Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Open-Domain Question Answering with Structured and Unstructured Knowledge
Paper and Code
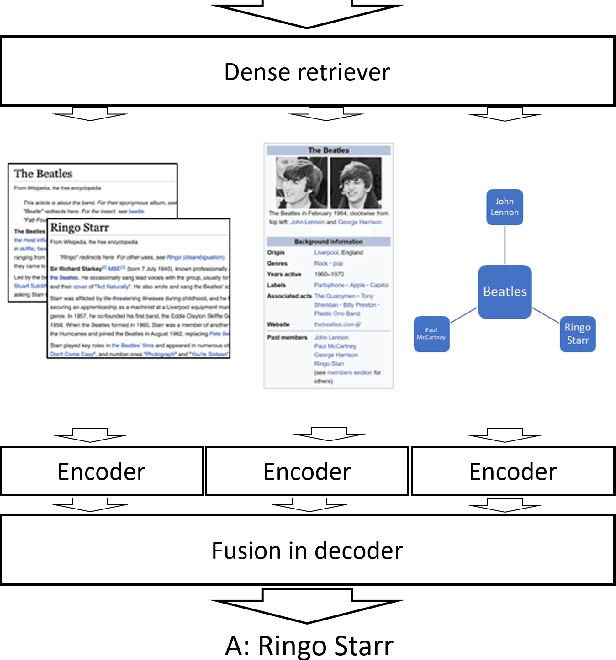

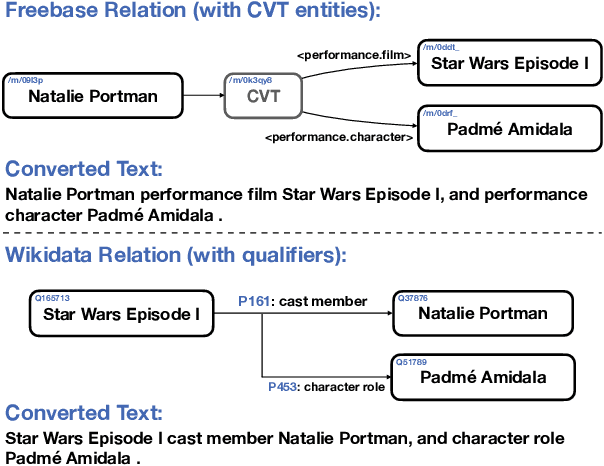
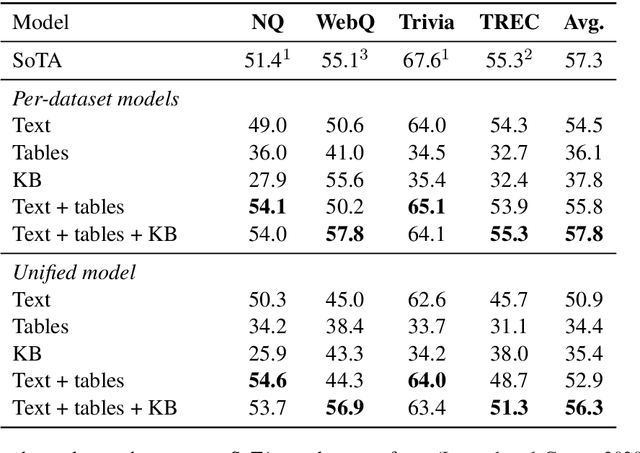
We study open-domain question answering (ODQA) with structured, unstructured and semi-structured knowledge sources, including text, tables, lists, and knowledge bases. Our approach homogenizes all sources by reducing them to text, and applies recent, powerful retriever-reader models which have so far been limited to text sources only. We show that knowledge-base QA can be greatly improved when reformulated in this way. Contrary to previous work, we find that combining sources always helps, even for datasets which target a single source by construction. As a result, our unified model produces state-of-the-art results on 3 popular ODQA benchmarks.
View paper on