 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Representational Position Encoding
Dec 08, 2025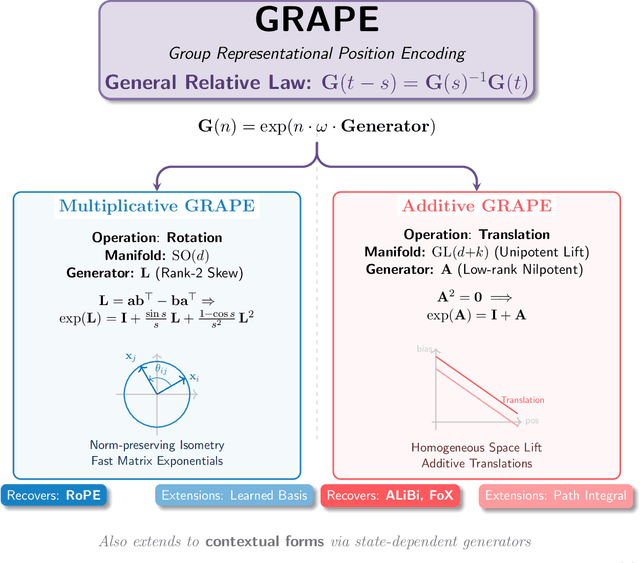
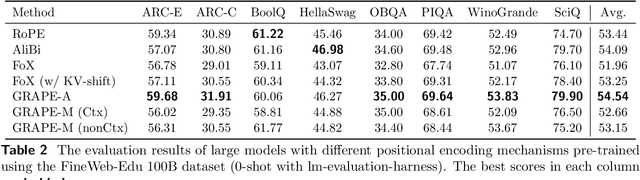
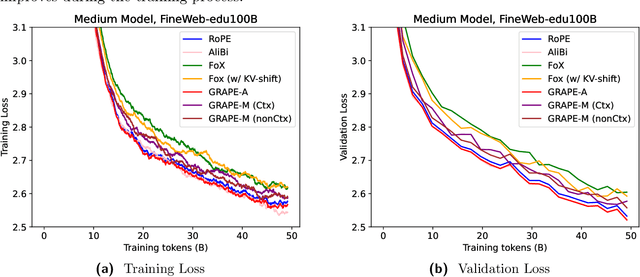

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
Causal Attention with Lookahead Keys
Sep 09, 2025In standard causal attention, each token's query, key, and value (QKV) are static and encode only preceding context. We introduce CAuSal aTtention with Lookahead kEys (CASTLE), an attention mechanism that continually updates each token's keys as the context unfolds. We term these updated keys lookahead keys because they belong to earlier positions yet integrate information from tokens that appear later relative to those positions, while strictly preserving the autoregressive property. Although the mechanism appears sequential, we derive a mathematical equivalence that avoids explicitly materializing lookahead keys at each position and enables efficient parallel training. On language modeling benchmarks, CASTLE consistently outperforms standard causal attention across model scales, reducing validation perplexity and improving performance on a range of downstream tasks.
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
May 23, 2025Policy gradient algorithms have been successfully applied to enhance the reasoning capabilities of large language models (LLMs). Despite the widespread use of Kullback-Leibler (KL) regularization in policy gradient algorithms to stabilize training, the systematic exploration of how different KL divergence formulations can be estimated and integrated into surrogate loss functions for online reinforcement learning (RL) presents a nuanced and systematically explorable design space. In this paper, we propose regularized policy gradient (RPG), a systematic framework for deriving and analyzing KL-regularized policy gradient methods in the online RL setting. We derive policy gradients and corresponding surrogate loss functions for objectives regularized by both forward and reverse KL divergences, considering both normalized and unnormalized policy distributions. Furthermore, we present derivations for fully differentiable loss functions as well as REINFORCE-style gradient estimators, accommodating diverse algorithmic needs. We conduct extensive experiments on RL for LLM reasoning using these methods, showing improved or competitive results in terms of training stability and performance compared to strong baselines such as GRPO, REINFORCE++, and DAPO. The code is available at https://github.com/complex-reasoning/RPG.
Simultaneous Modeling of Protein Conformation and Dynamics via Autoregression
May 23, 2025Understanding protein dynamics is critical for elucidating their biological functions. The increasing availability of molecular dynamics (MD) data enables the training of deep generative models to efficiently explore the conformational space of proteins. However, existing approaches either fail to explicitly capture the temporal dependencies between conformations or do not support direct generation of time-independent samples. To address these limitations, we introduce ConfRover, an autoregressive model that simultaneously learns protein conformation and dynamics from MD trajectories, supporting both time-dependent and time-independent sampling. At the core of our model is a modular architecture comprising: (i) an encoding layer, adapted from protein folding models, that embeds protein-specific information and conformation at each time frame into a latent space; (ii) a temporal module, a sequence model that captures conformational dynamics across frames; and (iii) an SE(3) diffusion model as the structure decoder, generating conformations in continuous space. Experiments on ATLAS, a large-scale protein MD dataset of diverse structures, demonstrate the effectiveness of our model in learning conformational dynamics and supporting a wide range of downstream tasks. ConfRover is the first model to sample both protein conformations and trajectories within a single framework, offering a novel and flexible approach for learning from protein MD data.
Tensor Product Attention Is All You Need
Jan 11, 2025



Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models. The code is available at https://github.com/tensorgi/T6.
Towards Simple and Provable Parameter-Free Adaptive Gradient Methods
Dec 27, 2024



Optimization algorithms such as AdaGrad and Adam have significantly advanced the training of deep models by dynamically adjusting the learning rate during the optimization process. However, adhoc tuning of learning rates poses a challenge, leading to inefficiencies in practice. To address this issue, recent research has focused on developing "learning-rate-free" or "parameter-free" algorithms that operate effectively without the need for learning rate tuning. Despite these efforts, existing parameter-free variants of AdaGrad and Adam tend to be overly complex and/or lack formal convergence guarantees. In this paper, we present AdaGrad++ and Adam++, novel and simple parameter-free variants of AdaGrad and Adam with convergence guarantees. We prove that AdaGrad++ achieves comparable convergence rates to AdaGrad in convex optimization without predefined learning rate assumptions. Similarly, Adam++ matches the convergence rate of Adam without relying on any conditions on the learning rates. Experimental results across various deep learning tasks validate the competitive performance of AdaGrad++ and Adam++.
MARS: Unleashing the Power of Variance Reduction for Training Large Models
Nov 15, 2024



Training deep neural networks--and more recently, large models--demands efficient and scalable optimizers. Adaptive gradient algorithms like Adam, AdamW, and their variants have been central to this task. Despite the development of numerous variance reduction algorithms in the past decade aimed at accelerating stochastic optimization in both convex and nonconvex settings, variance reduction has not found widespread success in training deep neural networks or large language models. Consequently, it has remained a less favored approach in modern AI. In this paper, to unleash the power of variance reduction for efficient training of large models, we propose a unified optimization framework, MARS (Make vAriance Reduction Shine), which reconciles preconditioned gradient methods with variance reduction via a scaled stochastic recursive momentum technique. Within our framework, we introduce three instances of MARS that leverage preconditioned gradient updates based on AdamW, Lion, and Shampoo, respectively. We also draw a connection between our algorithms and existing optimizers. Experimental results on training GPT-2 models indicate that MARS consistently outperforms AdamW by a large margin.
Accelerated Preference Optimization for Large Language Model Alignment
Oct 08, 2024



Reinforcement Learning from Human Feedback (RLHF) has emerged as a pivotal tool for aligning large language models (LLMs) with human preferences. Direct Preference Optimization (DPO), one of the most popular approaches, formulates RLHF as a policy optimization problem without explicitly estimating the reward function. It overcomes the stability and efficiency issues of two-step approaches, which typically involve first estimating the reward function and then optimizing the policy via proximal policy optimization (PPO). Since RLHF is essentially an optimization problem, and it is well-known that momentum techniques can accelerate optimization both theoretically and empirically, a natural question arises: Can RLHF be accelerated by momentum? This paper answers this question in the affirmative. In detail, we first show that the iterative preference optimization method can be viewed as a proximal point method. Based on this observation, we propose a general Accelerated Preference Optimization (APO) framework, which unifies many existing preference optimization algorithms and employs Nesterov's momentum technique to speed up the alignment of LLMs. Theoretically, we demonstrate that APO can achieve a faster convergence rate than the standard iterative preference optimization methods, including DPO and Self-Play Preference Optimization (SPPO). Empirically, we show the superiority of APO over DPO, iterative DPO, and other strong baselines for RLHF on the AlpacaEval 2.0 benchmark.
Self-Play Preference Optimization for Language Model Alignment
May 01, 2024



Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed \textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Mar 21, 2024



The conformational landscape of proteins is crucial to understanding their functionality in complex biological processes. Traditional physics-based computational methods, such as molecular dynamics (MD) simulations, suffer from rare event sampling and long equilibration time problems, hindering their applications in general protein systems. Recently, deep generative modeling techniques, especially diffusion models, have been employed to generate novel protein conformations. However, existing score-based diffusion methods cannot properly incorporate important physical prior knowledge to guide the generation process, causing large deviations in the sampled protein conformations from the equilibrium distribution. In this paper, to overcome these limitations, we propose a force-guided SE(3) diffusion model, ConfDiff, for protein conformation generation. By incorporating a force-guided network with a mixture of data-based score models, ConfDiff can can generate protein conformations with rich diversity while preserving high fidelity. Experiments on a variety of protein conformation prediction tasks, including 12 fast-folding proteins and the Bovine Pancreatic Trypsin Inhibitor (BPTI), demonstrate that our method surpasses the state-of-the-art method.