 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Test-time Computation Mitigate Memorization Bias in Neural Symbolic Regression?
May 28, 2025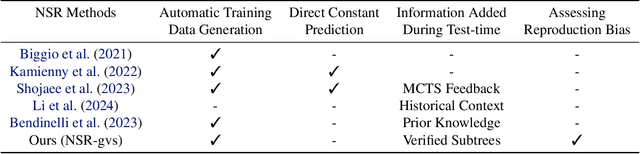



Symbolic regression aims to discover mathematical equations that fit given numerical data. It has been applied in various fields of scientific research, such as producing human-readable expressions that explain physical phenomena. Recently, Neural symbolic regression (NSR) methods that involve Transformers pre-trained on large-scale synthetic datasets have gained attention. While these methods offer advantages such as short inference time, they suffer from low performance, particularly when the number of input variables is large. In this study, we hypothesized that this limitation stems from the memorization bias of Transformers in symbolic regression. We conducted a quantitative evaluation of this bias in Transformers using a synthetic dataset and found that Transformers rarely generate expressions not present in the training data. Additional theoretical analysis reveals that this bias arises from the Transformer's inability to construct expressions compositionally while verifying their numerical validity. We finally examined if tailoring test-time strategies can lead to reduced memorization bias and better performance. We empirically demonstrate that providing additional information to the model at test time can significantly mitigate memorization bias. On the other hand, we also find that reducing memorization bias does not necessarily correlate with improved performance. These findings contribute to a deeper understanding of the limitations of NSR approaches and offer a foundation for designing more robust, generalizable symbolic regression methods. Code is available at https://github.com/Shun-0922/Mem-Bias-NSR .
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021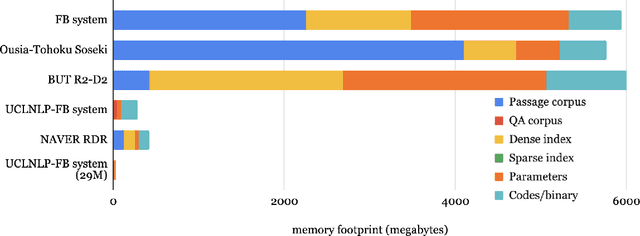
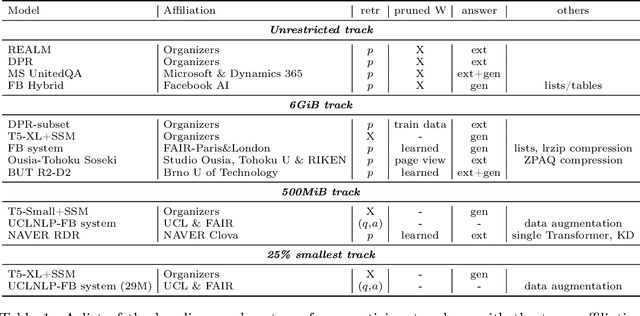
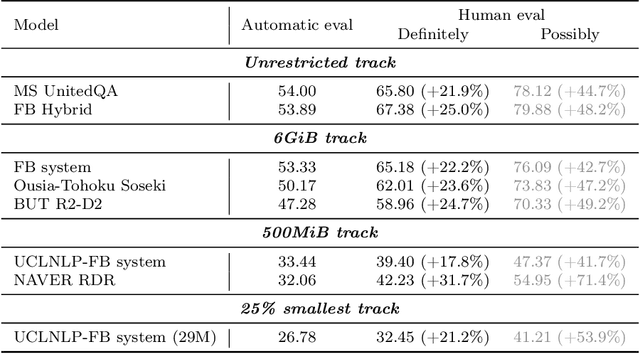
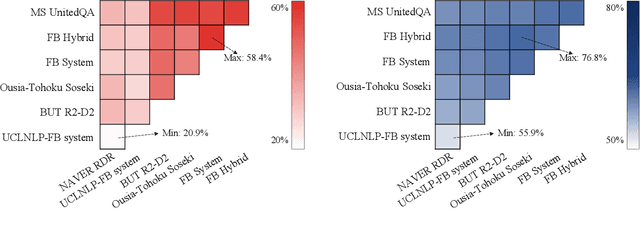
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.