 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Data, Long Context: Distilling Positional Knowledge in Transformers
Apr 07, 2026Extending the context window of language models typically requires expensive long-context pre-training, posing significant challenges for both training efficiency and data collection. In this paper, we present evidence that long-context retrieval capabilities can be transferred to student models through logit-based knowledge distillation, even when training exclusively on packed short-context samples within a long-context window. We provide comprehensive insights through the lens of Rotary Position Embedding (RoPE) and establish three key findings. First, consistent with prior work, we show that phase-wise RoPE scaling, which maximizes rotational spectrum utilization at each training stage, also achieves the best long-context performance in knowledge distillation setups. Second, we demonstrate that logit-based knowledge distillation can directly enable positional information transfer. Using an experimental setup with packed repeated token sequences, we trace the propagation of positional perturbations from query and key vectors through successive transformer layers to output logits, revealing that positional information systematically influences the teacher's output distribution and, in turn, the distillation signal received by the student model. Third, our analysis uncovers structured update patterns in the query state during long-context extension, with distinct parameter spans exhibiting strong sensitivity to long-context training.
MobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Scaling Parameter-Constrained Language Models with Quality Data
Oct 04, 2024



Scaling laws in language modeling traditionally quantify training loss as a function of dataset size and model parameters, providing compute-optimal estimates but often neglecting the impact of data quality on model generalization. In this paper, we extend the conventional understanding of scaling law by offering a microscopic view of data quality within the original formulation -- effective training tokens -- which we posit to be a critical determinant of performance for parameter-constrained language models. Specifically, we formulate the proposed term of effective training tokens to be a combination of two readily-computed indicators of text: (i) text diversity and (ii) syntheticity as measured by a teacher model. We pretrained over $200$ models of 25M to 1.5B parameters on a diverse set of sampled, synthetic data, and estimated the constants that relate text quality, model size, training tokens, and eight reasoning task accuracy scores. We demonstrated the estimated constants yield +0.83 Pearson correlation with true accuracies, and analyzed it in scenarios involving widely-used data techniques such as data sampling and synthesis which aim to improve data quality.
CoDi: Conversational Distillation for Grounded Question Answering
Aug 20, 2024



Distilling conversational skills into Small Language Models (SLMs) with approximately 1 billion parameters presents significant challenges. Firstly, SLMs have limited capacity in their model parameters to learn extensive knowledge compared to larger models. Secondly, high-quality conversational datasets are often scarce, small, and domain-specific. Addressing these challenges, we introduce a novel data distillation framework named CoDi (short for Conversational Distillation, pronounced "Cody"), allowing us to synthesize large-scale, assistant-style datasets in a steerable and diverse manner. Specifically, while our framework is task agnostic at its core, we explore and evaluate the potential of CoDi on the task of conversational grounded reasoning for question answering. This is a typical on-device scenario for specialist SLMs, allowing for open-domain model responses, without requiring the model to "memorize" world knowledge in its limited weights. Our evaluations show that SLMs trained with CoDi-synthesized data achieve performance comparable to models trained on human-annotated data in standard metrics. Additionally, when using our framework to generate larger datasets from web data, our models surpass larger, instruction-tuned models in zero-shot conversational grounded reasoning tasks.
Small But Funny: A Feedback-Driven Approach to Humor Distillation
Feb 28, 2024



The emergence of Large Language Models (LLMs) has brought to light promising language generation capabilities, particularly in performing tasks like complex reasoning and creative writing. Consequently, distillation through imitation of teacher responses has emerged as a popular technique to transfer knowledge from LLMs to more accessible, Small Language Models (SLMs). While this works well for simpler tasks, there is a substantial performance gap on tasks requiring intricate language comprehension and creativity, such as humor generation. We hypothesize that this gap may stem from the fact that creative tasks might be hard to learn by imitation alone and explore whether an approach, involving supplementary guidance from the teacher, could yield higher performance. To address this, we study the effect of assigning a dual role to the LLM - as a "teacher" generating data, as well as a "critic" evaluating the student's performance. Our experiments on humor generation reveal that the incorporation of feedback significantly narrows the performance gap between SLMs and their larger counterparts compared to merely relying on imitation. As a result, our research highlights the potential of using feedback as an additional dimension to data when transferring complex language abilities via distillation.
Large Language Models as Zero-shot Dialogue State Tracker through Function Calling
Feb 16, 2024



