 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism
Dec 23, 2024



We present BenCzechMark (BCM), the first comprehensive Czech language benchmark designed for large language models, offering diverse tasks, multiple task formats, and multiple evaluation metrics. Its scoring system is grounded in statistical significance theory and uses aggregation across tasks inspired by social preference theory. Our benchmark encompasses 50 challenging tasks, with corresponding test datasets, primarily in native Czech, with 11 newly collected ones. These tasks span 8 categories and cover diverse domains, including historical Czech news, essays from pupils or language learners, and spoken word. Furthermore, we collect and clean BUT-Large Czech Collection, the largest publicly available clean Czech language corpus, and use it for (i) contamination analysis, (ii) continuous pretraining of the first Czech-centric 7B language model, with Czech-specific tokenization. We use our model as a baseline for comparison with publicly available multilingual models. Lastly, we release and maintain a leaderboard, with existing 44 model submissions, where new model submissions can be made at https://huggingface.co/spaces/CZLC/BenCzechMark.
OARelatedWork: A Large-Scale Dataset of Related Work Sections with Full-texts from Open Access Sources
May 03, 2024



This paper introduces OARelatedWork, the first large-scale multi-document summarization dataset for related work generation containing whole related work sections and full-texts of cited papers. The dataset includes 94 450 papers and 5 824 689 unique referenced papers. It was designed for the task of automatically generating related work to shift the field toward generating entire related work sections from all available content instead of generating parts of related work sections from abstracts only, which is the current mainstream in this field for abstractive approaches. We show that the estimated upper bound for extractive summarization increases by 217% in the ROUGE-2 score, when using full content instead of abstracts. Furthermore, we show the benefits of full content data on naive, oracle, traditional, and transformer-based baselines. Long outputs, such as related work sections, pose challenges for automatic evaluation metrics like BERTScore due to their limited input length. We tackle this issue by proposing and evaluating a meta-metric using BERTScore. Despite operating on smaller blocks, we show this meta-metric correlates with human judgment, comparably to the original BERTScore.
IDIAPers @ Causal News Corpus 2022: Efficient Causal Relation Identification Through a Prompt-based Few-shot Approach
Sep 08, 2022
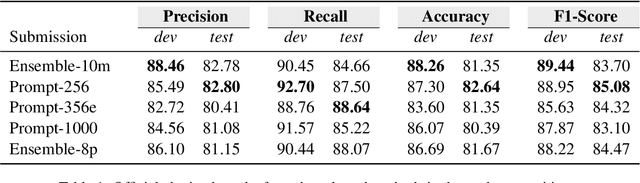
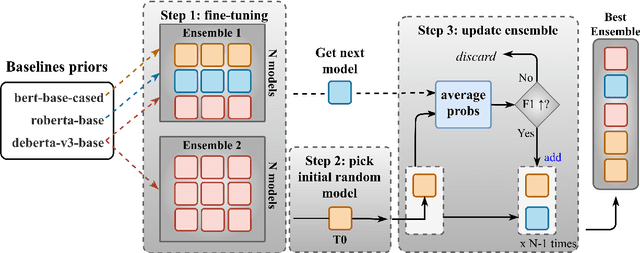
In this paper, we describe our participation in the subtask 1 of CASE-2022, Event Causality Identification with Casual News Corpus. We address the Causal Relation Identification (CRI) task by exploiting a set of simple yet complementary techniques for fine-tuning language models (LMs) on a small number of annotated examples (i.e., a few-shot configuration). We follow a prompt-based prediction approach for fine-tuning LMs in which the CRI task is treated as a masked language modeling problem (MLM). This approach allows LMs natively pre-trained on MLM problems to directly generate textual responses to CRI-specific prompts. We compare the performance of this method against ensemble techniques trained on the entire dataset. Our best-performing submission was trained only with 256 instances per class, a small portion of the entire dataset, and yet was able to obtain the second-best precision (0.82), third-best accuracy (0.82), and an F1-score (0.85) very close to what was reported by the winner team (0.86).
