 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSplats: 3D Generation by Denoising Splats-Based Multiview Diffusion Models
Dec 11, 2024



Generating high-quality 3D content requires models capable of learning robust distributions of complex scenes and the real-world objects within them. Recent Gaussian-based 3D reconstruction techniques have achieved impressive results in recovering high-fidelity 3D assets from sparse input images by predicting 3D Gaussians in a feed-forward manner. However, these techniques often lack the extensive priors and expressiveness offered by Diffusion Models. On the other hand, 2D Diffusion Models, which have been successfully applied to denoise multiview images, show potential for generating a wide range of photorealistic 3D outputs but still fall short on explicit 3D priors and consistency. In this work, we aim to bridge these two approaches by introducing DSplats, a novel method that directly denoises multiview images using Gaussian Splat-based Reconstructors to produce a diverse array of realistic 3D assets. To harness the extensive priors of 2D Diffusion Models, we incorporate a pretrained Latent Diffusion Model into the reconstructor backbone to predict a set of 3D Gaussians. Additionally, the explicit 3D representation embedded in the denoising network provides a strong inductive bias, ensuring geometrically consistent novel view generation. Our qualitative and quantitative experiments demonstrate that DSplats not only produces high-quality, spatially consistent outputs, but also sets a new standard in single-image to 3D reconstruction. When evaluated on the Google Scanned Objects dataset, DSplats achieves a PSNR of 20.38, an SSIM of 0.842, and an LPIPS of 0.109.
From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons
Dec 11, 2024We examine the capability of Multimodal Large Language Models (MLLMs) to tackle diverse domains that extend beyond the traditional language and vision tasks these models are typically trained on. Specifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning. To this end, we introduce a process of adapting an MLLM to a Generalist Embodied Agent (GEA). GEA is a single unified model capable of grounding itself across these varied domains through a multi-embodiment action tokenizer. GEA is trained with supervised learning on a large dataset of embodied experiences and with online RL in interactive simulators. We explore the data and algorithmic choices necessary to develop such a model. Our findings reveal the importance of training with cross-domain data and online RL for building generalist agents. The final GEA model achieves strong generalization performance to unseen tasks across diverse benchmarks compared to other generalist models and benchmark-specific approaches.
Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Oct 24, 2024Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language model (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
Grounding Multimodal Large Language Models in Actions
Jun 12, 2024



