 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Velocity: A Variance Perspective on Flow Matching
Feb 05, 2026While flow matching is elegant, its reliance on single-sample conditional velocities leads to high-variance training targets that destabilize optimization and slow convergence. By explicitly characterizing this variance, we identify 1) a high-variance regime near the prior, where optimization is challenging, and 2) a low-variance regime near the data distribution, where conditional and marginal velocities nearly coincide. Leveraging this insight, we propose Stable Velocity, a unified framework that improves both training and sampling. For training, we introduce Stable Velocity Matching (StableVM), an unbiased variance-reduction objective, along with Variance-Aware Representation Alignment (VA-REPA), which adaptively strengthen auxiliary supervision in the low-variance regime. For inference, we show that dynamics in the low-variance regime admit closed-form simplifications, enabling Stable Velocity Sampling (StableVS), a finetuning-free acceleration. Extensive experiments on ImageNet $256\times256$ and large pretrained text-to-image and text-to-video models, including SD3.5, Flux, Qwen-Image, and Wan2.2, demonstrate consistent improvements in training efficiency and more than $2\times$ faster sampling within the low-variance regime without degrading sample quality. Our code is available at https://github.com/linYDTHU/StableVelocity.
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Dec 26, 2025We introduce the Self-Evaluating Model (Self-E), a novel, from-scratch training approach for text-to-image generation that supports any-step inference. Self-E learns from data similarly to a Flow Matching model, while simultaneously employing a novel self-evaluation mechanism: it evaluates its own generated samples using its current score estimates, effectively serving as a dynamic self-teacher. Unlike traditional diffusion or flow models, it does not rely solely on local supervision, which typically necessitates many inference steps. Unlike distillation-based approaches, it does not require a pretrained teacher. This combination of instantaneous local learning and self-driven global matching bridges the gap between the two paradigms, enabling the training of a high-quality text-to-image model from scratch that excels even at very low step counts. Extensive experiments on large-scale text-to-image benchmarks show that Self-E not only excels in few-step generation, but is also competitive with state-of-the-art Flow Matching models at 50 steps. We further find that its performance improves monotonically as inference steps increase, enabling both ultra-fast few-step generation and high-quality long-trajectory sampling within a single unified model. To our knowledge, Self-E is the first from-scratch, any-step text-to-image model, offering a unified framework for efficient and scalable generation.
Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Dec 23, 2025Vision-language models (VLM) excel at general understanding yet remain weak at dynamic spatial reasoning (DSR), i.e., reasoning about the evolvement of object geometry and relationship in 3D space over time, largely due to the scarcity of scalable 4D-aware training resources. To bridge this gap across aspects of dataset, benchmark and model, we introduce DSR Suite. First, we propose an automated pipeline that generates multiple-choice question-answer pairs from in-the-wild videos for DSR. By leveraging modern vision foundation models, the pipeline extracts rich geometric and motion information, including camera poses, local point clouds, object masks, orientations, and 3D trajectories. These geometric cues enable the construction of DSR-Train for learning and further human-refined DSR-Bench for evaluation. Compared with previous works, our data emphasize (i) in-the-wild video sources, (ii) object- and scene-level 3D requirements, (iii) viewpoint transformations, (iv) multi-object interactions, and (v) fine-grained, procedural answers. Beyond data, we propose a lightweight Geometry Selection Module (GSM) to seamlessly integrate geometric priors into VLMs, which condenses question semantics and extracts question-relevant knowledge from pretrained 4D reconstruction priors into a compact set of geometry tokens. This targeted extraction avoids overwhelming the model with irrelevant knowledge. Experiments show that integrating DSR-Train and GSM into Qwen2.5-VL-7B significantly enhances its dynamic spatial reasoning capability, while maintaining accuracy on general video understanding benchmarks.
ASSIST-3D: Adapted Scene Synthesis for Class-Agnostic 3D Instance Segmentation
Dec 10, 2025Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.
Efficient lattice field theory simulation using adaptive normalizing flow on a resistive memory-based neural differential equation solver
Sep 16, 2025Lattice field theory (LFT) simulations underpin advances in classical statistical mechanics and quantum field theory, providing a unified computational framework across particle, nuclear, and condensed matter physics. However, the application of these methods to high-dimensional systems remains severely constrained by several challenges, including the prohibitive computational cost and limited parallelizability of conventional sampling algorithms such as hybrid Monte Carlo (HMC), the substantial training expense associated with traditional normalizing flow models, and the inherent energy inefficiency of digital hardware architectures. Here, we introduce a software-hardware co-design that integrates an adaptive normalizing flow (ANF) model with a resistive memory-based neural differential equation solver, enabling efficient generation of LFT configurations. Software-wise, ANF enables efficient parallel generation of statistically independent configurations, thereby reducing computational costs, while low-rank adaptation (LoRA) allows cost-effective fine-tuning across diverse simulation parameters. Hardware-wise, in-memory computing with resistive memory substantially enhances both parallelism and energy efficiency. We validate our approach on the scalar phi4 theory and the effective field theory of graphene wires, using a hybrid analog-digital neural differential equation solver equipped with a 180 nm resistive memory in-memory computing macro. Our co-design enables low-cost computation, achieving approximately 8.2-fold and 13.9-fold reductions in integrated autocorrelation time over HMC, while requiring fine-tuning of less than 8% of the weights via LoRA. Compared to state-of-the-art GPUs, our co-design achieves up to approximately 16.1- and 17.0-fold speedups for the two tasks, as well as 73.7- and 138.0-fold improvements in energy efficiency.
Understanding Data Influence with Differential Approximation
Aug 20, 2025Data plays a pivotal role in the groundbreaking advancements in artificial intelligence. The quantitative analysis of data significantly contributes to model training, enhancing both the efficiency and quality of data utilization. However, existing data analysis tools often lag in accuracy. For instance, many of these tools even assume that the loss function of neural networks is convex. These limitations make it challenging to implement current methods effectively. In this paper, we introduce a new formulation to approximate a sample's influence by accumulating the differences in influence between consecutive learning steps, which we term Diff-In. Specifically, we formulate the sample-wise influence as the cumulative sum of its changes/differences across successive training iterations. By employing second-order approximations, we approximate these difference terms with high accuracy while eliminating the need for model convexity required by existing methods. Despite being a second-order method, Diff-In maintains computational complexity comparable to that of first-order methods and remains scalable. This efficiency is achieved by computing the product of the Hessian and gradient, which can be efficiently approximated using finite differences of first-order gradients. We assess the approximation accuracy of Diff-In both theoretically and empirically. Our theoretical analysis demonstrates that Diff-In achieves significantly lower approximation error compared to existing influence estimators. Extensive experiments further confirm its superior performance across multiple benchmark datasets in three data-centric tasks: data cleaning, data deletion, and coreset selection. Notably, our experiments on data pruning for large-scale vision-language pre-training show that Diff-In can scale to millions of data points and outperforms strong baselines.
NoteIt: A System Converting Instructional Videos to Interactable Notes Through Multimodal Video Understanding
Aug 20, 2025



