 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Findings for Jaw Cysts in Dental Panoramic Radiographs Using GPT-4o: Building a Two-Stage Self-Correction Loop with Structured Output (SLSO) Framework
Oct 02, 2025In this study, we utilized the multimodal capabilities of OpenAI GPT-4o to automatically generate jaw cyst findings on dental panoramic radiographs. To improve accuracy, we constructed a Self-correction Loop with Structured Output (SLSO) framework and verified its effectiveness. A 10-step process was implemented for 22 cases of jaw cysts, including image input and analysis, structured data generation, tooth number extraction and consistency checking, iterative regeneration when inconsistencies were detected, and finding generation with subsequent restructuring and consistency verification. A comparative experiment was conducted using the conventional Chain-of-Thought (CoT) method across seven evaluation items: transparency, internal structure, borders, root resorption, tooth movement, relationships with other structures, and tooth number. The results showed that the proposed SLSO framework improved output accuracy for many items, with 66.9%, 33.3%, and 28.6% improvement rates for tooth number, tooth movement, and root resorption, respectively. In the successful cases, a consistently structured output was achieved after up to five regenerations. Although statistical significance was not reached because of the small size of the dataset, the overall SLSO framework enforced negative finding descriptions, suppressed hallucinations, and improved tooth number identification accuracy. However, the accurate identification of extensive lesions spanning multiple teeth is limited. Nevertheless, further refinement is required to enhance overall performance and move toward a practical finding generation system.
Joint-repositionable Inner-wireless Planar Snake Robot
Nov 21, 2024



Bio-inspired multi-joint snake robots offer the advantages of terrain adaptability due to their limbless structure and high flexibility. However, a series of dozens of motor units in typical multiple-joint snake robots results in a heavy body structure and hundreds of watts of high power consumption. This paper presents a joint-repositionable, inner-wireless snake robot that enables multi-joint-like locomotion using a low-powered underactuated mechanism. The snake robot, consisting of a series of flexible passive links, can dynamically change its joint coupling configuration by repositioning motor-driven joint units along rack gears inside the robot. Additionally, a soft robot skin wirelessly powers the internal joint units, avoiding the risk of wire tangling and disconnection caused by the movable joint units. The combination of the joint-repositionable mechanism and the wireless-charging-enabled soft skin achieves a high degree of bending, along with a lightweight structure of 1.3 kg and energy-efficient wireless power transmission of 7.6 watts.
Are Prompt-based Models Clueless?
May 20, 2022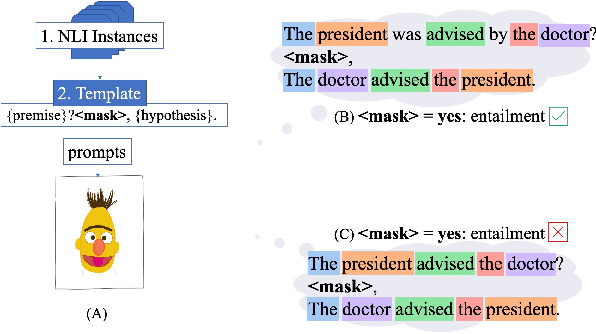
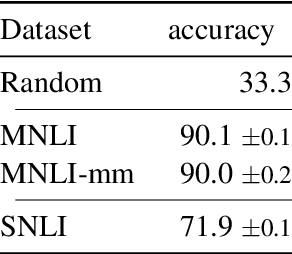
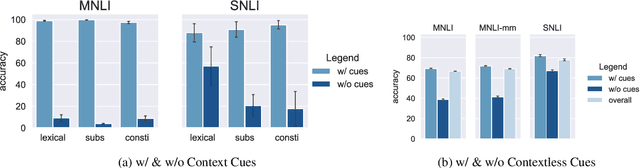
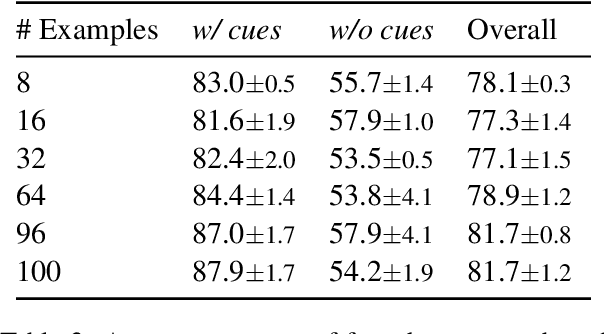
Finetuning large pre-trained language models with a task-specific head has advanced the state-of-the-art on many natural language understanding benchmarks. However, models with a task-specific head require a lot of training data, making them susceptible to learning and exploiting dataset-specific superficial cues that do not generalize to other datasets. Prompting has reduced the data requirement by reusing the language model head and formatting the task input to match the pre-training objective. Therefore, it is expected that few-shot prompt-based models do not exploit superficial cues. This paper presents an empirical examination of whether few-shot prompt-based models also exploit superficial cues. Analyzing few-shot prompt-based models on MNLI, SNLI, HANS, and COPA has revealed that prompt-based models also exploit superficial cues. While the models perform well on instances with superficial cues, they often underperform or only marginally outperform random accuracy on instances without superficial cues.