Multimodal Large Language Models (MLLMs) have demonstrated a wide range of capabilities across many domains, including Embodied AI. In this work, we study how to best ground a MLLM into different embodiments and their associated action spaces, with the goal of leveraging the multimodal world knowledge of the MLLM. We first generalize a number of methods through a unified architecture and the lens of action space adaptors. For continuous actions, we show that a learned tokenization allows for sufficient modeling precision, yielding the best performance on downstream tasks. For discrete actions, we demonstrate that semantically aligning these actions with the native output token space of the MLLM leads to the strongest performance. We arrive at these lessons via a thorough study of seven action space adapters on five different environments, encompassing over 114 embodied tasks.
Large Language Models as Generalizable Policies for Embodied Tasks
Oct 26, 2023



We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
Housekeep: Tidying Virtual Households using Commonsense Reasoning
May 22, 2022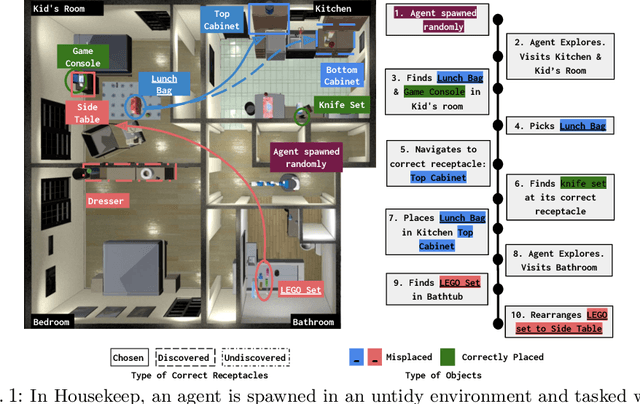
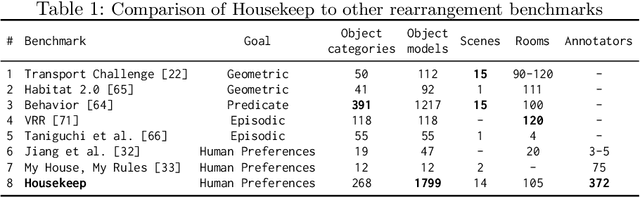
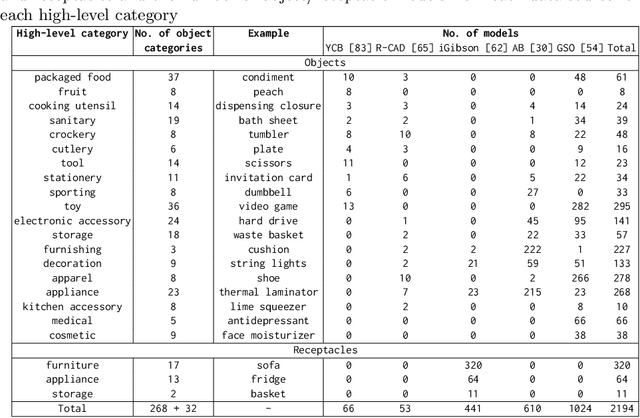
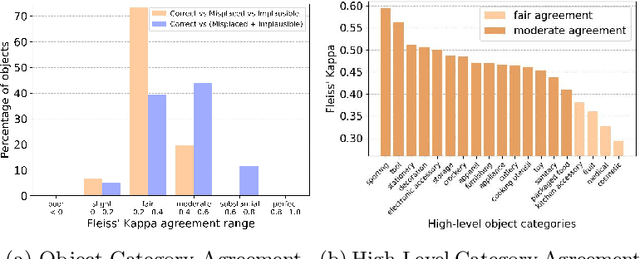
We introduce Housekeep, a benchmark to evaluate commonsense reasoning in the home for embodied AI. In Housekeep, an embodied agent must tidy a house by rearranging misplaced objects without explicit instructions specifying which objects need to be rearranged. Instead, the agent must learn from and is evaluated against human preferences of which objects belong where in a tidy house. Specifically, we collect a dataset of where humans typically place objects in tidy and untidy houses constituting 1799 objects, 268 object categories, 585 placements, and 105 rooms. Next, we propose a modular baseline approach for Housekeep that integrates planning, exploration, and navigation. It leverages a fine-tuned large language model (LLM) trained on an internet text corpus for effective planning. We show that our baseline agent generalizes to rearranging unseen objects in unknown environments. See our webpage for more details: https://yashkant.github.io/housekeep/
Simple and Effective Synthesis of Indoor 3D Scenes
Apr 06, 2022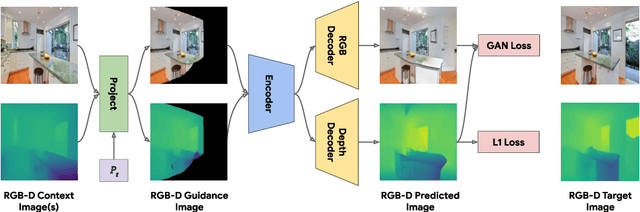
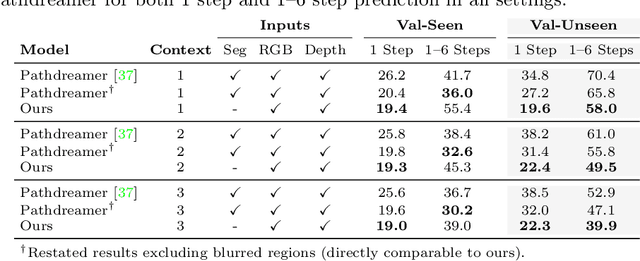


We study the problem of synthesizing immersive 3D indoor scenes from one or more images. Our aim is to generate high-resolution images and videos from novel viewpoints, including viewpoints that extrapolate far beyond the input images while maintaining 3D consistency. Existing approaches are highly complex, with many separately trained stages and components. We propose a simple alternative: an image-to-image GAN that maps directly from reprojections of incomplete point clouds to full high-resolution RGB-D images. On the Matterport3D and RealEstate10K datasets, our approach significantly outperforms prior work when evaluated by humans, as well as on FID scores. Further, we show that our model is useful for generative data augmentation. A vision-and-language navigation (VLN) agent trained with trajectories spatially-perturbed by our model improves success rate by up to 1.5% over a state of the art baseline on the R2R benchmark. Our code will be made available to facilitate generative data augmentation and applications to downstream robotics and embodied AI tasks.