IDIAPers @ Causal News Corpus 2022: Extracting Cause-Effect-Signal Triplets via Pre-trained Autoregressive Language Model
Sep 08, 2022
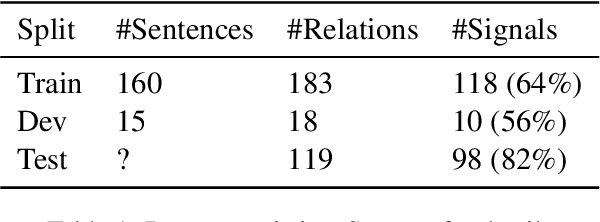
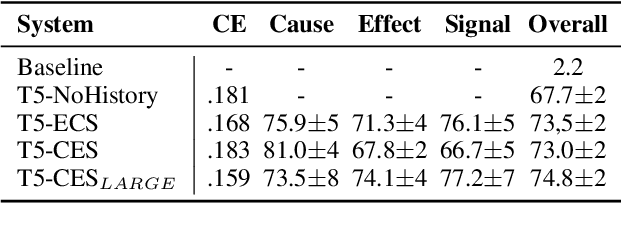
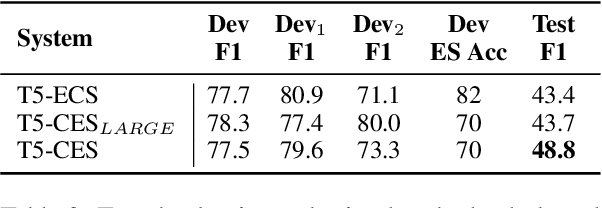
In this paper, we describe our shared task submissions for Subtask 2 in CASE-2022, Event Causality Identification with Casual News Corpus. The challenge focused on the automatic detection of all cause-effect-signal spans present in the sentence from news-media. We detect cause-effect-signal spans in a sentence using T5 -- a pre-trained autoregressive language model. We iteratively identify all cause-effect-signal span triplets, always conditioning the prediction of the next triplet on the previously predicted ones. To predict the triplet itself, we consider different causal relationships such as cause$\rightarrow$effect$\rightarrow$signal. Each triplet component is generated via a language model conditioned on the sentence, the previous parts of the current triplet, and previously predicted triplets. Despite training on an extremely small dataset of 160 samples, our approach achieved competitive performance, being placed second in the competition. Furthermore, we show that assuming either cause$\rightarrow$effect or effect$\rightarrow$cause order achieves similar results. Our code and model predictions will be released online.
Claim-Dissector: An Interpretable Fact-Checking System with Joint Re-ranking and Veracity Prediction
Jul 28, 2022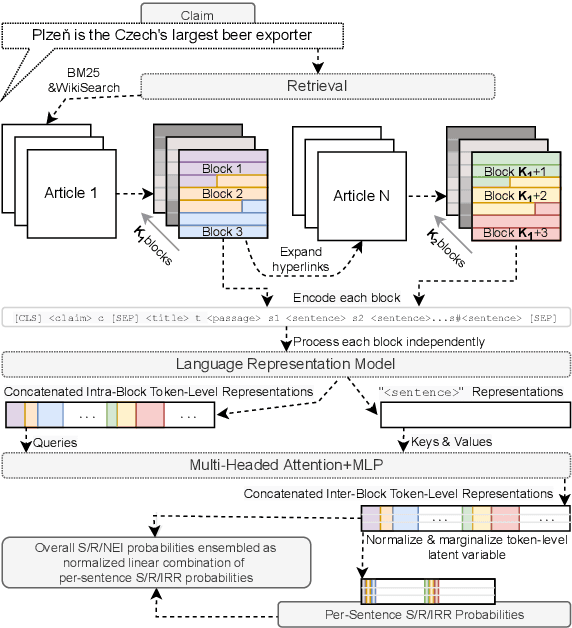

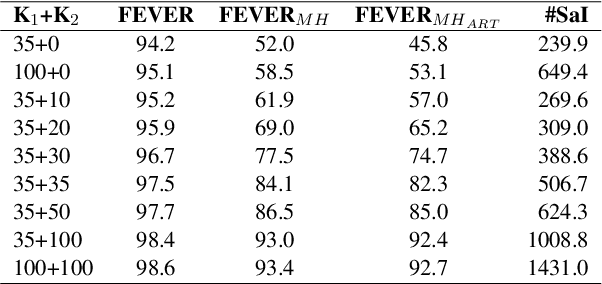
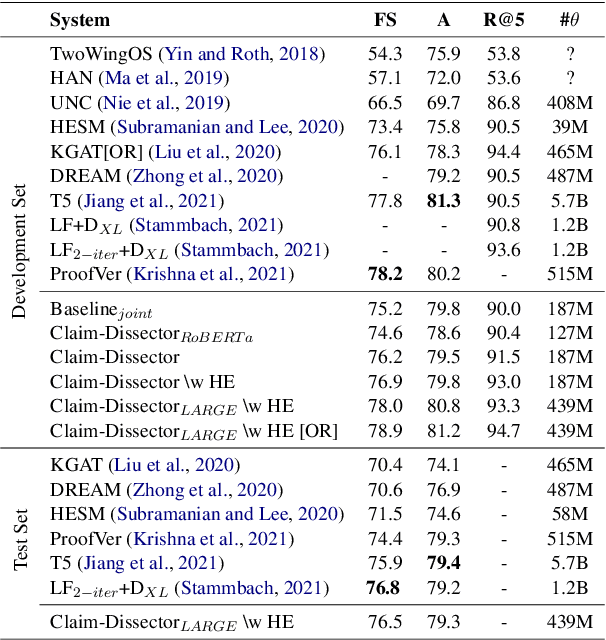
We present Claim-Dissector: a novel latent variable model for fact-checking and fact-analysis, which given a claim and a set of retrieved provenances allows learning jointly: (i) what are the relevant provenances to this claim (ii) what is the veracity of this claim. We propose to disentangle the per-provenance relevance probability and its contribution to the final veracity probability in an interpretable way - the final veracity probability is proportional to a linear ensemble of per-provenance relevance probabilities. This way, it can be clearly identified the relevance of which sources