 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Aligned Spectral Mamba: Decoupling Semantics and Dynamics for Few-Shot Hyperspectral Target Detection
Apr 07, 2026Meta-learning facilitates few-shot hyperspectral target detection (HTD), but adapting deep backbones remains challenging. Full-parameter fine-tuning is inefficient and prone to overfitting, and existing methods largely ignore the frequency-domain structure and spectral band continuity of hyperspectral data, limiting spectral adaptation and cross-domain generalization.To address these challenges, we propose SpecMamba, a parameter-efficient and frequency-aware framework that decouples stable semantic representation from agile spectral adaptation. Specifically, we introduce a Discrete Cosine Transform Mamba Adapter (DCTMA) on top of frozen Transformer representations. By projecting spectral features into the frequency domain via DCT and leveraging Mamba's linear-complexity state-space recursion, DCTMA explicitly captures global spectral dependencies and band continuity while avoiding the redundancy of full fine-tuning. Furthermore, to address prototype drift caused by limited sample sizes, we design a Prior-Guided Tri-Encoder (PGTE) that allows laboratory spectral priors to guide the optimization of the learnable adapter without disrupting the stable semantic feature space. Finally, a Self-Supervised Pseudo-Label Mapping (SSPLM) strategy is developed for test-time adaptation, enabling efficient decision boundary refinement through uncertainty-aware sampling and dual-path consistency constraints. Extensive experiments on multiple public datasets demonstrate that SpecMamba consistently outperforms state-of-the-art methods in detection accuracy and cross-domain generalization.
CoT2-Meta: Budgeted Metacognitive Control for Test-Time Reasoning
Mar 30, 2026Recent test-time reasoning methods improve performance by generating more candidate chains or searching over larger reasoning trees, but they typically lack explicit control over when to expand, what to prune, how to repair, and when to abstain. We introduce CoT2-Meta, a training-free metacognitive reasoning framework that combines object-level chain-of-thought generation with meta-level control over partial reasoning trajectories. The framework integrates four components: strategy-conditioned thought generation, tree-structured search, an online process oracle for step-level reasoning evaluation, and a meta-controller that allocates computation through expansion, pruning, repair, stopping, and fallback decisions. Under matched inference budgets, CoT2-Meta consistently outperforms strong single-path, sampling-based, and search-based baselines, including ReST-MCTS. On the default backbone, it achieves 92.8 EM on MATH, 90.4 accuracy on GPQA, 98.65 EM on GSM8K, 75.8 accuracy on BBEH, 85.6 accuracy on MMMU-Pro, and 48.8 accuracy on HLE, with gains over the strongest non-CoT2-Meta baseline of +3.6, +5.2, +1.15, +2.0, +4.3, and +4.3 points, respectively. Beyond these core results, the framework remains effective across a broader 15-benchmark suite spanning knowledge and QA, multi-hop reasoning, coding, and out-of-distribution evaluation. Additional analyses show better compute scaling, improved calibration, stronger selective prediction, targeted repair behavior, and consistent gains across backbone families. These results suggest that explicit metacognitive control is a practical design principle for reliable and compute-efficient test-time reasoning systems.
DualSG: A Dual-Stream Explicit Semantic-Guided Multivariate Time Series Forecasting Framework
Jul 30, 2025
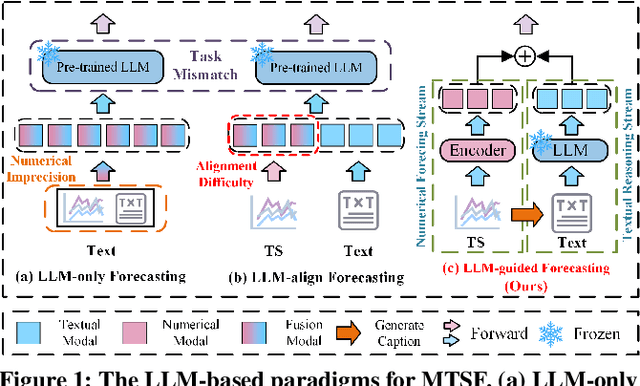
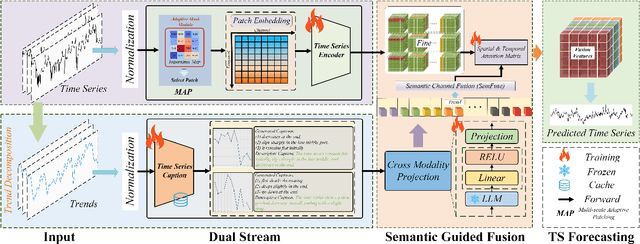

Multivariate Time Series Forecasting plays a key role in many applications. Recent works have explored using Large Language Models for MTSF to take advantage of their reasoning abilities. However, many methods treat LLMs as end-to-end forecasters, which often leads to a loss of numerical precision and forces LLMs to handle patterns beyond their intended design. Alternatively, methods that attempt to align textual and time series modalities within latent space frequently encounter alignment difficulty. In this paper, we propose to treat LLMs not as standalone forecasters, but as semantic guidance modules within a dual-stream framework. We propose DualSG, a dual-stream framework that provides explicit semantic guidance, where LLMs act as Semantic Guides to refine rather than replace traditional predictions. As part of DualSG, we introduce Time Series Caption, an explicit prompt format that summarizes trend patterns in natural language and provides interpretable context for LLMs, rather than relying on implicit alignment between text and time series in the latent space. We also design a caption-guided fusion module that explicitly models inter-variable relationships while reducing noise and computation. Experiments on real-world datasets from diverse domains show that DualSG consistently outperforms 15 state-of-the-art baselines, demonstrating the value of explicitly combining numerical forecasting with semantic guidance.
