan 18, 2025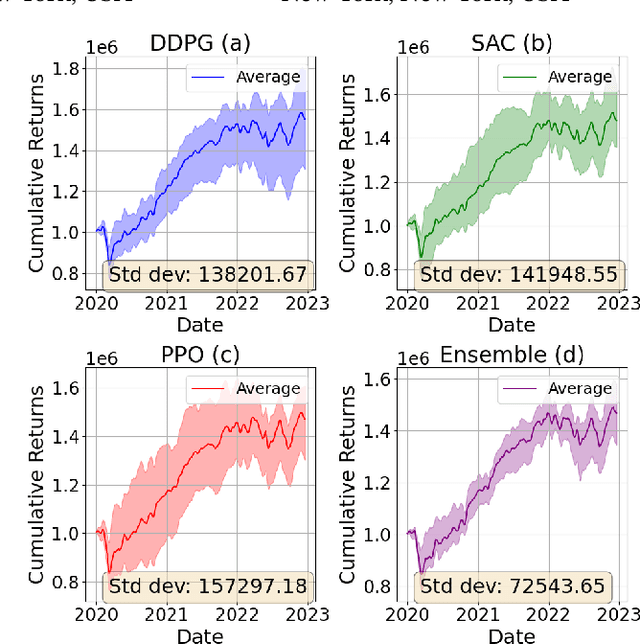

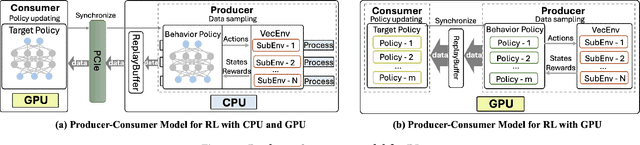
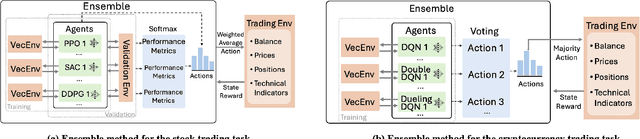
Reinforcement learning has demonstrated great potential for performing financial tasks. However, it faces two major challenges: policy instability and sampling bottlenecks. In this paper, we revisit ensemble methods with massively parallel simulations on graphics processing units (GPUs), significantly enhancing the computational efficiency and robustness of trained models in volatile financial markets. Our approach leverages the parallel processing capability of GPUs to significantly improve the sampling speed for training ensemble models. The ensemble models combine the strengths of component agents to improve the robustness of financial decision-making strategies. We conduct experiments in both stock and cryptocurrency trading tasks to evaluate the effectiveness of our approach. Massively parallel simulation on a single GPU improves the sampling speed by up to $1,746\times$ using $2,048$ parallel environments compared to a single environment. The ensemble models have high cumulative returns and outperform some individual agents, reducing maximum drawdown by up to $4.17\%$ and improving the Sharpe ratio by up to $0.21$. This paper describes trading tasks at ACM ICAIF FinRL Contests in 2023 and 2024.
The Ghanaian NLP Landscape: A First Look
May 10, 2024Despite comprising one-third of global languages, African languages are critically underrepresented in Artificial Intelligence (AI), threatening linguistic diversity and cultural heritage. Ghanaian languages, in particular, face an alarming decline, with documented extinction and several at risk. This study pioneers a comprehensive survey of Natural Language Processing (NLP) research focused on Ghanaian languages, identifying methodologies, datasets, and techniques employed. Additionally, we create a detailed roadmap outlining challenges, best practices, and future directions, aiming to improve accessibility for researchers. This work serves as a foundational resource for Ghanaian NLP research and underscores the critical need for integrating global linguistic diversity into AI development.