 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025



The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.
FeBiM: Efficient and Compact Bayesian Inference Engine Empowered with Ferroelectric In-Memory Computing
Oct 25, 2024



In scenarios with limited training data or where explainability is crucial, conventional neural network-based machine learning models often face challenges. In contrast, Bayesian inference-based algorithms excel in providing interpretable predictions and reliable uncertainty estimation in these scenarios. While many state-of-the-art in-memory computing (IMC) architectures leverage emerging non-volatile memory (NVM) technologies to offer unparalleled computing capacity and energy efficiency for neural network workloads, their application in Bayesian inference is limited. This is because the core operations in Bayesian inference differ significantly from the multiplication-accumulation (MAC) operations common in neural networks, rendering them generally unsuitable for direct implementation in most existing IMC designs. In this paper, we propose FeBiM, an efficient and compact Bayesian inference engine powered by multi-bit ferroelectric field-effect transistor (FeFET)-based IMC. FeBiM effectively encodes the trained probabilities of a Bayesian inference model within a compact FeFET-based crossbar. It maps quantized logarithmic probabilities to discrete FeFET states. As a result, the accumulated outputs of the crossbar naturally represent the posterior probabilities, i.e., the Bayesian inference model's output given a set of observations. This approach enables efficient in-memory Bayesian inference without the need for additional calculation circuitry. As the first FeFET-based in-memory Bayesian inference engine, FeBiM achieves an impressive storage density of 26.32 Mb/mm$^{2}$ and a computing efficiency of 581.40 TOPS/W in a representative Bayesian classification task. These results demonstrate 10.7$\times$/43.4$\times$ improvement in compactness/efficiency compared to the state-of-the-art hardware implementation of Bayesian inference.
Experimentally realized memristive memory augmented neural network
Apr 15, 2022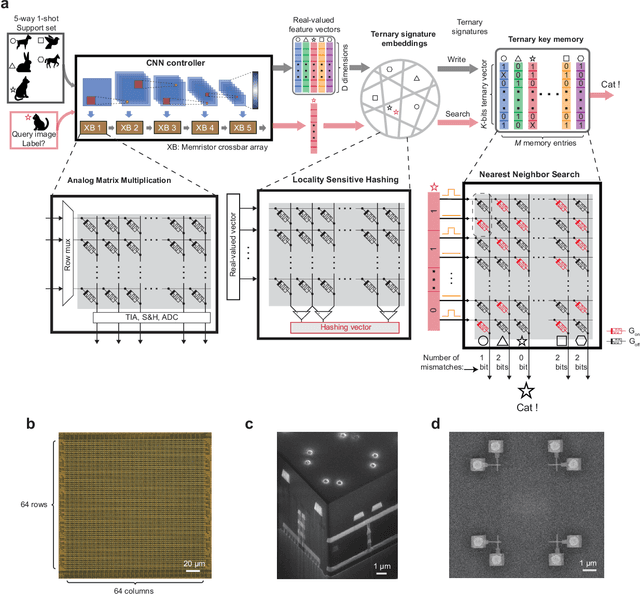
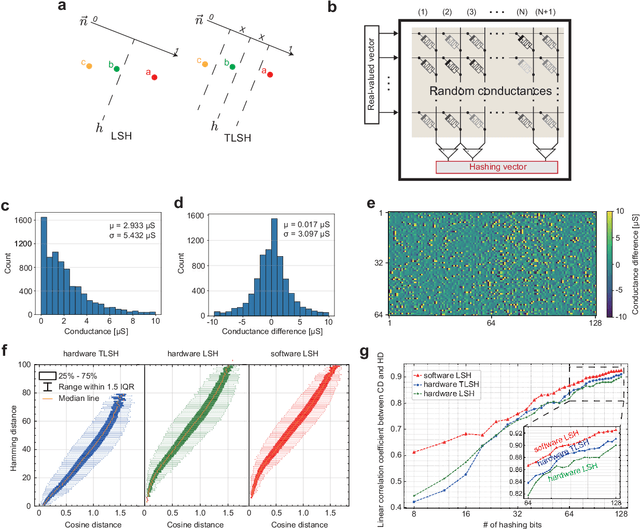
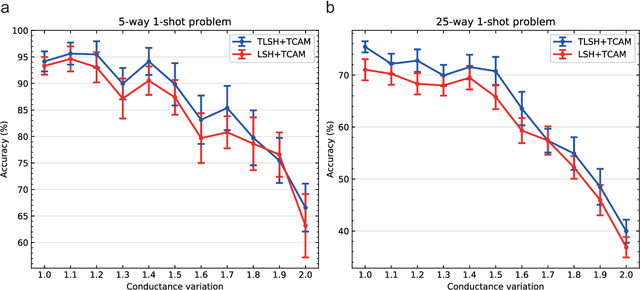
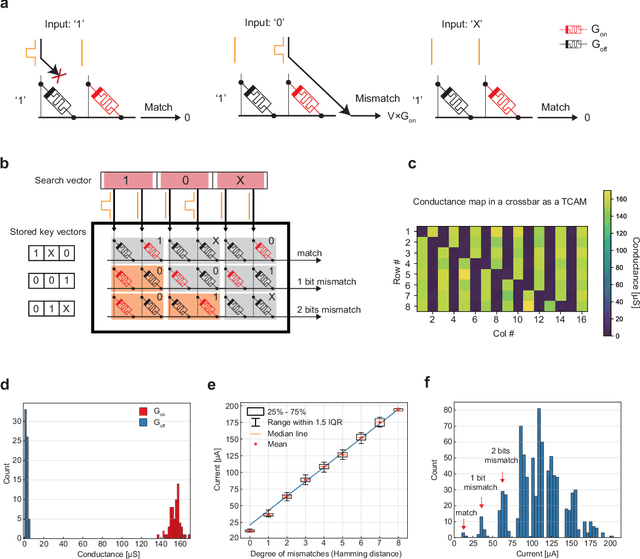
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory augmented neural network has been proposed to achieve the goal, but the memory module has to be stored in an off-chip memory due to its size. Therefore the practical use has been heavily limited. Previous works on emerging memory-based implementation have difficulties in scaling up because different modules with various structures are difficult to integrate on the same chip and the small sense margin of the content addressable memory for the memory module heavily limited the degree of mismatch calculation. In this work, we implement the entire memory augmented neural network architecture in a fully integrated memristive crossbar platform and achieve an accuracy that closely matches standard software on digital hardware for the Omniglot dataset. The successful demonstration is supported by implementing new functions in crossbars in addition to widely reported matrix multiplications. For example, the locality-sensitive hashing operation is implemented in crossbar arrays by exploiting the intrinsic stochasticity of memristor devices. Besides, the content-addressable memory module is realized in crossbars, which also supports the degree of mismatches. Simulations based on experimentally validated models show such an implementation can be efficiently scaled up for one-shot learning on the Mini-ImageNet dataset. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms not possible in conventional hardware.