Mitigating Posterior Salience Attenuation in Long-Context LLMs with Positional Contrastive Decoding
Jun 11, 2025



While Large Language Models (LLMs) support long contexts, they struggle with performance degradation within the context window. Current solutions incur prohibitive training costs, leaving statistical behaviors and cost-effective approaches underexplored. From the decoding perspective, we identify the Posterior Salience Attenuation (PSA) phenomenon, where the salience ratio correlates with long-text performance degradation. Notably, despite the attenuation, gold tokens still occupy high-ranking positions in the decoding space. Motivated by it, we propose the training-free Positional Contrastive Decoding (PCD) that contrasts the logits derived from long-aware attention with those from designed local-aware attention, enabling the model to focus on the gains introduced by large-scale short-to-long training. Through the analysis of long-term decay simulation, we demonstrate that PCD effectively alleviates attention score degradation. Experimental results show that PCD achieves state-of-the-art performance on long-context benchmarks.
SurgBench: A Unified Large-Scale Benchmark for Surgical Video Analysis
Jun 09, 2025Surgical video understanding is pivotal for enabling automated intraoperative decision-making, skill assessment, and postoperative quality improvement. However, progress in developing surgical video foundation models (FMs) remains hindered by the scarcity of large-scale, diverse datasets for pretraining and systematic evaluation. In this paper, we introduce \textbf{SurgBench}, a unified surgical video benchmarking framework comprising a pretraining dataset, \textbf{SurgBench-P}, and an evaluation benchmark, \textbf{SurgBench-E}. SurgBench offers extensive coverage of diverse surgical scenarios, with SurgBench-P encompassing 53 million frames across 22 surgical procedures and 11 specialties, and SurgBench-E providing robust evaluation across six categories (phase classification, camera motion, tool recognition, disease diagnosis, action classification, and organ detection) spanning 72 fine-grained tasks. Extensive experiments reveal that existing video FMs struggle to generalize across varied surgical video analysis tasks, whereas pretraining on SurgBench-P yields substantial performance improvements and superior cross-domain generalization to unseen procedures and modalities. Our dataset and code are available upon request.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
May 23, 2025Humans naturally understand moments in a video by integrating visual and auditory cues. For example, localizing a scene in the video like "A scientist passionately speaks on wildlife conservation as dramatic orchestral music plays, with the audience nodding and applauding" requires simultaneous processing of visual, audio, and speech signals. However, existing models often struggle to effectively fuse and interpret audio information, limiting their capacity for comprehensive video temporal understanding. To address this, we present TriSense, a triple-modality large language model designed for holistic video temporal understanding through the integration of visual, audio, and speech modalities. Central to TriSense is a Query-Based Connector that adaptively reweights modality contributions based on the input query, enabling robust performance under modality dropout and allowing flexible combinations of available inputs. To support TriSense's multimodal capabilities, we introduce TriSense-2M, a high-quality dataset of over 2 million curated samples generated via an automated pipeline powered by fine-tuned LLMs. TriSense-2M includes long-form videos and diverse modality combinations, facilitating broad generalization. Extensive experiments across multiple benchmarks demonstrate the effectiveness of TriSense and its potential to advance multimodal video analysis. Code and dataset will be publicly released.