contributes to what extent towards the final probability. We show that our system achieves state-of-the-art results on FEVER dataset comparable to two-stage systems typically used in traditional fact-checking pipelines, while it often uses significantly less parameters and computation. Our analysis shows that proposed approach further allows to learn not just which provenances are relevant, but also which provenances lead to supporting and which toward denying the claim, without direct supervision. This not only adds interpretability, but also allows to detect claims with conflicting evidence automatically. Furthermore, we study whether our model can learn fine-grained relevance cues while using coarse-grained supervision. We show that our model can achieve competitive sentence-recall while using only paragraph-level relevance supervision. Finally, traversing towards the finest granularity of relevance, we show that our framework is capable of identifying relevance at the token-level. To do this, we present a new benchmark focusing on token-level interpretability - humans annotate tokens in relevant provenances they considered essential when making their judgement. Then we measure how similar are these annotations to tokens our model is focusing on. Our code, and dataset will be released online.
Query-Based Keyphrase Extraction from Long Documents
May 11, 2022
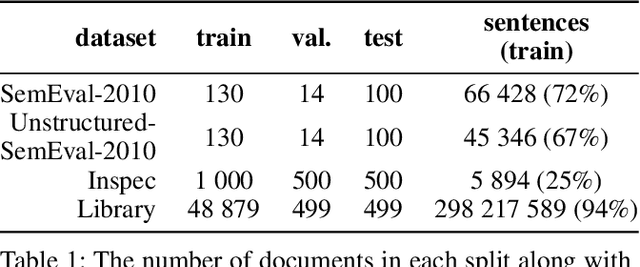
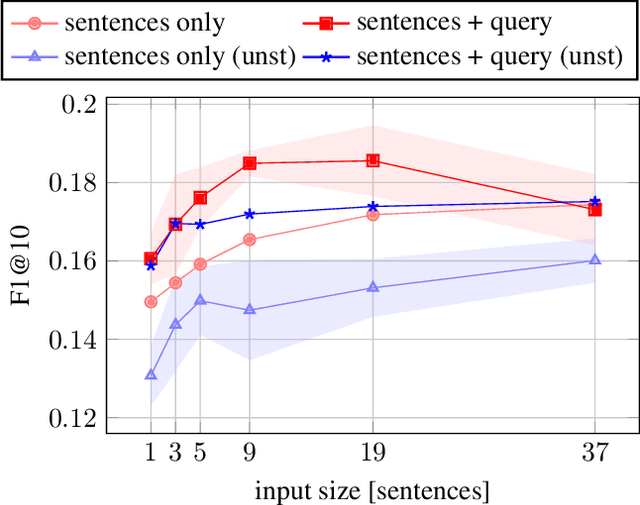
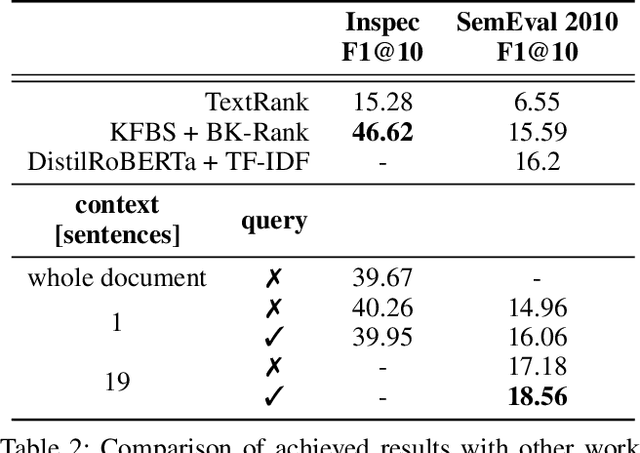
Transformer-based architectures in natural language processing force input size limits that can be problematic when long documents need to be processed. This paper overcomes this issue for keyphrase extraction by chunking the long documents while keeping a global context as a query defining the topic for which relevant keyphrases should be extracted. The developed system employs a pre-trained BERT model and adapts it to estimate the probability that a given text span forms a keyphrase. We experimented using various context sizes on two popular datasets, Inspec and SemEval, and a large novel dataset. The presented results show that a shorter context with a query overcomes a longer one without the query on long documents.
