 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectMorpher: 3D-Aware Image Editing via Deformable 3DGS Models
Mar 30, 2026Achieving precise, object-level control in image editing remains challenging: 2D methods lack 3D awareness and often yield ambiguous or implausible results, while existing 3D-aware approaches rely on heavy optimization or incomplete monocular reconstructions. We present ObjectMorpher, a unified, interactive framework that converts ambiguous 2D edits into geometry-grounded operations. ObjectMorpher lifts target instances with an image-to-3D generator into editable 3D Gaussian Splatting (3DGS), enabling fast, identity-preserving manipulation. Users drag control points; a graph-based non-rigid deformation with as-rigid-as-possible (ARAP) constraints ensures physically sensible shape and pose changes. A composite diffusion module harmonizes lighting, color, and boundaries for seamless reintegration. Across diverse categories, ObjectMorpher delivers fine-grained, photorealistic edits with superior controllability and efficiency, outperforming 2D drag and 3D-aware baselines on KID, LPIPS, SIFID, and user preference.
Egocentric Visibility-Aware Human Pose Estimation
Feb 27, 2026Egocentric human pose estimation (HPE) using a head-mounted device is crucial for various VR and AR applications, but it faces significant challenges due to keypoint invisibility. Nevertheless, none of the existing egocentric HPE datasets provide keypoint visibility annotations, and the existing methods often overlook the invisibility problem, treating visible and invisible keypoints indiscriminately during estimation. As a result, their capacity to accurately predict visible keypoints is compromised. In this paper, we first present Eva-3M, a large-scale egocentric visibility-aware HPE dataset comprising over 3.0M frames, with 435K of them annotated with keypoint visibility labels. Additionally, we augment the existing EMHI dataset with keypoint visibility annotations to further facilitate the research in this direction. Furthermore, we propose EvaPose, a novel egocentric visibility-aware HPE method that explicitly incorporates visibility information to enhance pose estimation accuracy. Extensive experiments validate the significant value of ground-truth visibility labels in egocentric HPE settings, and demonstrate that our EvaPose achieves state-of-the-art performance in both Eva-3M and EMHI datasets.
S^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025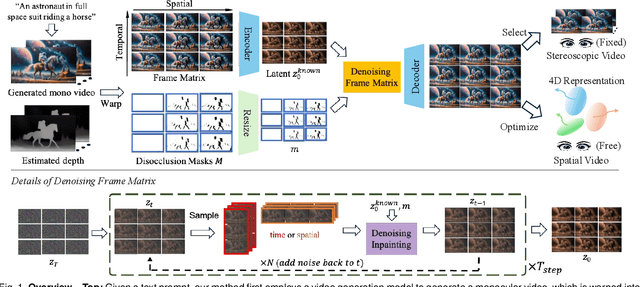

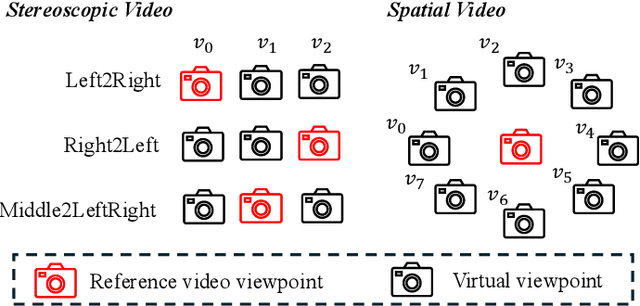

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
Sequential LLM Framework for Fashion Recommendation
Oct 15, 2024



The fashion industry is one of the leading domains in the global e-commerce sector, prompting major online retailers to employ recommendation systems for product suggestions and customer convenience. While recommendation systems have been widely studied, most are designed for general e-commerce problems and struggle with the unique challenges of the fashion domain. To address these issues, we propose a sequential fashion recommendation framework that leverages a pre-trained large language model (LLM) enhanced with recommendation-specific prompts. Our framework employs parameter-efficient fine-tuning with extensive fashion data and introduces a novel mix-up-based retrieval technique for translating text into relevant product suggestions. Extensive experiments show our proposed framework significantly enhances fashion recommendation performance.
EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Aug 30, 2024