Two Training Strategies for Improving Relation Extraction over Universal Graph
Feb 12, 2021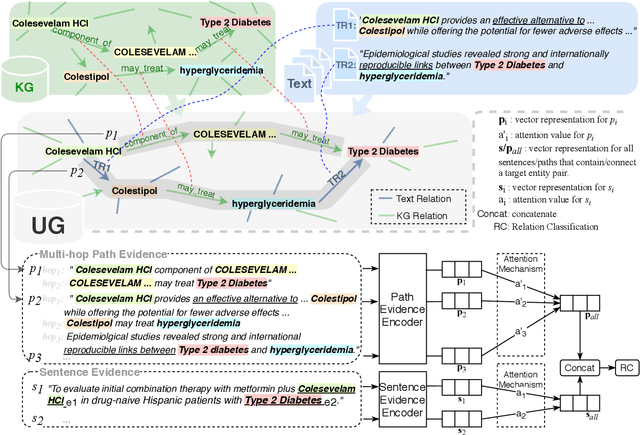

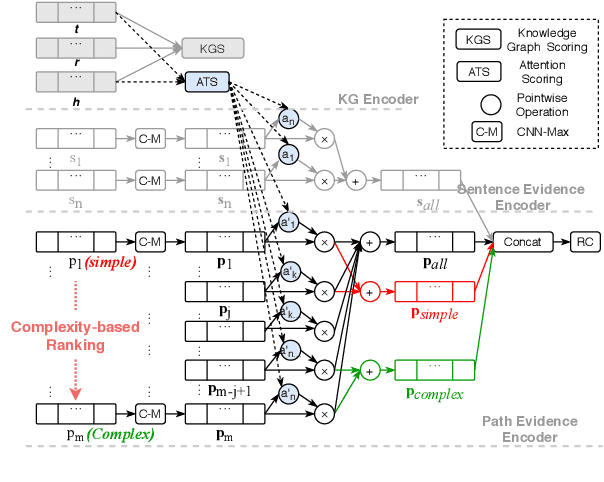

This paper explores how the Distantly Supervised Relation Extraction (DS-RE) can benefit from the use of a Universal Graph (UG), the combination of a Knowledge Graph (KG) and a large-scale text collection. A straightforward extension of a current state-of-the-art neural model for DS-RE with a UG may lead to degradation in performance. We first report that this degradation is associated with the difficulty in learning a UG and then propose two training strategies: (1) Path Type Adaptive Pretraining, which sequentially trains the model with different types of UG paths so as to prevent the reliance on a single type of UG path; and (2) Complexity Ranking Guided Attention mechanism, which restricts the attention span according to the complexity of a UG path so as to force the model to extract features not only from simple UG paths but also from complex ones. Experimental results on both biomedical and NYT10 datasets prove the robustness of our methods and achieve a new state-of-the-art result on the NYT10 dataset. The code and datasets used in this paper are available at https://github.com/baodaiqin/UGDSRE.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021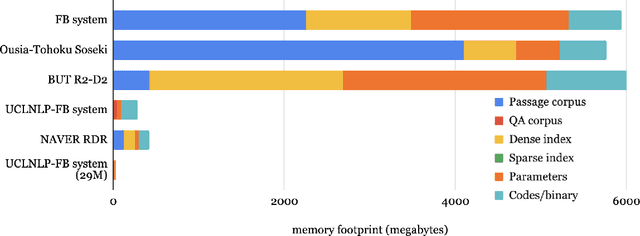
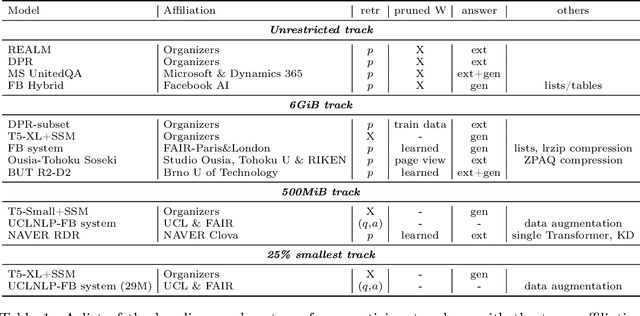
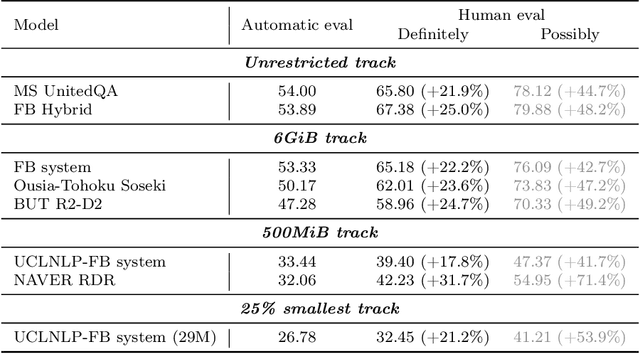
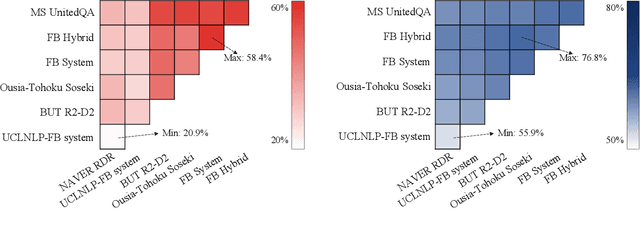
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
An Empirical Study of Contextual Data Augmentation for Japanese Zero Anaphora Resolution
Nov 04, 2020