R2-D2: A Modular Baseline for Open-Domain Question Answering
Sep 08, 2021
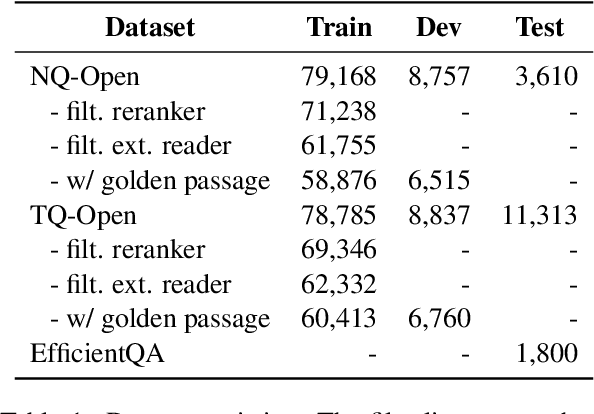
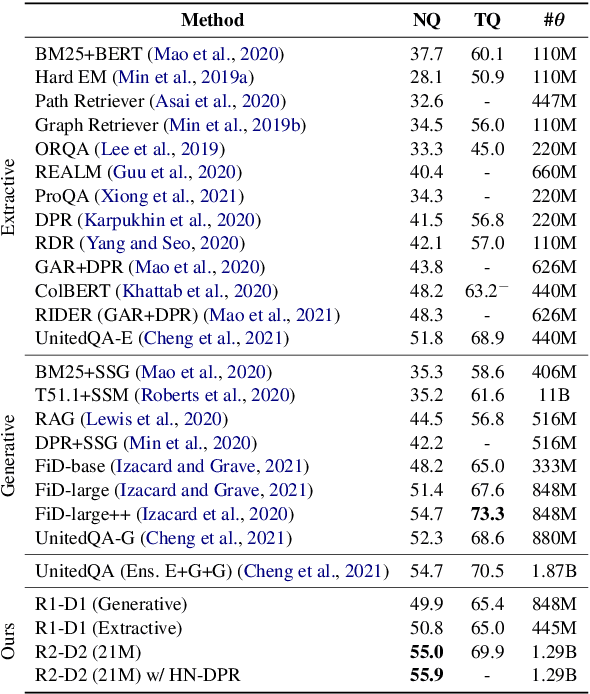
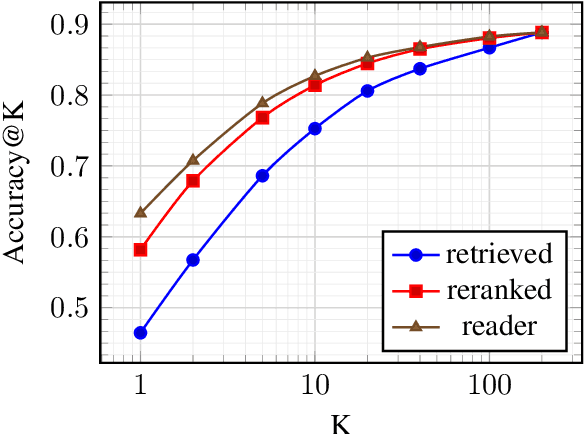
This work presents a novel four-stage open-domain QA pipeline R2-D2 (Rank twice, reaD twice). The pipeline is composed of a retriever, passage reranker, extractive reader, generative reader and a mechanism that aggregates the final prediction from all system's components. We demonstrate its strength across three open-domain QA datasets: NaturalQuestions, TriviaQA and EfficientQA, surpassing state-of-the-art on the first two. Our analysis demonstrates that: (i) combining extractive and generative reader yields absolute improvements up to 5 exact match and it is at least twice as effective as the posterior averaging ensemble of the same models with different parameters, (ii) the extractive reader with fewer parameters can match the performance of the generative reader on extractive QA datasets.