SOAT: A Scene- and Object-Aware Transformer for Vision-and-Language Navigation
Oct 27, 2021
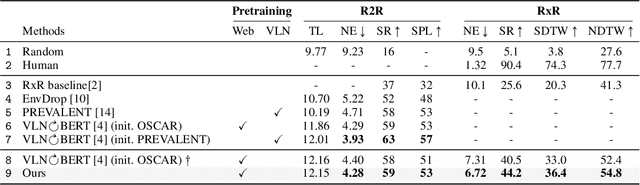
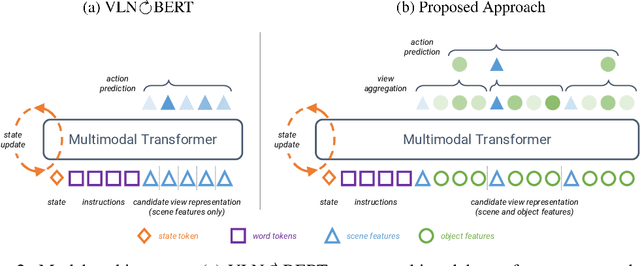
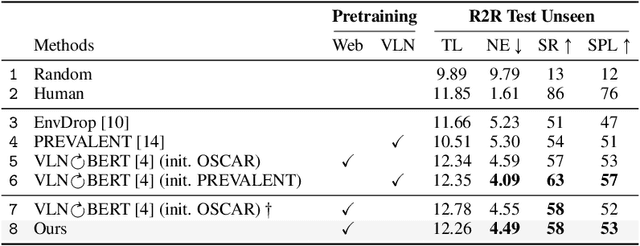
Natural language instructions for visual navigation often use scene descriptions (e.g., "bedroom") and object references (e.g., "green chairs") to provide a breadcrumb trail to a goal location. This work presents a transformer-based vision-and-language navigation (VLN) agent that uses two different visual encoders -- a scene classification network and an object detector -- which produce features that match these two distinct types of visual cues. In our method, scene features contribute high-level contextual information that supports object-level processing. With this design, our model is able to use vision-and-language pretraining (i.e., learning the alignment between images and text from large-scale web data) to substantially improve performance on the Room-to-Room (R2R) and Room-Across-Room (RxR) benchmarks. Specifically, our approach leads to improvements of 1.8% absolute in SPL on R2R and 3.7% absolute in SR on RxR. Our analysis reveals even larger gains for navigation instructions that contain six or more object references, which further suggests that our approach is better able to use object features and align them to references in the instructions.
The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
Aug 26, 2021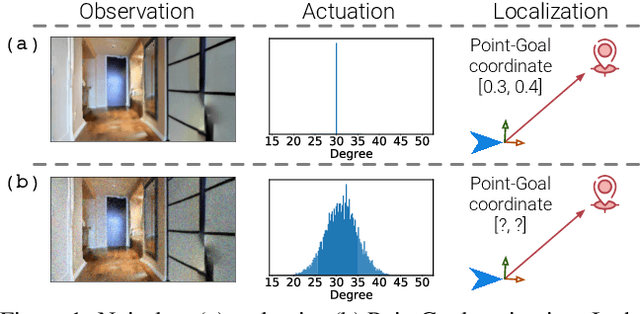
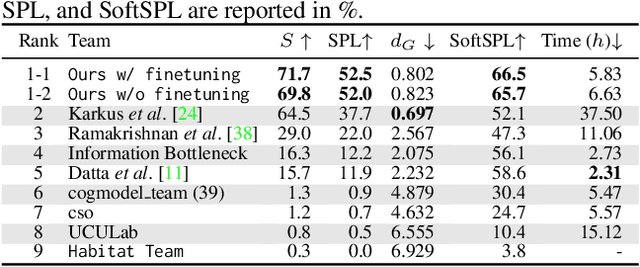
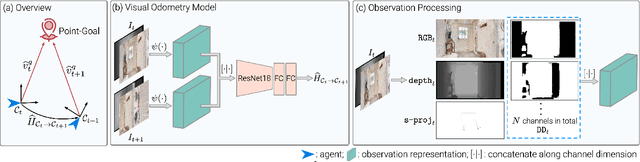
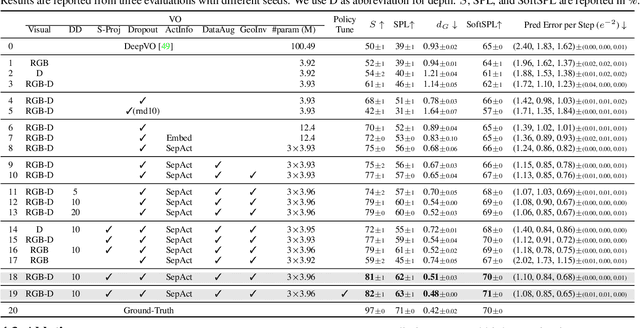
It is fundamental for personal robots to reliably navigate to a specified goal. To study this task, PointGoal navigation has been introduced in simulated Embodied AI environments. Recent advances solve this PointGoal navigation task with near-perfect accuracy (99.6% success) in photo-realistically simulated environments, assuming noiseless egocentric vision, noiseless actuation, and most importantly, perfect localization. However, under realistic noise models for visual sensors and actuation, and without access to a "GPS and Compass sensor," the 99.6%-success agents for PointGoal navigation only succeed with 0.3%. In this work, we demonstrate the surprising effectiveness of visual odometry for the task of PointGoal navigation in this realistic setting, i.e., with realistic noise models for perception and actuation and without access to GPS and Compass sensors. We show that integrating visual odometry techniques into navigation policies improves the state-of-the-art on the popular Habitat PointNav benchmark by a large margin, improving success from 64.5% to 71.7% while executing 6.4 times faster.