One critical issue of zero anaphora resolution (ZAR) is the scarcity of labeled data. This study explores how effectively this problem can be alleviated by data augmentation. We adopt a state-of-the-art data augmentation method, called the contextual data augmentation (CDA), that generates labeled training instances using a pretrained language model. The CDA has been reported to work well for several other natural language processing tasks, including text classification and machine translation. This study addresses two underexplored issues on CDA, that is, how to reduce the computational cost of data augmentation and how to ensure the quality of the generated data. We also propose two methods to adapt CDA to ZAR: [MASK]-based augmentation and linguistically-controlled masking. Consequently, the experimental results on Japanese ZAR show that our methods contribute to both the accuracy gain and the computation cost reduction. Our closer analysis reveals that the proposed method can improve the quality of the augmented training data when compared to the conventional CDA.
Modeling Event Salience in Narratives via Barthes' Cardinal Functions
Nov 03, 2020
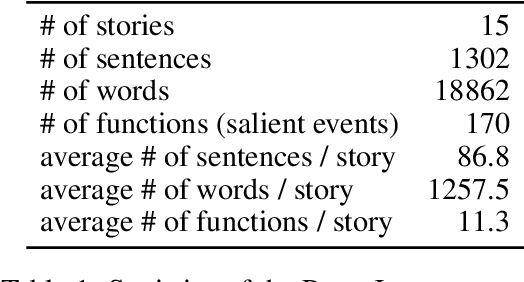
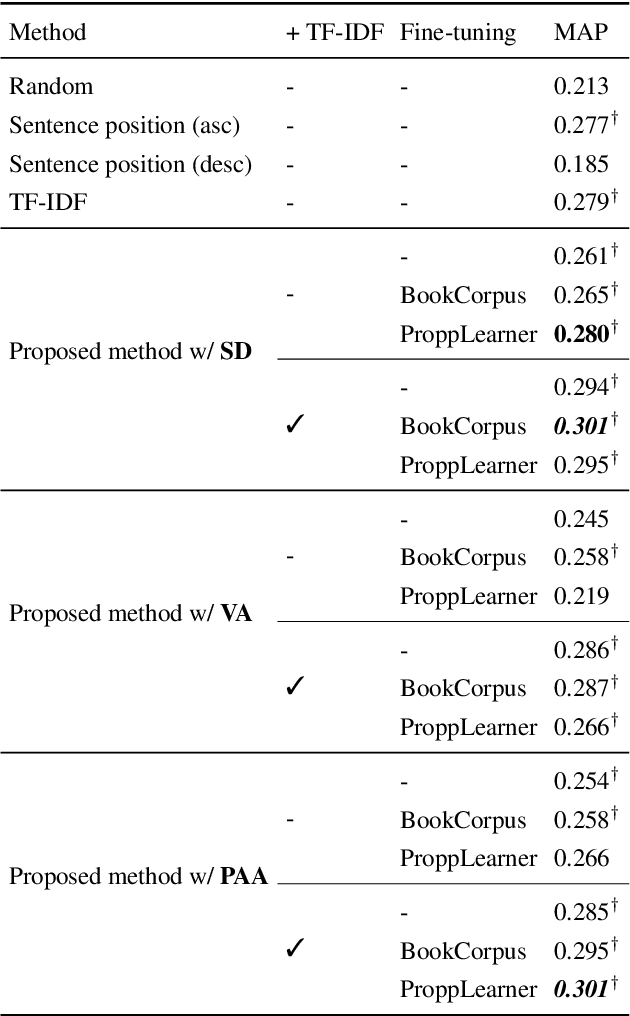

Events in a narrative differ in salience: some are more important to the story than others. Estimating event salience is useful for tasks such as story generation, and as a tool for text analysis in narratology and folkloristics. To compute event salience without any annotations, we adopt Barthes' definition of event salience and propose several unsupervised methods that require only a pre-trained language model. Evaluating the proposed methods on folktales with event salience annotation, we show that the proposed methods outperform baseline methods and find fine-tuning a language model on narrative texts is a key factor in improving the proposed methods.
