 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Benchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset
Nov 05, 2024



Machine unlearning has emerged as an effective strategy for forgetting specific information in the training data. However, with the increasing integration of visual data, privacy concerns in Vision Language Models (VLMs) remain underexplored. To address this, we introduce Facial Identity Unlearning Benchmark (FIUBench), a novel VLM unlearning benchmark designed to robustly evaluate the effectiveness of unlearning algorithms under the Right to be Forgotten setting. Specifically, we formulate the VLM unlearning task via constructing the Fictitious Facial Identity VQA dataset and apply a two-stage evaluation pipeline that is designed to precisely control the sources of information and their exposure levels. In terms of evaluation, since VLM supports various forms of ways to ask questions with the same semantic meaning, we also provide robust evaluation metrics including membership inference attacks and carefully designed adversarial privacy attacks to evaluate the performance of algorithms. Through the evaluation of four baseline VLM unlearning algorithms within FIUBench, we find that all methods remain limited in their unlearning performance, with significant trade-offs between model utility and forget quality. Furthermore, our findings also highlight the importance of privacy attacks for robust evaluations. We hope FIUBench will drive progress in developing more effective VLM unlearning algorithms.
Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Oct 24, 2024Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language model (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
From Text to Pixel: Advancing Long-Context Understanding in MLLMs
May 23, 2024



The rapid progress in Multimodal Large Language Models (MLLMs) has significantly advanced their ability to process and understand complex visual and textual information. However, the integration of multiple images and extensive textual contexts remains a challenge due to the inherent limitation of the models' capacity to handle long input sequences efficiently. In this paper, we introduce SEEKER, a multimodal large language model designed to tackle this issue. SEEKER aims to optimize the compact encoding of long text by compressing the text sequence into the visual pixel space via images, enabling the model to handle long text within a fixed token-length budget efficiently. Our empirical experiments on six long-context multimodal tasks demonstrate that SEEKER can leverage fewer image tokens to convey the same amount of textual information compared with the OCR-based approach, and is more efficient in understanding long-form multimodal input and generating long-form textual output, outperforming all existing proprietary and open-source MLLMs by large margins.
VIM: Probing Multimodal Large Language Models for Visual Embedded Instruction Following
Nov 29, 2023



We introduce VISUAL EMBEDDED INSTRUCTION (VIM), a new framework designed to evaluate the visual instruction following capability of Multimodal Large Language Models (MLLMs). As illustrated in Figure 2, VIM challenges the MLLMs by embedding the instructions into the visual scenes, demanding strong visual interpretative skills for instruction following. We adapt VIM to various benchmarks, including VQAv2, MME, MM-Vet, and RefCOCO series, compose a VIM bench, and probe diverse MLLMs across three distinct in-context learning settings: Zero Shot, One Shot, and Pair Shot. We observe that there is a significant performance disparity between the open-source MLLMs and GPT-4V, implying that their proficiency in visual instruction comprehension is not up to par. Our results highlight a promising direction for the enhancement of MLLMs capabilities on instruction following. We aim VIM to serve as a useful norm for advancing the state of the art and driving further progress in the field.
LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation
May 18, 2023



