 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training
Paper and Code
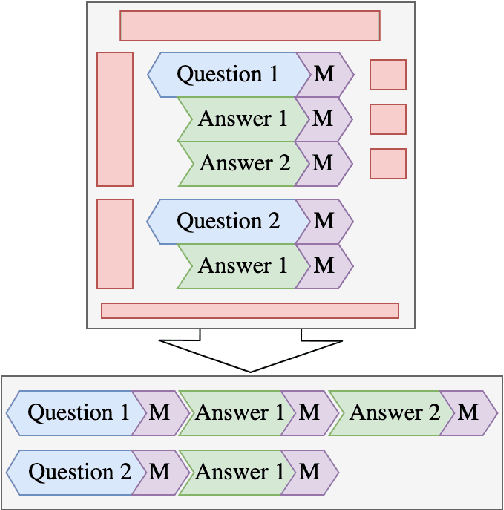

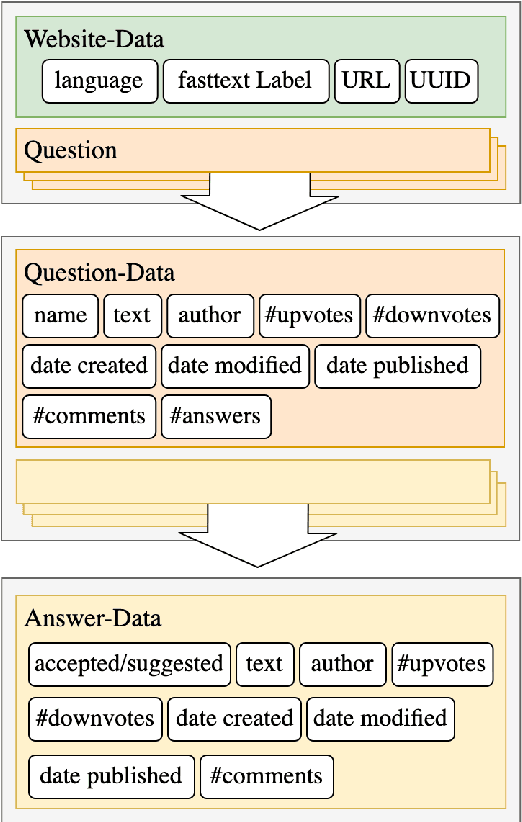

With the rise of large-scale pre-trained language models, open-domain question-answering (ODQA) has become an important research topic in NLP. Based on the popular pre-training fine-tuning approach, we posit that an additional in-domain pre-training stage using a large-scale, natural, and diverse question-answering (QA) dataset can be beneficial for ODQA. Consequently, we propose a novel QA dataset based on the Common Crawl project in this paper. Using the readily available schema.org annotation, we extract around 130 million multilingual question-answer pairs, including about 60 million English data-points. With this previously unseen number of natural QA pairs, we pre-train popular language models to show the potential of large-scale in-domain pre-training for the task of question-answering. In our experiments, we find that pre-training question-answering models on our Common Crawl Question Answering dataset (CCQA) achieves promising results in zero-shot, low resource and fine-tuned settings across multiple tasks, models and benchmarks.