Word Rotator's Distance: Decomposing Vectors Gives Better Representations
Apr 30, 2020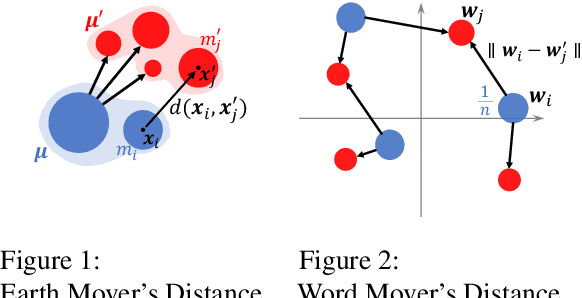
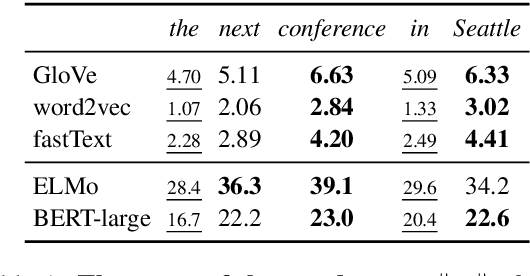
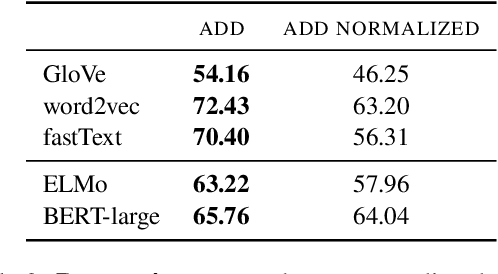
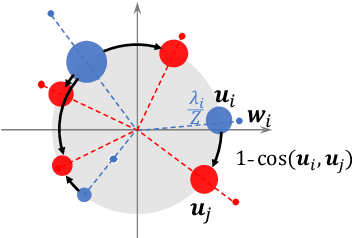
One key principle for assessing semantic similarity between texts is to measure the degree of semantic overlap of them by considering word-by-word alignment. However, alignment-based approaches} are inferior to the generic sentence vectors in terms of performance. We hypothesize that the reason for the inferiority of alignment-based methods is due to the fact that they do not distinguish word importance and word meaning. To solve this, we propose to separate word importance and word meaning by decomposing word vectors into their norm and direction, then compute the alignment-based similarity with the help of earth mover's distance. We call the method word rotator's distance (WRD) because direction vectors are aligned by rotation on the unit hypersphere. In addition, to incorporate the advance of cutting edge additive sentence encoders, we propose to re-decompose such sentence vectors into word vectors and use them as inputs to WRD. Empirically, the proposed method outperforms current methods considering the word-by-word alignment including word mover's distance with a big difference; moreover, our method outperforms state-of-the-art additive sentence encoders on the most competitive dataset, STS-benchmark.