Existing automatic evaluation on text-to-image synthesis can only provide an image-text matching score, without considering the object-level compositionality, which results in poor correlation with human judgments. In this work, we propose LLMScore, a new framework that offers evaluation scores with multi-granularity compositionality. LLMScore leverages the large language models (LLMs) to evaluate text-to-image models. Initially, it transforms the image into image-level and object-level visual descriptions. Then an evaluation instruction is fed into the LLMs to measure the alignment between the synthesized image and the text, ultimately generating a score accompanied by a rationale. Our substantial analysis reveals the highest correlation of LLMScore with human judgments on a wide range of datasets (Attribute Binding Contrast, Concept Conjunction, MSCOCO, DrawBench, PaintSkills). Notably, our LLMScore achieves Kendall's tau correlation with human evaluations that is 58.8% and 31.2% higher than the commonly-used text-image matching metrics CLIP and BLIP, respectively.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
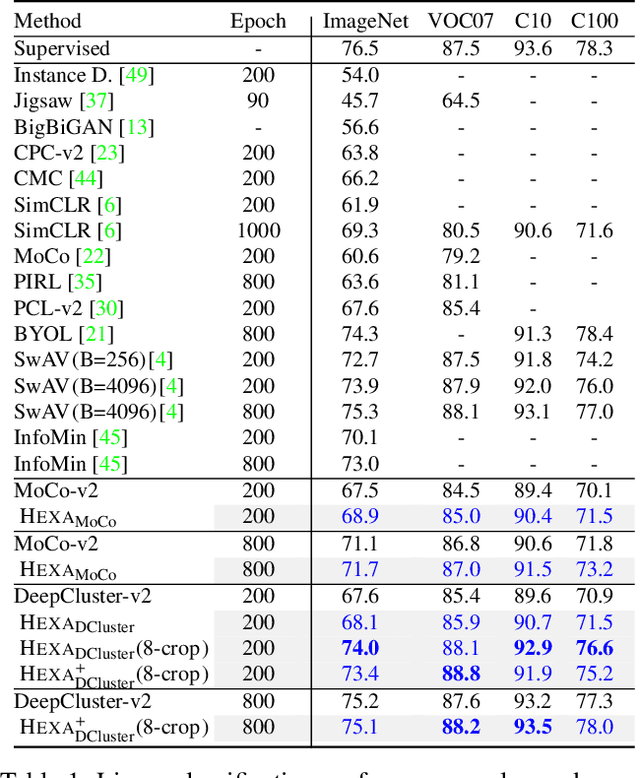
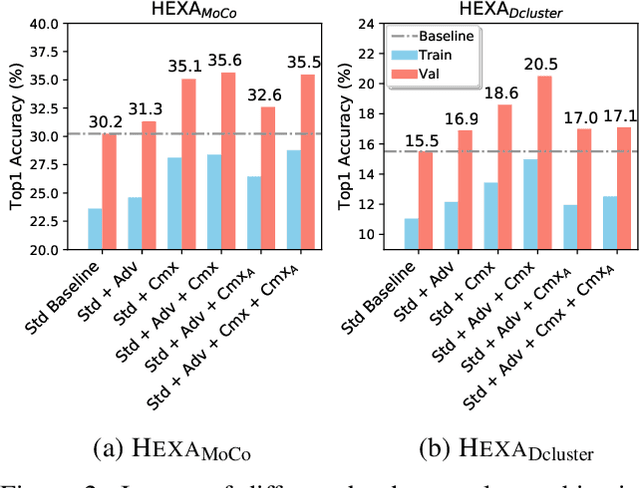
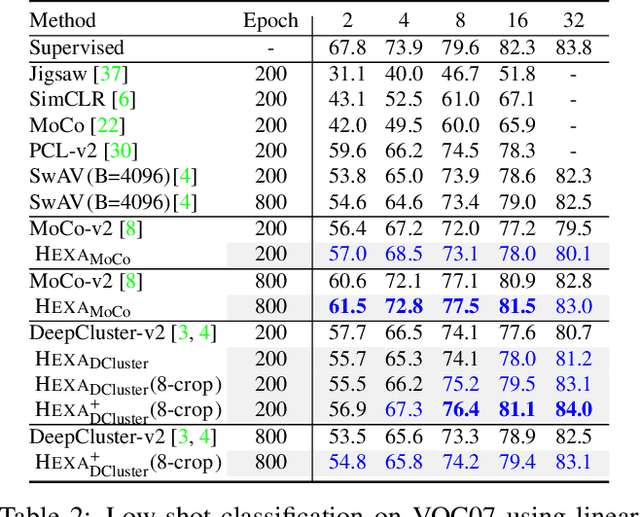
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
VinVL: Making Visual Representations Matter in Vision-Language Models
Jan 02, 2021