Contrast and Classify: Alternate Training for Robust VQA
Oct 13, 2020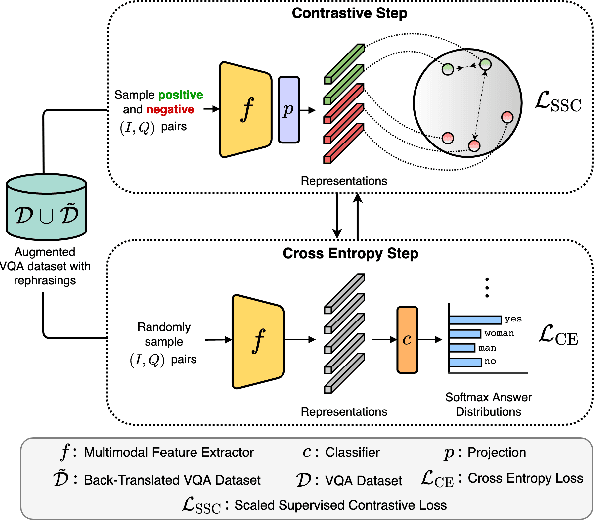
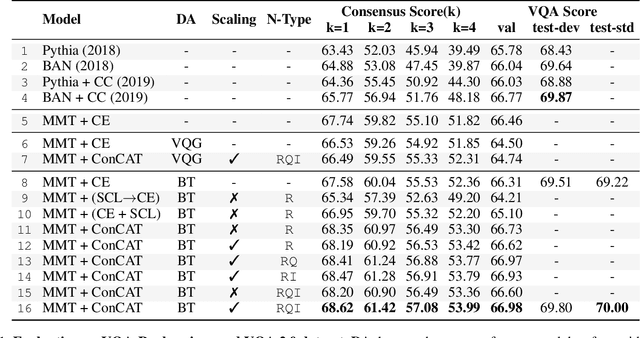
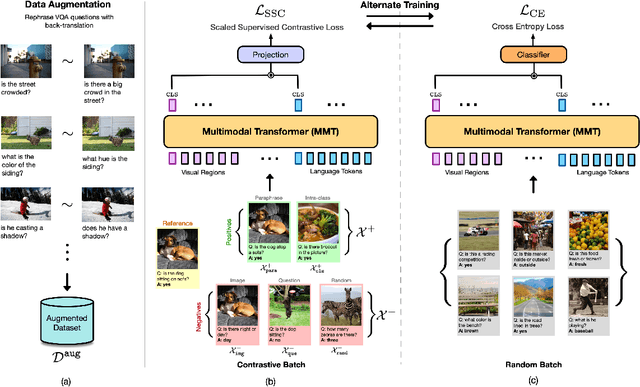
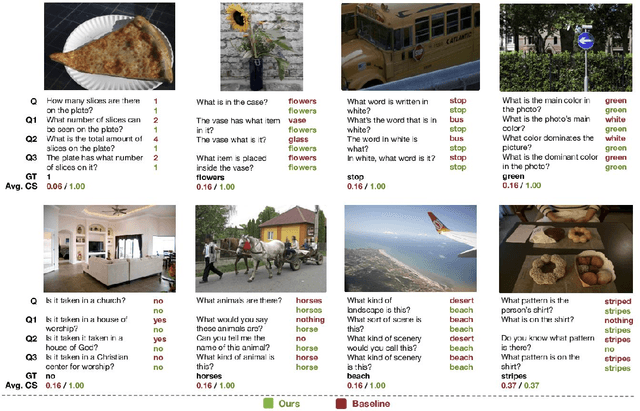
Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage the augmented data, we build on the recent success in contrastive learning. We propose a novel training paradigm (ConCAT) that alternately optimizes cross-entropy and contrastive losses. The contrastive loss encourages representations to be robust to linguistic variations in questions while the cross-entropy loss preserves the discriminative power of the representations for answer classification. We find that alternately optimizing both losses is key to effective training. VQA models trained with ConCAT achieve higher consensus scores on the VQA-Rephrasings dataset as well as higher VQA accuracy on the VQA 2.0 dataset compared to existing approaches across a variety of data augmentation strategies.