Data Augmentation using Random Image Cropping and Patching for Deep CNNs
Nov 22, 2018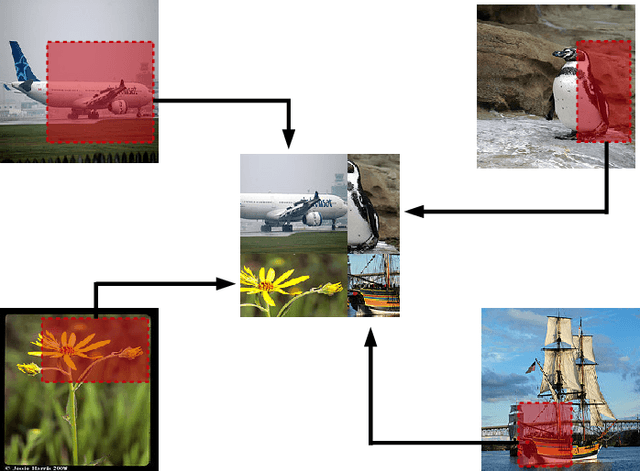
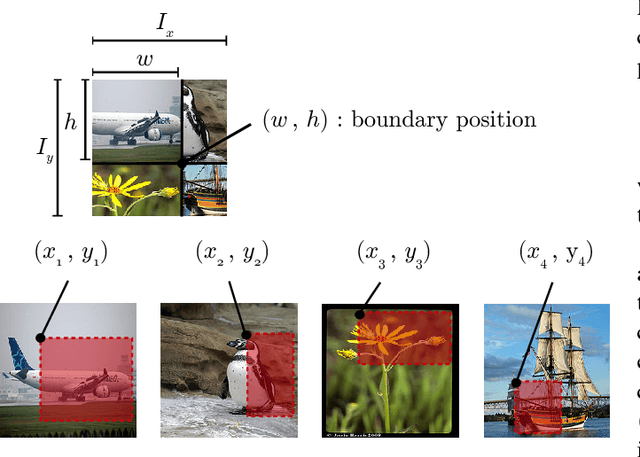
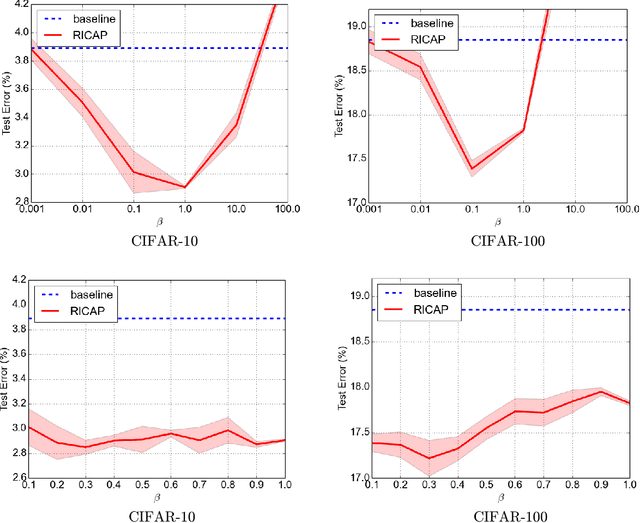

Deep convolutional neural networks (CNNs) have achieved remarkable results in image processing tasks. However, their high expression ability risks overfitting. Consequently, data augmentation techniques have been proposed to prevent overfitting while enriching datasets. Recent CNN architectures with more parameters are rendering traditional data augmentation techniques insufficient. In this study, we propose a new data augmentation technique called random image cropping and patching (RICAP) which randomly crops four images and patches them to create a new training image. Moreover, RICAP mixes the class labels of the four images, resulting in an advantage similar to label smoothing. We evaluated RICAP with current state-of-the-art CNNs (e.g., the shake-shake regularization model) by comparison with competitive data augmentation techniques such as cutout and mixup. RICAP achieves a new state-of-the-art test error of $2.19\%$ on CIFAR-10. We also confirmed that deep CNNs with RICAP achieve better results on classification tasks using CIFAR-100 and ImageNet and an image-caption retrieval task using Microsoft COCO.