Pruning the Index Contents for Memory Efficient Open-Domain QA
Feb 21, 2021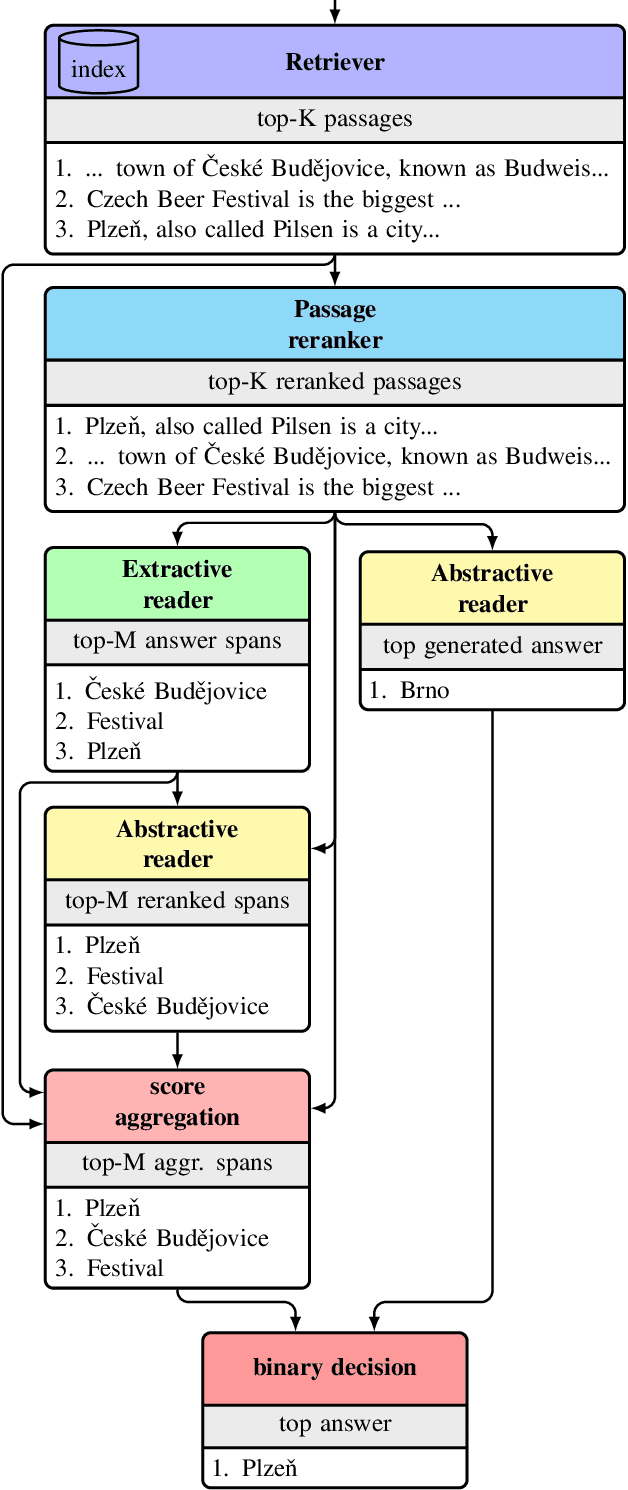
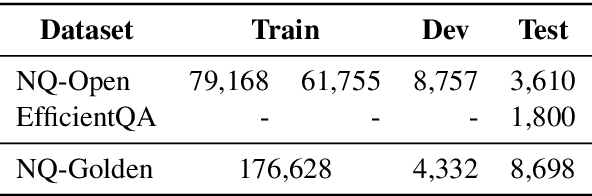
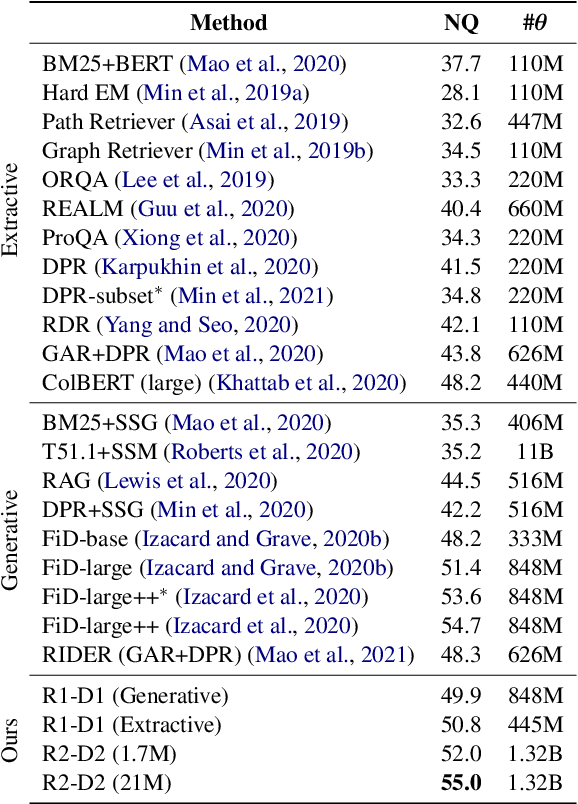
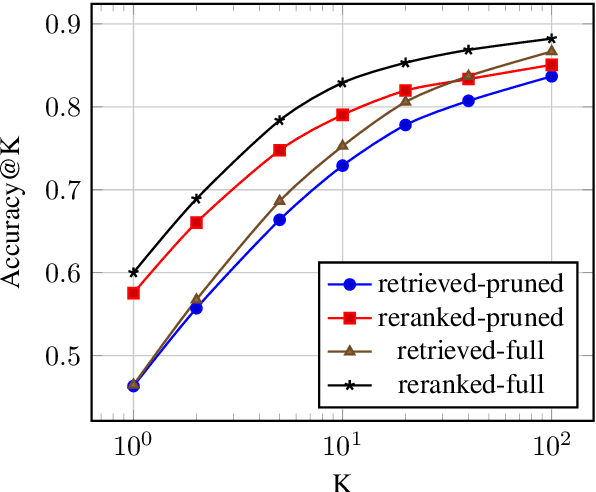
This work presents a novel pipeline that demonstrates what is achievable with a combined effort of state-of-the-art approaches, surpassing the 50% exact match on NaturalQuestions and EfficentQA datasets. Specifically, it proposes the novel R2-D2 (Rank twice, reaD twice) pipeline composed of retriever, reranker, extractive reader, generative reader and a simple way to combine them. Furthermore, previous work often comes with a massive index of external documents that scales in the order of tens of GiB. This work presents a simple approach for pruning the contents of a massive index such that the open-domain QA system altogether with index, OS, and library components fits into 6GiB docker image while retaining only 8% of original index contents and losing only 3% EM accuracy.