 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Scaling Law for Quantization-Aware Training
May 20, 2025



Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
IP-MOT: Instance Prompt Learning for Cross-Domain Multi-Object Tracking
Oct 30, 2024Multi-Object Tracking (MOT) aims to associate multiple objects across video frames and is a challenging vision task due to inherent complexities in the tracking environment. Most existing approaches train and track within a single domain, resulting in a lack of cross-domain generalizability to data from other domains. While several works have introduced natural language representation to bridge the domain gap in visual tracking, these textual descriptions often provide too high-level a view and fail to distinguish various instances within the same class. In this paper, we address this limitation by developing IP-MOT, an end-to-end transformer model for MOT that operates without concrete textual descriptions. Our approach is underpinned by two key innovations: Firstly, leveraging a pre-trained vision-language model, we obtain instance-level pseudo textual descriptions via prompt-tuning, which are invariant across different tracking scenes; Secondly, we introduce a query-balanced strategy, augmented by knowledge distillation, to further boost the generalization capabilities of our model. Extensive experiments conducted on three widely used MOT benchmarks, including MOT17, MOT20, and DanceTrack, demonstrate that our approach not only achieves competitive performance on same-domain data compared to state-of-the-art models but also significantly improves the performance of query-based trackers by large margins for cross-domain inputs.
Selecting Influential Samples for Long Context Alignment via Homologous Models' Guidance and Contextual Awareness Measurement
Oct 21, 2024The expansion of large language models to effectively handle instructions with extremely long contexts has yet to be fully investigated. The primary obstacle lies in constructing a high-quality long instruction-following dataset devised for long context alignment. Existing studies have attempted to scale up the available data volume by synthesizing long instruction-following samples. However, indiscriminately increasing the quantity of data without a well-defined strategy for ensuring data quality may introduce low-quality samples and restrict the final performance. To bridge this gap, we aim to address the unique challenge of long-context alignment, i.e., modeling the long-range dependencies for handling instructions and lengthy input contexts. We propose GATEAU, a novel framework designed to identify the influential and high-quality samples enriched with long-range dependency relations by utilizing crafted Homologous Models' Guidance (HMG) and Contextual Awareness Measurement (CAM). Specifically, HMG attempts to measure the difficulty of generating corresponding responses due to the long-range dependencies, using the perplexity scores of the response from two homologous models with different context windows. Also, the role of CAM is to measure the difficulty of understanding the long input contexts due to long-range dependencies by evaluating whether the model's attention is focused on important segments. Built upon both proposed methods, we select the most challenging samples as the influential data to effectively frame the long-range dependencies, thereby achieving better performance of LLMs. Comprehensive experiments indicate that GATEAU effectively identifies samples enriched with long-range dependency relations and the model trained on these selected samples exhibits better instruction-following and long-context understanding capabilities.
Ruler: A Model-Agnostic Method to Control Generated Length for Large Language Models
Sep 27, 2024



The instruction-following ability of large language models enables humans to interact with AI agents in a natural way. However, when required to generate responses of a specific length, large language models often struggle to meet users' needs due to their inherent difficulty in accurately perceiving numerical constraints. To explore the ability of large language models to control the length of generated responses, we propose the Target Length Generation Task (TLG) and design two metrics, Precise Match (PM) and Flexible Match (FM) to evaluate the model's performance in adhering to specified response lengths. Furthermore, we introduce a novel, model-agnostic approach called Ruler, which employs Meta Length Tokens (MLTs) to enhance the instruction-following ability of large language models under length-constrained instructions. Specifically, Ruler equips LLMs with the ability to generate responses of a specified length based on length constraints within the instructions. Moreover, Ruler can automatically generate appropriate MLT when length constraints are not explicitly provided, demonstrating excellent versatility and generalization. Comprehensive experiments show the effectiveness of Ruler across different LLMs on Target Length Generation Task, e.g., at All Level 27.97 average gain on PM, 29.57 average gain on FM. In addition, we conduct extensive ablation experiments to further substantiate the efficacy and generalization of Ruler. Our code and data is available at https://github.com/Geaming2002/Ruler.
MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
Sep 09, 2024



The development of Multimodal Large Language Models (MLLMs) has seen significant advancements. However, the quantity and quality of multimodal instruction data have emerged as significant bottlenecks in their progress. Manually creating multimodal instruction data is both time-consuming and inefficient, posing challenges in producing instructions of high complexity. Moreover, distilling instruction data from black-box commercial models (e.g., GPT-4o, GPT-4V) often results in simplistic instruction data, which constrains performance to that of these models. The challenge of curating diverse and complex instruction data remains substantial. We propose MMEvol, a novel multimodal instruction data evolution framework that combines fine-grained perception evolution, cognitive reasoning evolution, and interaction evolution. This iterative approach breaks through data quality bottlenecks to generate a complex and diverse image-text instruction dataset, thereby empowering MLLMs with enhanced capabilities. Beginning with an initial set of instructions, SEED-163K, we utilize MMEvol to systematically broadens the diversity of instruction types, integrates reasoning steps to enhance cognitive capabilities, and extracts detailed information from images to improve visual understanding and robustness. To comprehensively evaluate the effectiveness of our data, we train LLaVA-NeXT using the evolved data and conduct experiments across 13 vision-language tasks. Compared to the baseline trained with seed data, our approach achieves an average accuracy improvement of 3.1 points and reaches state-of-the-art (SOTA) performance on 9 of these tasks.
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Jun 27, 2024
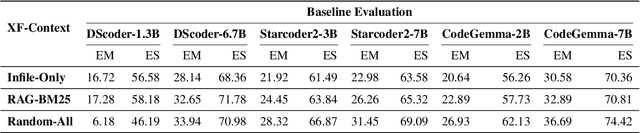
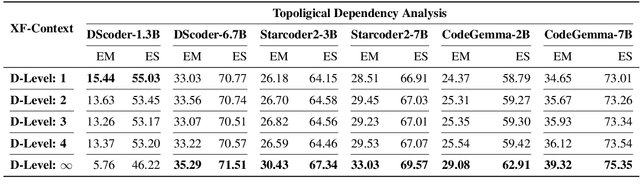
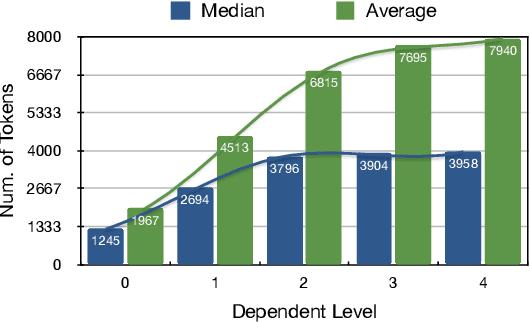
Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024



Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.