Large language models (LLMs) are increasingly prevalent in conversational systems due to their advanced understanding and generative capabilities in general contexts. However, their effectiveness in task-oriented dialogues (TOD), which requires not only response generation but also effective dialogue state tracking (DST) within specific tasks and domains, remains less satisfying. In this work, we propose a novel approach FnCTOD for solving DST with LLMs through function calling. This method improves zero-shot DST, allowing adaptation to diverse domains without extensive data collection or model tuning. Our experimental results demonstrate that our approach achieves exceptional performance with both modestly sized open-source and also proprietary LLMs: with in-context prompting it enables various 7B or 13B parameter models to surpass the previous state-of-the-art (SOTA) achieved by ChatGPT, and improves ChatGPT's performance beating the SOTA by 5.6% Avg. JGA. Individual model results for GPT-3.5 and GPT-4 are boosted by 4.8% and 14%, respectively. We also show that by fine-tuning on a small collection of diverse task-oriented dialogues, we can equip modestly sized models, specifically a 13B parameter LLaMA2-Chat model, with function-calling capabilities and DST performance comparable to ChatGPT while maintaining their chat capabilities. We plan to open-source experimental code and model.
FLEE-GNN: A Federated Learning System for Edge-Enhanced Graph Neural Network in Analyzing Geospatial Resilience of Multicommodity Food Flows
Oct 20, 2023



Understanding and measuring the resilience of food supply networks is a global imperative to tackle increasing food insecurity. However, the complexity of these networks, with their multidimensional interactions and decisions, presents significant challenges. This paper proposes FLEE-GNN, a novel Federated Learning System for Edge-Enhanced Graph Neural Network, designed to overcome these challenges and enhance the analysis of geospatial resilience of multicommodity food flow network, which is one type of spatial networks. FLEE-GNN addresses the limitations of current methodologies, such as entropy-based methods, in terms of generalizability, scalability, and data privacy. It combines the robustness and adaptability of graph neural networks with the privacy-conscious and decentralized aspects of federated learning on food supply network resilience analysis across geographical regions. This paper also discusses FLEE-GNN's innovative data generation techniques, experimental designs, and future directions for improvement. The results show the advancements of this approach to quantifying the resilience of multicommodity food flow networks, contributing to efforts towards ensuring global food security using AI methods. The developed FLEE-GNN has the potential to be applied in other spatial networks with spatially heterogeneous sub-network distributions.
* 10 pages, 5 figures
Discourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023



Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.
Towards Domain-Independent Supervised Discourse Parsing Through Gradient Boosting
Oct 18, 2022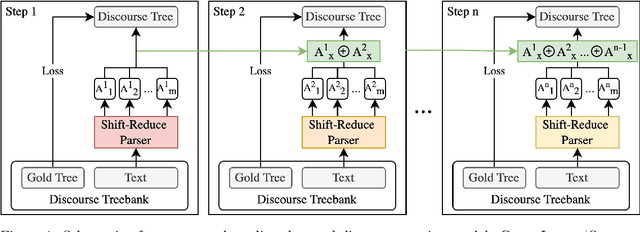
Discourse analysis and discourse parsing have shown great impact on many important problems in the field of Natural Language Processing (NLP). Given the direct impact of discourse annotations on model performance and interpretability, robustly extracting discourse structures from arbitrary documents is a key task to further improve computational models in NLP. To this end, we present a new, supervised paradigm directly tackling the domain adaptation issue in discourse parsing. Specifically, we introduce the first fully supervised discourse parser designed to alleviate the domain dependency through a staged model of weak classifiers by introducing the gradient boosting framework.
* Extended Abstract. Non Archival. 3 pages