 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAMA: Diverse Augmentation from Large Language Models to Smaller Dense Retrievers
Feb 25, 2025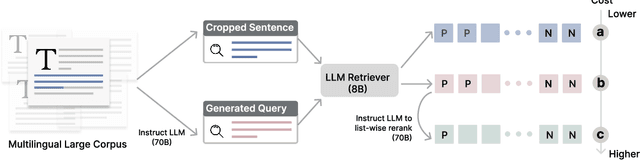
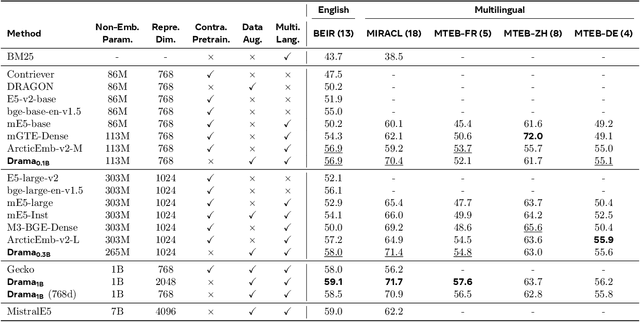
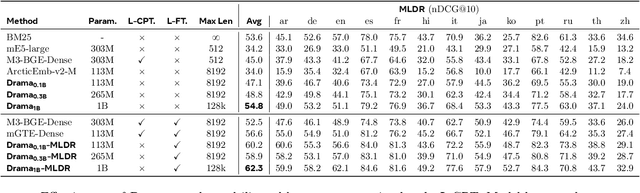
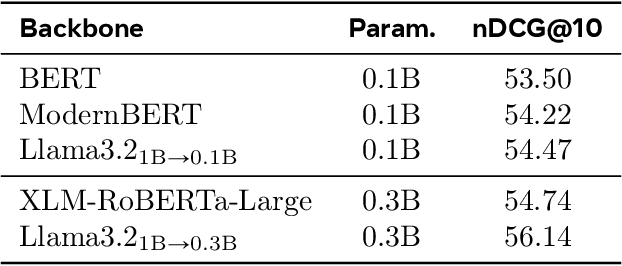
Large language models (LLMs) have demonstrated strong effectiveness and robustness while fine-tuned as dense retrievers. However, their large parameter size brings significant inference time computational challenges, including high encoding costs for large-scale corpora and increased query latency, limiting their practical deployment. While smaller retrievers offer better efficiency, they often fail to generalize effectively with limited supervised fine-tuning data. In this work, we introduce DRAMA, a training framework that leverages LLMs to train smaller generalizable dense retrievers. In particular, we adopt pruned LLMs as the backbone and train on diverse LLM-augmented data in a single-stage contrastive learning setup. Experiments show that DRAMA offers better multilingual and long-context capabilities than traditional encoder-based retrievers, and achieves strong performance across multiple tasks and languages. These highlight the potential of connecting the training of smaller retrievers with the growing advancements in LLMs, bridging the gap between efficiency and generalization.
FLAME: Factuality-Aware Alignment for Large Language Models
May 02, 2024



Alignment is a standard procedure to fine-tune pre-trained large language models (LLMs) to follow natural language instructions and serve as helpful AI assistants. We have observed, however, that the conventional alignment process fails to enhance the factual accuracy of LLMs, and often leads to the generation of more false facts (i.e. hallucination). In this paper, we study how to make the LLM alignment process more factual, by first identifying factors that lead to hallucination in both alignment steps:\ supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new knowledge or unfamiliar texts can encourage hallucination. This makes SFT less factual as it trains on human labeled data that may be novel to the LLM. Furthermore, reward functions used in standard RL can also encourage hallucination, because it guides the LLM to provide more helpful responses on a diverse set of instructions, often preferring longer and more detailed responses. Based on these observations, we propose factuality-aware alignment, comprised of factuality-aware SFT and factuality-aware RL through direct preference optimization. Experiments show that our proposed factuality-aware alignment guides LLMs to output more factual responses while maintaining instruction-following capability.
The Role of Chain-of-Thought in Complex Vision-Language Reasoning Task
Nov 15, 2023



