 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASA: Cross-Attention via Self-Attention for Efficient Vision-Language Fusion
Dec 22, 2025Vision-language models (VLMs) are commonly trained by inserting image tokens from a pretrained vision encoder into the textual stream of a language model. This allows text and image information to fully attend to one another within the model, but becomes extremely costly for high-resolution images, long conversations, or streaming videos, both in memory and compute. VLMs leveraging cross-attention are an efficient alternative to token insertion but exhibit a clear performance gap, in particular on tasks involving fine-grained visual details. We find that a key to improving such models is to also enable local text-to-text interaction in the dedicated cross-attention layers. Building on this, we propose CASA, Cross-Attention via Self-Attention, a simple and efficient paradigm which substantially reduces the gap with full token insertion on common image understanding benchmarks, while enjoying the same scalability as cross-attention models when applied to long-context multimodal tasks such as streaming video captioning. For samples and code, please see our project page at https://kyutai.org/casa .
ARC-Encoder: learning compressed text representations for large language models
Oct 23, 2025



Recent techniques such as retrieval-augmented generation or chain-of-thought reasoning have led to longer contexts and increased inference costs. Context compression techniques can reduce these costs, but the most effective approaches require fine-tuning the target model or even modifying its architecture. This can degrade its general abilities when not used for this specific purpose. Here we explore an alternative approach: an encoder that compresses the context into continuous representations which replace token embeddings in decoder LLMs. First, we perform a systematic study of training strategies and architecture choices for the encoder. Our findings led to the design of an Adaptable text Representations Compressor, named ARC-Encoder, which outputs $x$-times fewer continuous representations (typically $x\!\in\!\{4,8\}$) than text tokens. We evaluate ARC-Encoder across a variety of LLM usage scenarios, ranging from in-context learning to context window extension, on both instruct and base decoders. Results show that ARC-Encoder achieves state-of-the-art performance on several benchmarks while improving computational efficiency at inference. Finally, we demonstrate that our models can be adapted to multiple decoders simultaneously, allowing a single encoder to generalize across different decoder LLMs. This makes ARC-Encoder a flexible and efficient solution for portable encoders that work seamlessly with multiple LLMs. We release a training code at https://github.com/kyutai-labs/ARC-Encoder , fine-tuning dataset and pretrained models are available at https://huggingface.co/collections/kyutai/arc-encoders-68ee18787301407d60a57047 .
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Sep 10, 2025We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
High-Fidelity Simultaneous Speech-To-Speech Translation
Feb 05, 2025



We introduce Hibiki, a decoder-only model for simultaneous speech translation. Hibiki leverages a multistream language model to synchronously process source and target speech, and jointly produces text and audio tokens to perform speech-to-text and speech-to-speech translation. We furthermore address the fundamental challenge of simultaneous interpretation, which unlike its consecutive counterpart, where one waits for the end of the source utterance to start translating, adapts its flow to accumulate just enough context to produce a correct translation in real-time, chunk by chunk. To do so, we introduce a weakly-supervised method that leverages the perplexity of an off-the-shelf text translation system to identify optimal delays on a per-word basis and create aligned synthetic data. After supervised training, Hibiki performs adaptive, simultaneous speech translation with vanilla temperature sampling. On a French-English simultaneous speech translation task, Hibiki demonstrates state-of-the-art performance in translation quality, speaker fidelity and naturalness. Moreover, the simplicity of its inference process makes it compatible with batched translation and even real-time on-device deployment. We provide examples as well as models and inference code.
Neutral residues: revisiting adapters for model extension
Oct 03, 2024



We address the problem of extending a pretrained large language model to a new domain that was not seen at training time, like adding a language for which the original model has seen no or little training data. Popular solutions like fine-tuning or low-rank adaptation are successful at domain adaptation, but formally they do not add any extra capacity and degrade the performance in the original domain. Our paper analyzes this extension problem under three angles: data, architecture and training procedure, which are advantageously considered jointly. In particular, we improve adapters and make it possible to learn an entire new language while ensuring that the output of the neural network is almost unchanged in the original domain. For this purpose, we modify the new residual blocks in a way that leads each new residual block to output near-zeros in the original domain. This solution of neutral residues, which borrows architectural components from mixture of experts, is effective: with only 20% extra learnable weights compared to an original model trained on English, we get results that are significantly better than concurrent approaches (fine-tuning, low-rank or vanilla adapters) in terms of the trade-off between learning a new language and not forgetting English.
Time Sensitive Knowledge Editing through Efficient Finetuning
Jun 06, 2024



Large Language Models (LLMs) have demonstrated impressive capability in different tasks and are bringing transformative changes to many domains. However, keeping the knowledge in LLMs up-to-date remains a challenge once pretraining is complete. It is thus essential to design effective methods to both update obsolete knowledge and induce new knowledge into LLMs. Existing locate-and-edit knowledge editing (KE) method suffers from two limitations. First, the post-edit LLMs by such methods generally have poor capability in answering complex queries that require multi-hop reasoning. Second, the long run-time of such locate-and-edit methods to perform knowledge edits make it infeasible for large scale KE in practice. In this paper, we explore Parameter-Efficient Fine-Tuning (PEFT) techniques as an alternative for KE. We curate a more comprehensive temporal KE dataset with both knowledge update and knowledge injection examples for KE performance benchmarking. We further probe the effect of fine-tuning on a range of layers in an LLM for the multi-hop QA task. We find that PEFT performs better than locate-and-edit techniques for time-sensitive knowledge edits.
PaSS: Parallel Speculative Sampling
Nov 22, 2023

