 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automatic Verification of Image-Text Claims (AVerImaTeC) Shared Task
Feb 11, 2026The Automatic Verification of Image-Text Claims (AVerImaTeC) shared task aims to advance system development for retrieving evidence and verifying real-world image-text claims. Participants were allowed to either employ external knowledge sources, such as web search engines, or leverage the curated knowledge store provided by the organizers. System performance was evaluated using the AVerImaTeC score, defined as a conditional verdict accuracy in which a verdict is considered correct only when the associated evidence score exceeds a predefined threshold. The shared task attracted 14 submissions during the development phase and 6 submissions during the testing phase. All participating systems in the testing phase outperformed the baseline provided. The winning team, HUMANE, achieved an AVerImaTeC score of 0.5455. This paper provides a detailed description of the shared task, presents the complete evaluation results, and discusses key insights and lessons learned.
Social Good or Scientific Curiosity? Uncovering the Research Framing Behind NLP Artefacts
May 24, 2025



Clarifying the research framing of NLP artefacts (e.g., models, datasets, etc.) is crucial to aligning research with practical applications. Recent studies manually analyzed NLP research across domains, showing that few papers explicitly identify key stakeholders, intended uses, or appropriate contexts. In this work, we propose to automate this analysis, developing a three-component system that infers research framings by first extracting key elements (means, ends, stakeholders), then linking them through interpretable rules and contextual reasoning. We evaluate our approach on two domains: automated fact-checking using an existing dataset, and hate speech detection for which we annotate a new dataset-achieving consistent improvements over strong LLM baselines. Finally, we apply our system to recent automated fact-checking papers and uncover three notable trends: a rise in vague or underspecified research goals, increased emphasis on scientific exploration over application, and a shift toward supporting human fact-checkers rather than pursuing full automation.
AVerImaTeC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the Web
May 23, 2025Textual claims are often accompanied by images to enhance their credibility and spread on social media, but this also raises concerns about the spread of misinformation. Existing datasets for automated verification of image-text claims remain limited, as they often consist of synthetic claims and lack evidence annotations to capture the reasoning behind the verdict. In this work, we introduce AVerImaTeC, a dataset consisting of 1,297 real-world image-text claims. Each claim is annotated with question-answer (QA) pairs containing evidence from the web, reflecting a decomposed reasoning regarding the verdict. We mitigate common challenges in fact-checking datasets such as contextual dependence, temporal leakage, and evidence insufficiency, via claim normalization, temporally constrained evidence annotation, and a two-stage sufficiency check. We assess the consistency of the annotation in AVerImaTeC via inter-annotator studies, achieving a $\kappa=0.742$ on verdicts and $74.7\%$ consistency on QA pairs. We also propose a novel evaluation method for evidence retrieval and conduct extensive experiments to establish baselines for verifying image-text claims using open-web evidence.
Decompose and Leverage Preferences from Expert Models for Improving Trustworthiness of MLLMs
Nov 20, 2024



Multimodal Large Language Models (MLLMs) can enhance trustworthiness by aligning with human preferences. As human preference labeling is laborious, recent works employ evaluation models for assessing MLLMs' responses, using the model-based assessments to automate preference dataset construction. This approach, however, faces challenges with MLLMs' lengthy and compositional responses, which often require diverse reasoning skills that a single evaluation model may not fully possess. Additionally, most existing methods rely on closed-source models as evaluators. To address limitations, we propose DecompGen, a decomposable framework that uses an ensemble of open-sourced expert models. DecompGen breaks down each response into atomic verification tasks, assigning each task to an appropriate expert model to generate fine-grained assessments. The DecompGen feedback is used to automatically construct our preference dataset, DGPref. MLLMs aligned with DGPref via preference learning show improvements in trustworthiness, demonstrating the effectiveness of DecompGen.
Ev2R: Evaluating Evidence Retrieval in Automated Fact-Checking
Nov 08, 2024



Current automated fact-checking (AFC) approaches commonly evaluate evidence either implicitly via the predicted verdicts or by comparing retrieved evidence with a predefined closed knowledge source, such as Wikipedia. However, these methods suffer from limitations, resulting from their reliance on evaluation metrics developed for different purposes and constraints imposed by closed knowledge sources. Recent advances in natural language generation (NLG) evaluation offer new possibilities for evidence assessment. In this work, we introduce Ev2R, an evaluation framework for AFC that comprises three types of approaches for evidence evaluation: reference-based, proxy-reference, and reference-less. We evaluate their effectiveness through agreement with human ratings and adversarial tests, and demonstrate that prompt-based scorers, particularly those leveraging LLMs and reference evidence, outperform traditional evaluation approaches.
The Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
Generating Media Background Checks for Automated Source Critical Reasoning
Sep 01, 2024