Egocentric human pose estimation (HPE) using wearable sensors is essential for VR/AR applications. Most methods rely solely on either egocentric-view images or sparse Inertial Measurement Unit (IMU) signals, leading to inaccuracies due to self-occlusion in images or the sparseness and drift of inertial sensors. Most importantly, the lack of real-world datasets containing both modalities is a major obstacle to progress in this field. To overcome the barrier, we propose EMHI, a multimodal \textbf{E}gocentric human \textbf{M}otion dataset with \textbf{H}ead-Mounted Display (HMD) and body-worn \textbf{I}MUs, with all data collected under the real VR product suite. Specifically, EMHI provides synchronized stereo images from downward-sloping cameras on the headset and IMU data from body-worn sensors, along with pose annotations in SMPL format. This dataset consists of 885 sequences captured by 58 subjects performing 39 actions, totaling about 28.5 hours of recording. We evaluate the annotations by comparing them with optical marker-based SMPL fitting results. To substantiate the reliability of our dataset, we introduce MEPoser, a new baseline method for multimodal egocentric HPE, which employs a multimodal fusion encoder, temporal feature encoder, and MLP-based regression heads. The experiments on EMHI show that MEPoser outperforms existing single-modal methods and demonstrates the value of our dataset in solving the problem of egocentric HPE. We believe the release of EMHI and the method could advance the research of egocentric HPE and expedite the practical implementation of this technology in VR/AR products.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024



Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
SVG: 3D Stereoscopic Video Generation via Denoising Frame Matrix
Jun 29, 2024



Video generation models have demonstrated great capabilities of producing impressive monocular videos, however, the generation of 3D stereoscopic video remains under-explored. We propose a pose-free and training-free approach for generating 3D stereoscopic videos using an off-the-shelf monocular video generation model. Our method warps a generated monocular video into camera views on stereoscopic baseline using estimated video depth, and employs a novel frame matrix video inpainting framework. The framework leverages the video generation model to inpaint frames observed from different timestamps and views. This effective approach generates consistent and semantically coherent stereoscopic videos without scene optimization or model fine-tuning. Moreover, we develop a disocclusion boundary re-injection scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, including Sora [4 ], Lumiere [2], WALT [8 ], and Zeroscope [ 42]. The experiments demonstrate that our method has a significant improvement over previous methods. The code will be released at \url{https://daipengwa.github.io/SVG_ProjectPage}.
EIVEN: Efficient Implicit Attribute Value Extraction using Multimodal LLM
Apr 13, 2024



In e-commerce, accurately extracting product attribute values from multimodal data is crucial for improving user experience and operational efficiency of retailers. However, previous approaches to multimodal attribute value extraction often struggle with implicit attribute values embedded in images or text, rely heavily on extensive labeled data, and can easily confuse similar attribute values. To address these issues, we introduce EIVEN, a data- and parameter-efficient generative framework that pioneers the use of multimodal LLM for implicit attribute value extraction. EIVEN leverages the rich inherent knowledge of a pre-trained LLM and vision encoder to reduce reliance on labeled data. We also introduce a novel Learning-by-Comparison technique to reduce model confusion by enforcing attribute value comparison and difference identification. Additionally, we construct initial open-source datasets for multimodal implicit attribute value extraction. Our extensive experiments reveal that EIVEN significantly outperforms existing methods in extracting implicit attribute values while requiring less labeled data.
Total-Decom: Decomposed 3D Scene Reconstruction with Minimal Interaction
Mar 30, 2024



Scene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing. The code is available at https://github.com/CVMI-Lab/Total-Decom.git.