 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning
Mar 22, 2024



This paper introduces Scene-LLM, a 3D-visual-language model that enhances embodied agents' abilities in interactive 3D indoor environments by integrating the reasoning strengths of Large Language Models (LLMs). Scene-LLM adopts a hybrid 3D visual feature representation, that incorporates dense spatial information and supports scene state updates. The model employs a projection layer to efficiently project these features in the pre-trained textual embedding space, enabling effective interpretation of 3D visual information. Unique to our approach is the integration of both scene-level and ego-centric 3D information. This combination is pivotal for interactive planning, where scene-level data supports global planning and ego-centric data is important for localization. Notably, we use ego-centric 3D frame features for feature alignment, an efficient technique that enhances the model's ability to align features of small objects within the scene. Our experiments with Scene-LLM demonstrate its strong capabilities in dense captioning, question answering, and interactive planning. We believe Scene-LLM advances the field of 3D visual understanding and reasoning, offering new possibilities for sophisticated agent interactions in indoor settings.
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023



Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Efficient Open Domain Multi-Hop Question Answering with Few-Shot Data Synthesis
May 23, 2023



Few-shot learning for open domain multi-hop question answering typically relies on large language models (LLMs). While powerful, LLMs are inefficient at the inference time. We propose a data synthesis framework for multi-hop question answering that allows for improving smaller language models with less than 10 human-annotated question answer pairs. The framework is built upon the data generation functions parameterized by LLMs and prompts, which requires minimal hand-crafted features. Empirically, we synthesize millions of multi-hop questions and claims. After finetuning language models on the synthetic data, we evaluate the models on popular benchmarks on multi-hop question answering and fact verification. Our experimental results show that finetuning on the synthetic data improves model performance significantly, allowing our finetuned models to be competitive with prior models while being almost one-third the size in terms of parameter counts.
VideoOFA: Two-Stage Pre-Training for Video-to-Text Generation
May 04, 2023



We propose a new two-stage pre-training framework for video-to-text generation tasks such as video captioning and video question answering: A generative encoder-decoder model is first jointly pre-trained on massive image-text data to learn fundamental vision-language concepts, and then adapted to video data in an intermediate video-text pre-training stage to learn video-specific skills such as spatio-temporal reasoning. As a result, our VideoOFA model achieves new state-of-the-art performance on four Video Captioning benchmarks, beating prior art by an average of 9.7 points in CIDEr score. It also outperforms existing models on two open-ended Video Question Answering datasets, showcasing its generalization capability as a universal video-to-text model.
Hierarchical Video-Moment Retrieval and Step-Captioning
Mar 29, 2023



There is growing interest in searching for information from large video corpora. Prior works have studied relevant tasks, such as text-based video retrieval, moment retrieval, video summarization, and video captioning in isolation, without an end-to-end setup that can jointly search from video corpora and generate summaries. Such an end-to-end setup would allow for many interesting applications, e.g., a text-based search that finds a relevant video from a video corpus, extracts the most relevant moment from that video, and segments the moment into important steps with captions. To address this, we present the HiREST (HIerarchical REtrieval and STep-captioning) dataset and propose a new benchmark that covers hierarchical information retrieval and visual/textual stepwise summarization from an instructional video corpus. HiREST consists of 3.4K text-video pairs from an instructional video dataset, where 1.1K videos have annotations of moment spans relevant to text query and breakdown of each moment into key instruction steps with caption and timestamps (totaling 8.6K step captions). Our hierarchical benchmark consists of video retrieval, moment retrieval, and two novel moment segmentation and step captioning tasks. In moment segmentation, models break down a video moment into instruction steps and identify start-end boundaries. In step captioning, models generate a textual summary for each step. We also present starting point task-specific and end-to-end joint baseline models for our new benchmark. While the baseline models show some promising results, there still exists large room for future improvement by the community. Project website: https://hirest-cvpr2023.github.io
How to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval
Feb 15, 2023



Various techniques have been developed in recent years to improve dense retrieval (DR), such as unsupervised contrastive learning and pseudo-query generation. Existing DRs, however, often suffer from effectiveness tradeoffs between supervised and zero-shot retrieval, which some argue was due to the limited model capacity. We contradict this hypothesis and show that a generalizable DR can be trained to achieve high accuracy in both supervised and zero-shot retrieval without increasing model size. In particular, we systematically examine the contrastive learning of DRs, under the framework of Data Augmentation (DA). Our study shows that common DA practices such as query augmentation with generative models and pseudo-relevance label creation using a cross-encoder, are often inefficient and sub-optimal. We hence propose a new DA approach with diverse queries and sources of supervision to progressively train a generalizable DR. As a result, DRAGON, our dense retriever trained with diverse augmentation, is the first BERT-base-sized DR to achieve state-of-the-art effectiveness in both supervised and zero-shot evaluations and even competes with models using more complex late interaction (ColBERTv2 and SPLADE++).
Nonparametric Masked Language Modeling
Dec 02, 2022Existing language models (LMs) predict tokens with a softmax over a finite vocabulary, which can make it difficult to predict rare tokens or phrases. We introduce NPM, the first nonparametric masked language model that replaces this softmax with a nonparametric distribution over every phrase in a reference corpus. We show that NPM can be efficiently trained with a contrastive objective and an in-batch approximation to full corpus retrieval. Zero-shot evaluation on 9 closed-set tasks and 7 open-set tasks demonstrates that NPM outperforms significantly larger parametric models, either with or without a retrieve-and-generate approach. It is particularly better on dealing with rare patterns (word senses or facts), and predicting rare or nearly unseen words (e.g., non-Latin script). We release the model and code at github.com/facebookresearch/NPM.
CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
Nov 18, 2022