Users often take notes for instructional videos to access key knowledge later without revisiting long videos. Automated note generation tools enable users to obtain informative notes efficiently. However, notes generated by existing research or off-the-shelf tools fail to preserve the information conveyed in the original videos comprehensively, nor can they satisfy users' expectations for diverse presentation formats and interactive features when using notes digitally. In this work, we present NoteIt, a system, which automatically converts instructional videos to interactable notes using a novel pipeline that faithfully extracts hierarchical structure and multimodal key information from videos. With NoteIt's interface, users can interact with the system to further customize the content and presentation formats of the notes according to their preferences. We conducted both a technical evaluation and a comparison user study (N=36). The solid performance in objective metrics and the positive user feedback demonstrated the effectiveness of the pipeline and the overall usability of NoteIt. Project website: https://zhaorunning.github.io/NoteIt/
S^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025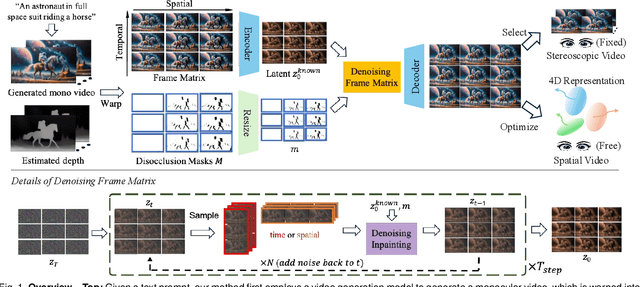

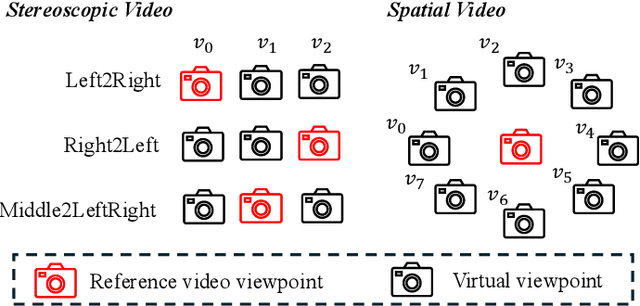

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Trustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025



The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.