Not everything on the internet is true. This unfortunate fact requires both humans and models to perform complex reasoning about credibility when working with retrieved information. In NLP, this problem has seen little attention. Indeed, retrieval-augmented models are not typically expected to distrust retrieved documents. Human experts overcome the challenge by gathering signals about the context, reliability, and tendency of source documents - that is, they perform source criticism. We propose a novel NLP task focused on finding and summarising such signals. We introduce a new dataset of 6,709 "media background checks" derived from Media Bias / Fact Check, a volunteer-run website documenting media bias. We test open-source and closed-source LLM baselines with and without retrieval on this dataset, finding that retrieval greatly improves performance. We furthermore carry out human evaluation, demonstrating that 1) media background checks are helpful for humans, and 2) media background checks are helpful for retrieval-augmented models.
AVeriTeC: A Dataset for Real-world Claim Verification with Evidence from the Web
May 24, 2023Existing datasets for automated fact-checking have substantial limitations, such as relying on artificial claims, lacking annotations for evidence and intermediate reasoning, or including evidence published after the claim. In this paper we introduce AVeriTeC, a new dataset of 4,568 real-world claims covering fact-checks by 50 different organizations. Each claim is annotated with question-answer pairs supported by evidence available online, as well as textual justifications explaining how the evidence combines to produce a verdict. Through a multi-round annotation process, we avoid common pitfalls including context dependence, evidence insufficiency, and temporal leakage, and reach a substantial inter-annotator agreement of $\kappa=0.619$ on verdicts. We develop a baseline as well as an evaluation scheme for verifying claims through several question-answering steps against the open web.
The Intended Uses of Automated Fact-Checking Artefacts: Why, How and Who
Apr 27, 2023Automated fact-checking is often presented as an epistemic tool that fact-checkers, social media consumers, and other stakeholders can use to fight misinformation. Nevertheless, few papers thoroughly discuss how. We document this by analysing 100 highly-cited papers, and annotating epistemic elements related to intended use, i.e., means, ends, and stakeholders. We find that narratives leaving out some of these aspects are common, that many papers propose inconsistent means and ends, and that the feasibility of suggested strategies rarely has empirical backing. We argue that this vagueness actively hinders the technology from reaching its goals, as it encourages overclaiming, limits criticism, and prevents stakeholder feedback. Accordingly, we provide several recommendations for thinking and writing about the use of fact-checking artefacts.
A Survey on Automated Fact-Checking
Aug 26, 2021
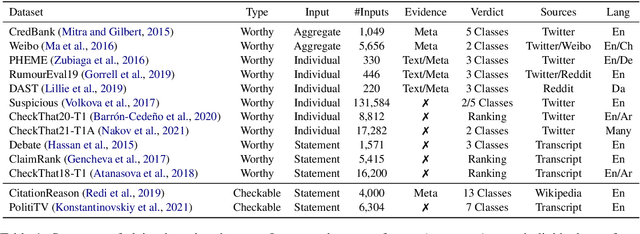
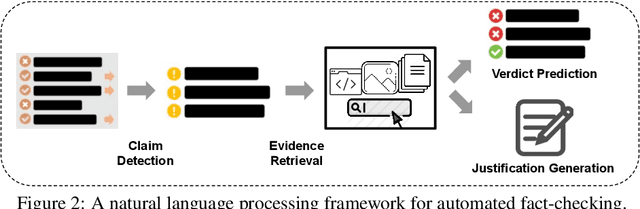
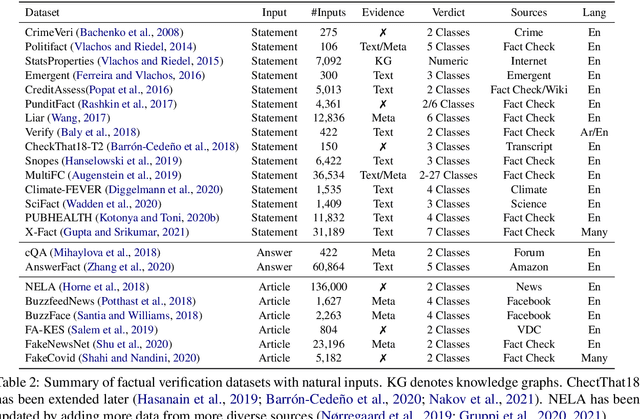
Fact-checking has become increasingly important due to the speed with which both information and misinformation can spread in the modern media ecosystem. Therefore, researchers have been exploring how fact-checking can be automated, using techniques based on natural language processing, machine learning, knowledge representation, and databases to automatically predict the veracity of claims. In this paper, we survey automated fact-checking stemming from natural language processing, and discuss its connections to related tasks and disciplines. In this process, we present an overview of existing datasets and models, aiming to unify the various definitions given and identify common concepts. Finally, we highlight challenges for future research.