Multi-vector retrieval methods combine the merits of sparse (e.g. BM25) and dense (e.g. DPR) retrievers and have achieved state-of-the-art performance on various retrieval tasks. These methods, however, are orders of magnitude slower and need much more space to store their indices compared to their single-vector counterparts. In this paper, we unify different multi-vector retrieval models from a token routing viewpoint and propose conditional token interaction via dynamic lexical routing, namely CITADEL, for efficient and effective multi-vector retrieval. CITADEL learns to route different token vectors to the predicted lexical ``keys'' such that a query token vector only interacts with document token vectors routed to the same key. This design significantly reduces the computation cost while maintaining high accuracy. Notably, CITADEL achieves the same or slightly better performance than the previous state of the art, ColBERT-v2, on both in-domain (MS MARCO) and out-of-domain (BEIR) evaluations, while being nearly 40 times faster. Code and data are available at https://github.com/facebookresearch/dpr-scale.
Task-aware Retrieval with Instructions
Nov 16, 2022



We study the problem of retrieval with instructions, where users of a retrieval system explicitly describe their intent along with their queries, making the system task-aware. We aim to develop a general-purpose task-aware retrieval systems using multi-task instruction tuning that can follow human-written instructions to find the best documents for a given query. To this end, we introduce the first large-scale collection of approximately 40 retrieval datasets with instructions, and present TART, a multi-task retrieval system trained on the diverse retrieval tasks with instructions. TART shows strong capabilities to adapt to a new task via instructions and advances the state of the art on two zero-shot retrieval benchmarks, BEIR and LOTTE, outperforming models up to three times larger. We further introduce a new evaluation setup to better reflect real-world scenarios, pooling diverse documents and tasks. In this setup, TART significantly outperforms competitive baselines, further demonstrating the effectiveness of guiding retrieval with instructions.
A Study on the Efficiency and Generalization of Light Hybrid Retrievers
Oct 04, 2022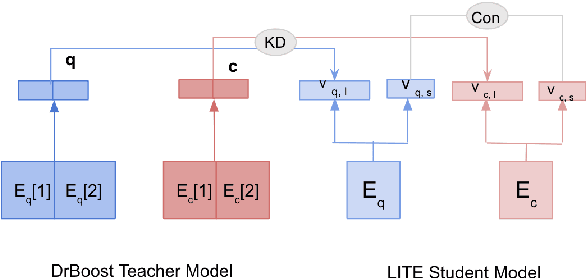
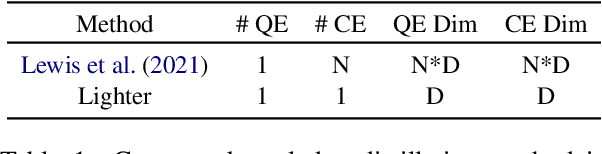
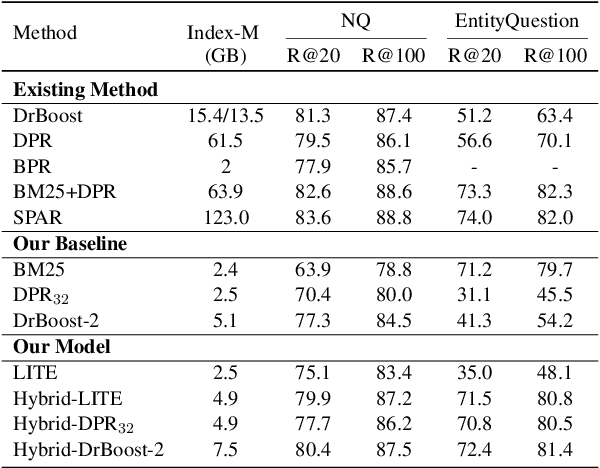
Existing hybrid retrievers which integrate sparse and dense retrievers, are indexing-heavy, limiting their applicability in real-world on-devices settings. We ask the question "Is it possible to reduce the indexing memory of hybrid retrievers without sacrificing performance?" Driven by this question, we leverage an indexing-efficient dense retriever (i.e. DrBoost) to obtain a light hybrid retriever. Moreover, to further reduce the memory, we introduce a lighter dense retriever (LITE) which is jointly trained on contrastive learning and knowledge distillation from DrBoost. Compared to previous heavy hybrid retrievers, our Hybrid-LITE retriever saves 13 memory while maintaining 98.0 performance. In addition, we study the generalization of light hybrid retrievers along two dimensions, out-of-domain (OOD) generalization and robustness against adversarial attacks. We evaluate models on two existing OOD benchmarks and create six adversarial attack sets for robustness evaluation. Experiments show that our light hybrid retrievers achieve better robustness performance than both sparse and dense retrievers. Nevertheless there is a large room to improve the robustness of retrievers, and our datasets can aid future research.