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021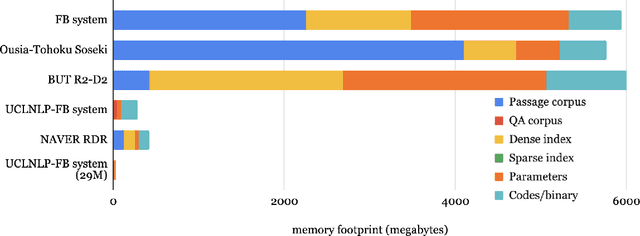
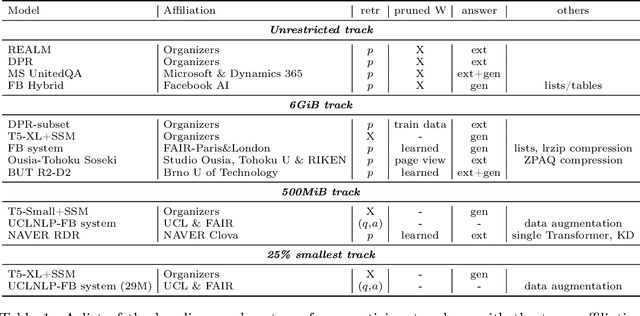
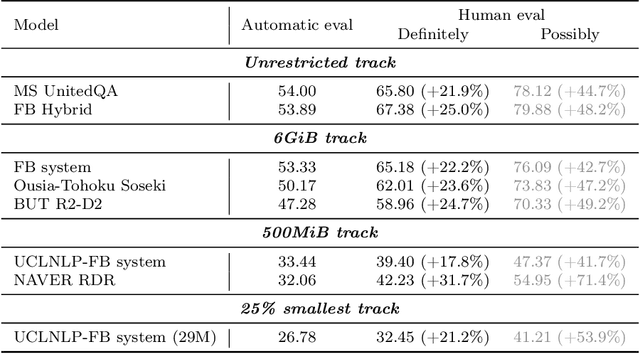
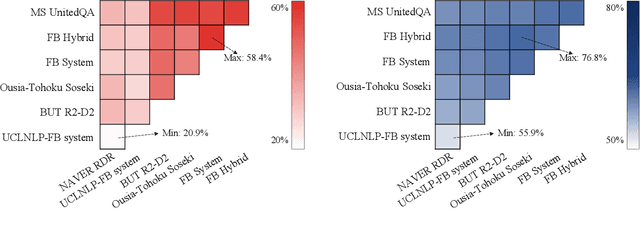
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Rethinking the objectives of extractive question answering
Aug 28, 2020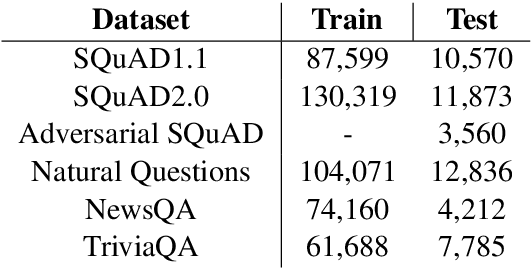
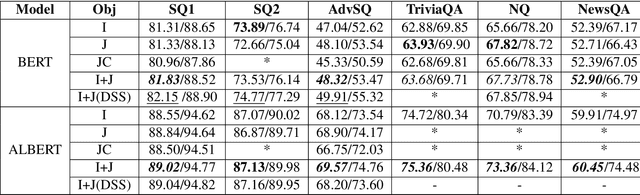
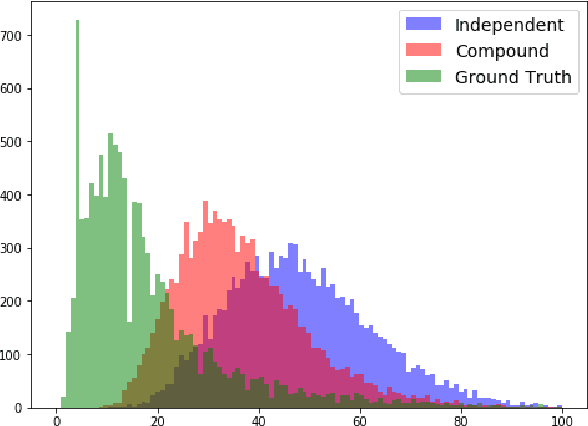
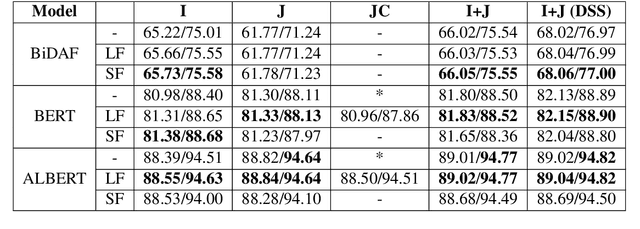
This paper describes two generally applicable approaches towards the significant improvement of the performance of state-of-the-art extractive question answering (EQA) systems. Firstly, contrary to a common belief, it demonstrates that using the objective with independence assumption for span probability $P(a_s,a_e) = P(a_s)P(a_e)$ of span starting at position $a_s$ and ending at position $a_e$ may have adverse effects. Therefore we propose a new compound objective that models joint probability $P(a_s,a_e)$ directly, while still keeping the objective with independency assumption as an auxiliary objective. Our second approach shows the beneficial effect of distantly semi-supervised shared-normalization objective known from (Clark and Gardner, 2017). We show that normalizing over a set of documents similar to the golden passage, and marginalizing over all ground-truth answer string positions leads to the improvement of results from smaller statistical models. Our results are supported via experiments with three QA models (BidAF, BERT, ALBERT) over six datasets. The proposed approaches do not use any additional data. Our code, analysis, pretrained models, and individual results will be available online.