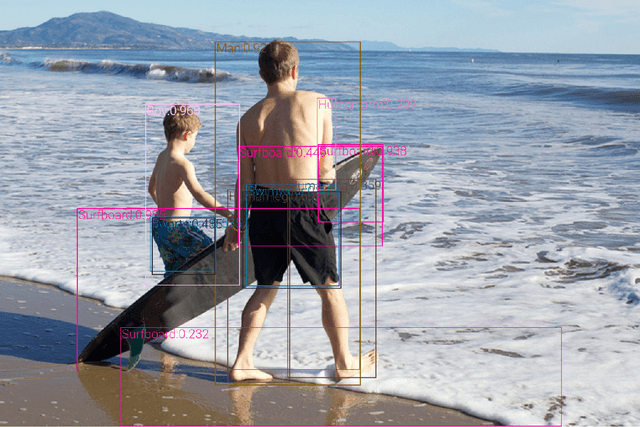
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up and top-down} model \cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets. Therefore, it can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses mainly on improving the vision-language fusion model and leaves the object detection model improvement untouched, we show that visual features matter significantly in VL models. In our experiments we feed the visual features generated by the new object detection model into a Transformer-based VL fusion model \oscar \cite{li2020oscar}, and utilize an improved approach \short\ to pre-train the VL model and fine-tune it on a wide range of downstream VL tasks. Our results show that the new visual features significantly improve the performance across all VL tasks, creating new state-of-the-art results on seven public benchmarks. We will release the new object detection model to public.
MiniVLM: A Smaller and Faster Vision-Language Model
Dec 13, 2020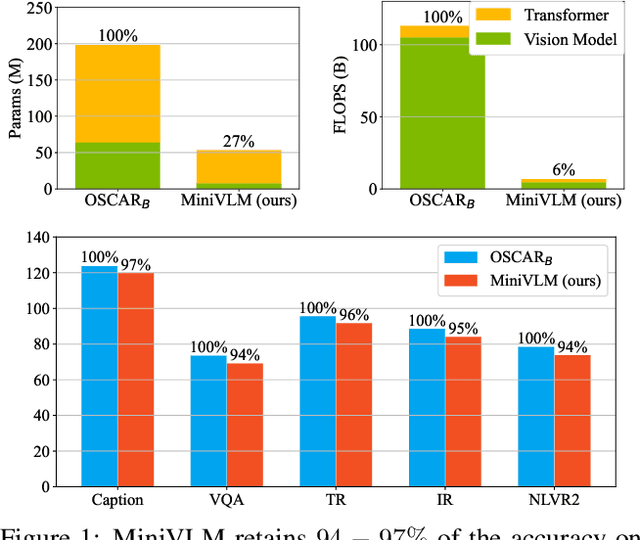
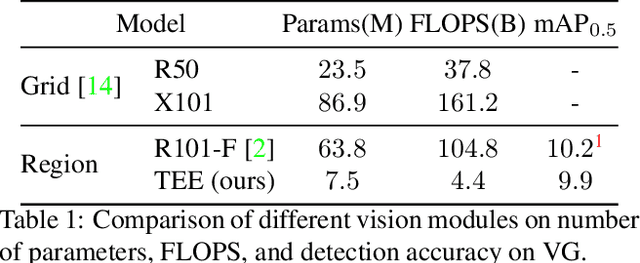
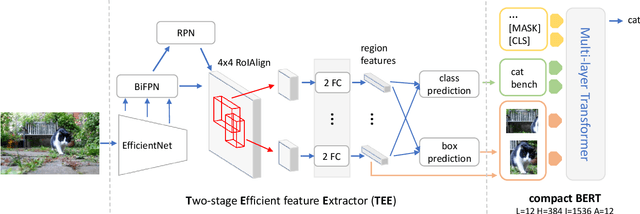
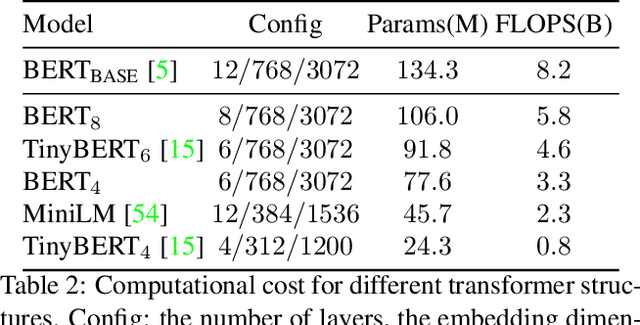
Recent vision-language (VL) studies have shown remarkable progress by learning generic representations from massive image-text pairs with transformer models and then fine-tuning on downstream VL tasks. While existing research has been focused on achieving high accuracy with large pre-trained models, building a lightweight model is of great value in practice but is less explored. In this paper, we propose a smaller and faster VL model, MiniVLM, which can be finetuned with good performance on various downstream tasks like its larger counterpart. MiniVLM consists of two modules, a vision feature extractor and a transformer-based vision-language fusion module. We design a Two-stage Efficient feature Extractor (TEE), inspired by the one-stage EfficientDet network, to significantly reduce the time cost of visual feature extraction by $95\%$, compared to a baseline model. We adopt the MiniLM structure to reduce the computation cost of the transformer module after comparing different compact BERT models. In addition, we improve the MiniVLM pre-training by adding $7M$ Open Images data, which are pseudo-labeled by a state-of-the-art captioning model. We also pre-train with high-quality image tags obtained from a strong tagging model to enhance cross-modality alignment. The large models are used offline without adding any overhead in fine-tuning and inference. With the above design choices, our MiniVLM reduces the model size by $73\%$ and the inference time cost by $94\%$ while being able to retain $94-97\%$ of the accuracy on multiple VL tasks. We hope that MiniVLM helps ease the use of the state-of-the-art VL research for on-the-edge applications.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
May 18, 2020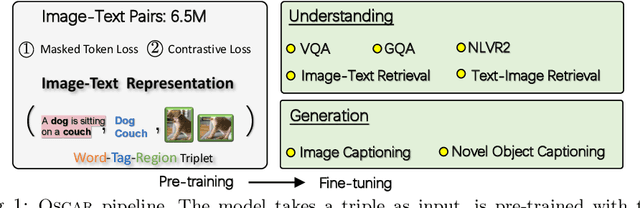

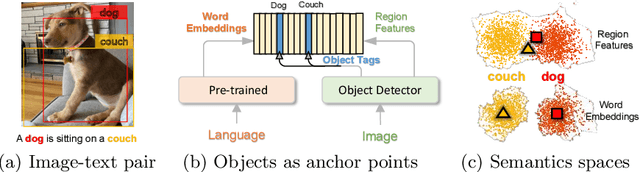
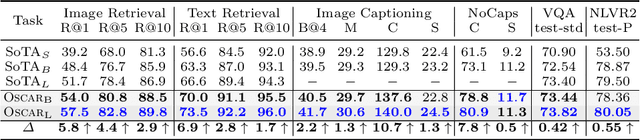
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.