 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
Long-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
May 31, 2024



We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024



Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
Learning to Reject with a Fixed Predictor: Application to Decontextualization
Jan 31, 2023



We study the problem of classification with a reject option for a fixed predictor, applicable in natural language processing. We introduce a new problem formulation for this scenario, and an algorithm minimizing a new surrogate loss function. We provide a complete theoretical analysis of the surrogate loss function with a strong $H$-consistency guarantee. For evaluation, we choose the decontextualization task, and provide a manually-labelled dataset of $2\mathord,000$ examples. Our algorithm significantly outperforms the baselines considered, with a $\sim\!\!25\%$ improvement in coverage when halving the error rate, which is only $\sim\!\! 3 \%$ away from the theoretical limit.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Coreference Resolution through a seq2seq Transition-Based System
Nov 22, 2022Most recent coreference resolution systems use search algorithms over possible spans to identify mentions and resolve coreference. We instead present a coreference resolution system that uses a text-to-text (seq2seq) paradigm to predict mentions and links jointly. We implement the coreference system as a transition system and use multilingual T5 as an underlying language model. We obtain state-of-the-art accuracy on the CoNLL-2012 datasets with 83.3 F1-score for English (a 2.3 higher F1-score than previous work (Dobrovolskii, 2021)) using only CoNLL data for training, 68.5 F1-score for Arabic (+4.1 higher than previous work) and 74.3 F1-score for Chinese (+5.3). In addition we use the SemEval-2010 data sets for experiments in the zero-shot setting, a few-shot setting, and supervised setting using all available training data. We get substantially higher zero-shot F1-scores for 3 out of 4 languages than previous approaches and significantly exceed previous supervised state-of-the-art results for all five tested languages.
Towards Computationally Verifiable Semantic Grounding for Language Models
Nov 16, 2022



The paper presents an approach to semantic grounding of language models (LMs) that conceptualizes the LM as a conditional model generating text given a desired semantic message formalized as a set of entity-relationship triples. It embeds the LM in an auto-encoder by feeding its output to a semantic parser whose output is in the same representation domain as the input message. Compared to a baseline that generates text using greedy search, we demonstrate two techniques that improve the fluency and semantic accuracy of the generated text: The first technique samples multiple candidate text sequences from which the semantic parser chooses. The second trains the language model while keeping the semantic parser frozen to improve the semantic accuracy of the auto-encoder. We carry out experiments on the English WebNLG 3.0 data set, using BLEU to measure the fluency of generated text and standard parsing metrics to measure semantic accuracy. We show that our proposed approaches significantly improve on the greedy search baseline. Human evaluation corroborates the results of the automatic evaluation experiments.
Query Refinement Prompts for Closed-Book Long-Form Question Answering
Oct 31, 2022Large language models (LLMs) have been shown to perform well in answering questions and in producing long-form texts, both in few-shot closed-book settings. While the former can be validated using well-known evaluation metrics, the latter is difficult to evaluate. We resolve the difficulties to evaluate long-form output by doing both tasks at once -- to do question answering that requires long-form answers. Such questions tend to be multifaceted, i.e., they may have ambiguities and/or require information from multiple sources. To this end, we define query refinement prompts that encourage LLMs to explicitly express the multifacetedness in questions and generate long-form answers covering multiple facets of the question. Our experiments on two long-form question answering datasets, ASQA and AQuAMuSe, show that using our prompts allows us to outperform fully finetuned models in the closed book setting, as well as achieve results comparable to retrieve-then-generate open-book models.
Improving Low-Resource Cross-lingual Parsing with Expected Statistic Regularization
Oct 17, 2022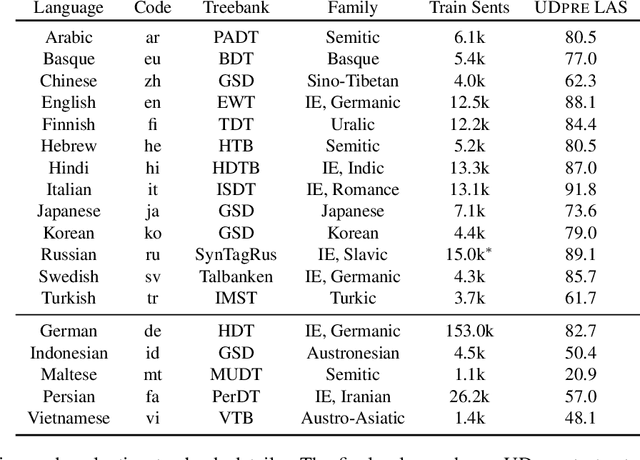
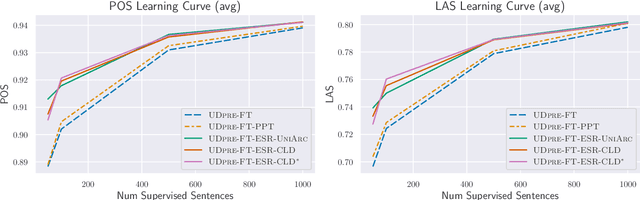
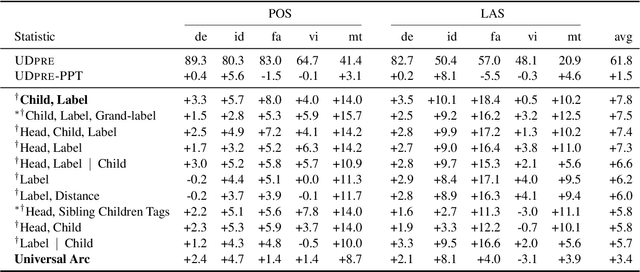
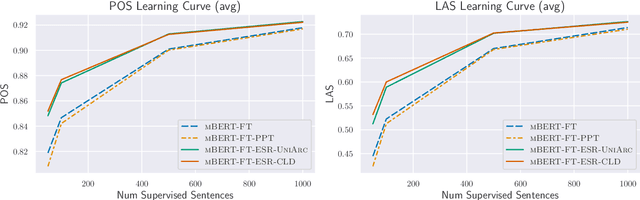
We present Expected Statistic Regularization (ESR), a novel regularization technique that utilizes low-order multi-task structural statistics to shape model distributions for semi-supervised learning on low-resource datasets. We study ESR in the context of cross-lingual transfer for syntactic analysis (POS tagging and labeled dependency parsing) and present several classes of low-order statistic functions that bear on model behavior. Experimentally, we evaluate the proposed statistics with ESR for unsupervised transfer on 5 diverse target languages and show that all statistics, when estimated accurately, yield improvements to both POS and LAS, with the best statistic improving POS by +7.0 and LAS by +8.5 on average. We also present semi-supervised transfer and learning curve experiments that show ESR provides significant gains over strong cross-lingual-transfer-plus-fine-tuning baselines for modest amounts of label data. These results indicate that ESR is a promising and complementary approach to model-transfer approaches for cross-lingual parsing.