Interpretable and Compositional Relation Learning by Joint Training with an Autoencoder
May 24, 2018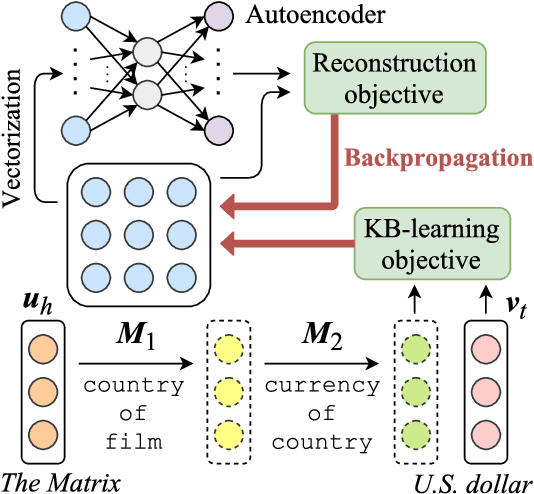
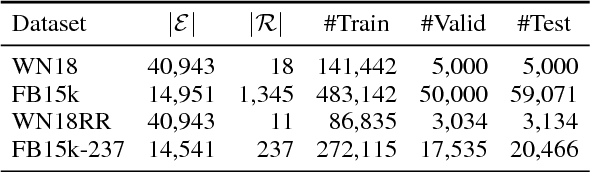
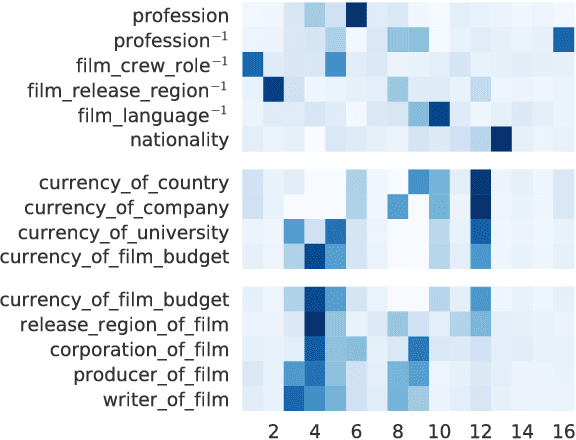
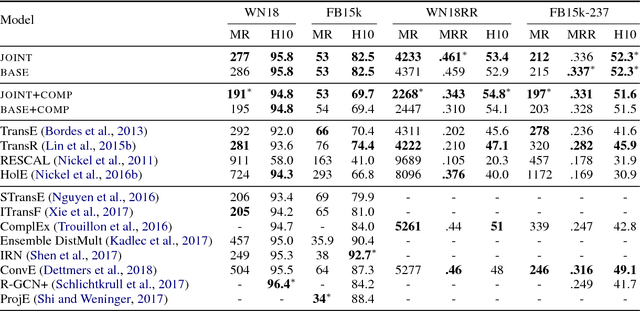
Embedding models for entities and relations are extremely useful for recovering missing facts in a knowledge base. Intuitively, a relation can be modeled by a matrix mapping entity vectors. However, relations reside on low dimension sub-manifolds in the parameter space of arbitrary matrices---for one reason, composition of two relations $\boldsymbol{M}_1,\boldsymbol{M}_2$ may match a third $\boldsymbol{M}_3$ (e.g. composition of relations currency_of_country and country_of_film usually matches currency_of_film_budget), which imposes compositional constraints to be satisfied by the parameters (i.e. $\boldsymbol{M}_1\cdot \boldsymbol{M}_2\approx \boldsymbol{M}_3$). In this paper we investigate a dimension reduction technique by training relations jointly with an autoencoder, which is expected to better capture compositional constraints. We achieve state-of-the-art on Knowledge Base Completion tasks with strongly improved Mean Rank, and show that joint training with an autoencoder leads to interpretable sparse codings of relations, helps discovering compositional constraints and benefits from compositional training. Our source code is released at github.com/tianran/glimvec.