DPNet: Dynamic Pooling Network for Tiny Object Detection
May 05, 2025



In unmanned aerial systems, especially in complex environments, accurately detecting tiny objects is crucial. Resizing images is a common strategy to improve detection accuracy, particularly for small objects. However, simply enlarging images significantly increases computational costs and the number of negative samples, severely degrading detection performance and limiting its applicability. This paper proposes a Dynamic Pooling Network (DPNet) for tiny object detection to mitigate these issues. DPNet employs a flexible down-sampling strategy by introducing a factor (df) to relax the fixed downsampling process of the feature map to an adjustable one. Furthermore, we design a lightweight predictor to predict df for each input image, which is used to decrease the resolution of feature maps in the backbone. Thus, we achieve input-aware downsampling. We also design an Adaptive Normalization Module (ANM) to make a unified detector compatible with different dfs. A guidance loss supervises the predictor's training. DPNet dynamically allocates computing resources to trade off between detection accuracy and efficiency. Experiments on the TinyCOCO and TinyPerson datasets show that DPNet can save over 35% and 25% GFLOPs, respectively, while maintaining comparable detection performance. The code will be made publicly available.
FairSteer: Inference Time Debiasing for LLMs with Dynamic Activation Steering
Apr 20, 2025Large language models (LLMs) are prone to capturing biases from training corpus, leading to potential negative social impacts. Existing prompt-based debiasing methods exhibit instability due to their sensitivity to prompt changes, while fine-tuning-based techniques incur substantial computational overhead and catastrophic forgetting. In this paper, we propose FairSteer, a novel inference-time debiasing framework without requiring customized prompt design or model retraining. Motivated by the linear representation hypothesis, our preliminary investigation demonstrates that fairness-related features can be encoded into separable directions in the hidden activation space. FairSteer operates in three steps: biased activation detection, debiasing steering vector (DSV) computation, and dynamic activation steering. Specifically, it first trains a lightweight linear classifier to detect bias signatures in activations, and then computes DSVs as intervention directions derived from small contrastive prompt pairs. Subsequently, it performs debiasing by adjusting activations with DSVs in the inference stage. Comprehensive evaluation with six LLMs demonstrates the superiority of FairSteer across question-answering, counterfactual input evaluation and open-ended text generation tasks. Code will be released.
DiffuMural: Restoring Dunhuang Murals with Multi-scale Diffusion
Apr 13, 2025Large-scale pre-trained diffusion models have produced excellent results in the field of conditional image generation. However, restoration of ancient murals, as an important downstream task in this field, poses significant challenges to diffusion model-based restoration methods due to its large defective area and scarce training samples. Conditional restoration tasks are more concerned with whether the restored part meets the aesthetic standards of mural restoration in terms of overall style and seam detail, and such metrics for evaluating heuristic image complements are lacking in current research. We therefore propose DiffuMural, a combined Multi-scale convergence and Collaborative Diffusion mechanism with ControlNet and cyclic consistency loss to optimise the matching between the generated images and the conditional control. DiffuMural demonstrates outstanding capabilities in mural restoration, leveraging training data from 23 large-scale Dunhuang murals that exhibit consistent visual aesthetics. The model excels in restoring intricate details, achieving a coherent overall appearance, and addressing the unique challenges posed by incomplete murals lacking factual grounding. Our evaluation framework incorporates four key metrics to quantitatively assess incomplete murals: factual accuracy, textural detail, contextual semantics, and holistic visual coherence. Furthermore, we integrate humanistic value assessments to ensure the restored murals retain their cultural and artistic significance. Extensive experiments validate that our method outperforms state-of-the-art (SOTA) approaches in both qualitative and quantitative metrics.
TransformDAS: Mapping Φ-OTDR Signals to Riemannian Manifold for Robust Classification
Feb 04, 2025



Phase-sensitive optical time-domain reflectometry ({\Phi}-OTDR) is a widely used distributed fiber optic sensing system in engineering. Machine learning algorithms for {\Phi}-OTDR event classification require high volumes and quality of datasets; however, high-quality datasets are currently extremely scarce in the field, leading to a lack of robustness in models, which is manifested by higher false alarm rates in real-world scenarios. One promising approach to address this issue is to augment existing data using generative models combined with a small amount of real-world data. We explored mapping both {\Phi}-OTDR features in a GAN-based generative pipeline and signal features in a Transformer classifier to hyperbolic space to seek more effective model generalization. The results indicate that state-of-the-art models exhibit stronger generalization performance and lower false alarm rates in real-world scenarios when trained on augmented datasets. TransformDAS, in particular, demonstrates the best classification performance, highlighting the benefits of Riemannian manifold mapping in {\Phi}-OTDR data generation and model classification.