Scaling the size of language models to tens of billions of parameters has led to impressive performance on a wide range of tasks. At generation, these models are used auto-regressively, requiring a forward pass for each generated token, and thus reading the full set of parameters from memory. This memory access forms the primary bottleneck for generation and it worsens as the model size increases. Moreover, executing a forward pass for multiple tokens in parallel often takes nearly the same time as it does for just one token. These two observations lead to the development of speculative sampling, where a second smaller model is used to draft a few tokens, that are then validated or rejected using a single forward pass of the large model. Unfortunately, this method requires two models that share the same tokenizer and thus limits its adoption. As an alternative, we propose to use parallel decoding as a way to draft multiple tokens from a single model with no computational cost, nor the need for a second model. Our approach only requires an additional input token that marks the words that will be generated simultaneously. We show promising performance (up to $30\%$ speed-up) while requiring only as few as $O(d_{emb})$ additional parameters.
LLaMA: Open and Efficient Foundation Language Models
Feb 27, 2023



We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
Augmented Language Models: a Survey
Feb 15, 2023



This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability, consistency, and scalability issues.
EditEval: An Instruction-Based Benchmark for Text Improvements
Sep 27, 2022
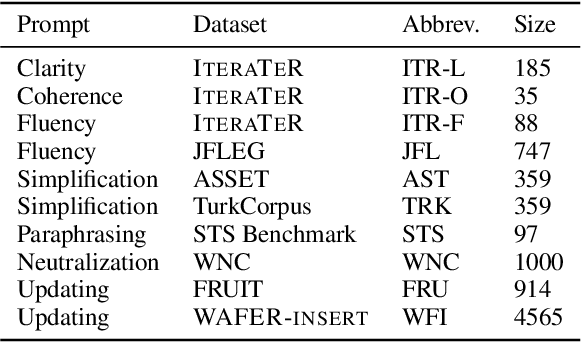
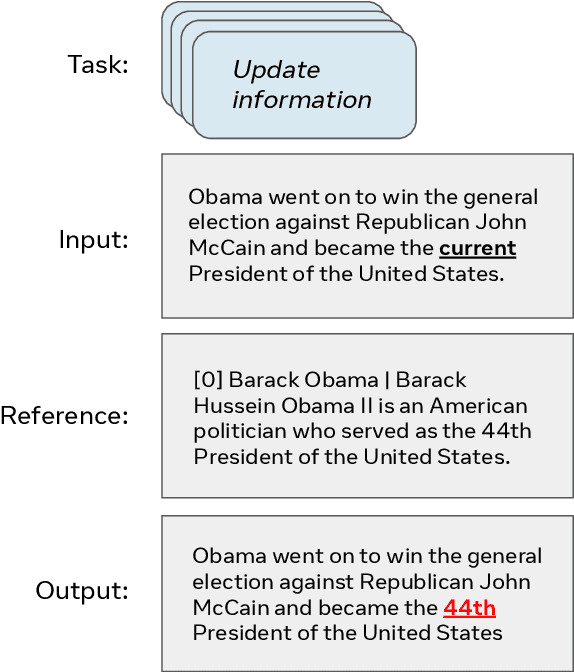
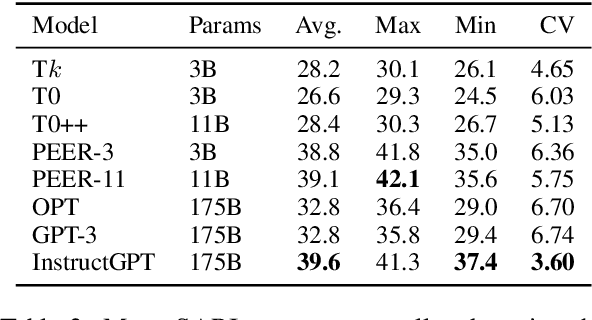
Evaluation of text generation to date has primarily focused on content created sequentially, rather than improvements on a piece of text. Writing, however, is naturally an iterative and incremental process that requires expertise in different modular skills such as fixing outdated information or making the style more consistent. Even so, comprehensive evaluation of a model's capacity to perform these skills and the ability to edit remains sparse. This work presents EditEval: An instruction-based, benchmark and evaluation suite that leverages high-quality existing and new datasets for automatic evaluation of editing capabilities such as making text more cohesive and paraphrasing. We evaluate several pre-trained models, which shows that InstructGPT and PEER perform the best, but that most baselines fall below the supervised SOTA, particularly when neutralizing and updating information. Our analysis also shows that commonly used metrics for editing tasks do not always correlate well, and that optimization for prompts with the highest performance does not necessarily entail the strongest robustness to different models. Through the release of this benchmark and a publicly available leaderboard challenge, we hope to unlock future research in developing models capable of iterative and more controllable editing.