The study explores the effectiveness of the Chain-of-Thought approach, known for its proficiency in language tasks by breaking them down into sub-tasks and intermediate steps, in improving vision-language tasks that demand sophisticated perception and reasoning. We present the "Description then Decision" strategy, which is inspired by how humans process signals. This strategy significantly improves probing task performance by 50%, establishing the groundwork for future research on reasoning paradigms in complex vision-language tasks.
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023



In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
Binary and Ternary Natural Language Generation
Jun 02, 2023



Ternary and binary neural networks enable multiplication-free computation and promise multiple orders of magnitude efficiency gains over full-precision networks if implemented on specialized hardware. However, since both the parameter and the output space are highly discretized, such networks have proven very difficult to optimize. The difficulties are compounded for the class of transformer text generation models due to the sensitivity of the attention operation to quantization and the noise-compounding effects of autoregressive decoding in the high-cardinality output space. We approach the problem with a mix of statistics-based quantization for the weights and elastic quantization of the activations and demonstrate the first ternary and binary transformer models on the downstream tasks of summarization and machine translation. Our ternary BART base achieves an R1 score of 41 on the CNN/DailyMail benchmark, which is merely 3.9 points behind the full model while being 16x more efficient. Our binary model, while less accurate, achieves a highly non-trivial score of 35.6. For machine translation, we achieved BLEU scores of 21.7 and 17.6 on the WMT16 En-Ro benchmark, compared with a full precision mBART model score of 26.8. We also compare our approach in the 8-bit activation setting, where our ternary and even binary weight models can match or outperform the best existing 8-bit weight models in the literature. Our code and models are available at: https://github.com/facebookresearch/Ternary_Binary_Transformer
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
May 29, 2023



Several post-training quantization methods have been applied to large language models (LLMs), and have been shown to perform well down to 8-bits. We find that these methods break down at lower bit precision, and investigate quantization aware training for LLMs (LLM-QAT) to push quantization levels even further. We propose a data-free distillation method that leverages generations produced by the pre-trained model, which better preserves the original output distribution and allows quantizing any generative model independent of its training data, similar to post-training quantization methods. In addition to quantizing weights and activations, we also quantize the KV cache, which is critical for increasing throughput and support long sequence dependencies at current model sizes. We experiment with LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. We observe large improvements over training-free methods, especially in the low-bit settings.
How to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval
Feb 15, 2023



Various techniques have been developed in recent years to improve dense retrieval (DR), such as unsupervised contrastive learning and pseudo-query generation. Existing DRs, however, often suffer from effectiveness tradeoffs between supervised and zero-shot retrieval, which some argue was due to the limited model capacity. We contradict this hypothesis and show that a generalizable DR can be trained to achieve high accuracy in both supervised and zero-shot retrieval without increasing model size. In particular, we systematically examine the contrastive learning of DRs, under the framework of Data Augmentation (DA). Our study shows that common DA practices such as query augmentation with generative models and pseudo-relevance label creation using a cross-encoder, are often inefficient and sub-optimal. We hence propose a new DA approach with diverse queries and sources of supervision to progressively train a generalizable DR. As a result, DRAGON, our dense retriever trained with diverse augmentation, is the first BERT-base-sized DR to achieve state-of-the-art effectiveness in both supervised and zero-shot evaluations and even competes with models using more complex late interaction (ColBERTv2 and SPLADE++).
CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
Nov 18, 2022



Multi-vector retrieval methods combine the merits of sparse (e.g. BM25) and dense (e.g. DPR) retrievers and have achieved state-of-the-art performance on various retrieval tasks. These methods, however, are orders of magnitude slower and need much more space to store their indices compared to their single-vector counterparts. In this paper, we unify different multi-vector retrieval models from a token routing viewpoint and propose conditional token interaction via dynamic lexical routing, namely CITADEL, for efficient and effective multi-vector retrieval. CITADEL learns to route different token vectors to the predicted lexical ``keys'' such that a query token vector only interacts with document token vectors routed to the same key. This design significantly reduces the computation cost while maintaining high accuracy. Notably, CITADEL achieves the same or slightly better performance than the previous state of the art, ColBERT-v2, on both in-domain (MS MARCO) and out-of-domain (BEIR) evaluations, while being nearly 40 times faster. Code and data are available at https://github.com/facebookresearch/dpr-scale.