 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Velocity: A Variance Perspective on Flow Matching
Feb 05, 2026While flow matching is elegant, its reliance on single-sample conditional velocities leads to high-variance training targets that destabilize optimization and slow convergence. By explicitly characterizing this variance, we identify 1) a high-variance regime near the prior, where optimization is challenging, and 2) a low-variance regime near the data distribution, where conditional and marginal velocities nearly coincide. Leveraging this insight, we propose Stable Velocity, a unified framework that improves both training and sampling. For training, we introduce Stable Velocity Matching (StableVM), an unbiased variance-reduction objective, along with Variance-Aware Representation Alignment (VA-REPA), which adaptively strengthen auxiliary supervision in the low-variance regime. For inference, we show that dynamics in the low-variance regime admit closed-form simplifications, enabling Stable Velocity Sampling (StableVS), a finetuning-free acceleration. Extensive experiments on ImageNet $256\times256$ and large pretrained text-to-image and text-to-video models, including SD3.5, Flux, Qwen-Image, and Wan2.2, demonstrate consistent improvements in training efficiency and more than $2\times$ faster sampling within the low-variance regime without degrading sample quality. Our code is available at https://github.com/linYDTHU/StableVelocity.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025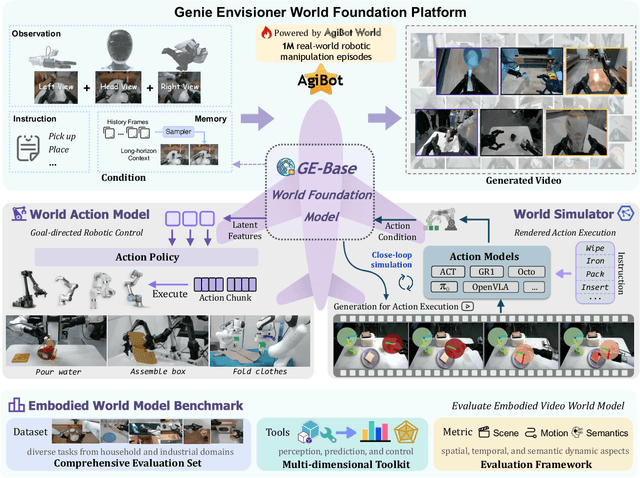
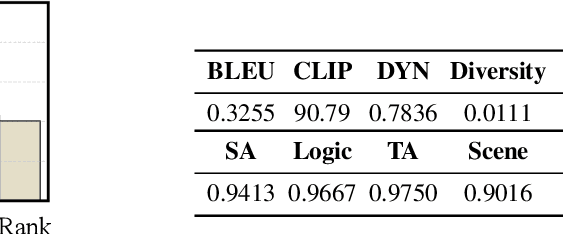

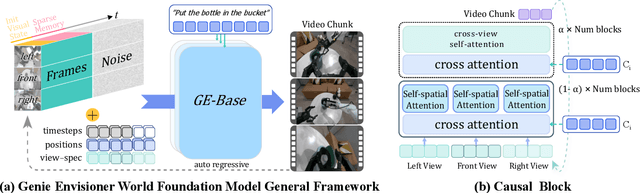
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
UAV-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UAV Imitation Learning
May 21, 2025Unmanned Aerial Vehicles (UAVs) are evolving into language-interactive platforms, enabling more intuitive forms of human-drone interaction. While prior works have primarily focused on high-level planning and long-horizon navigation, we shift attention to language-guided fine-grained trajectory control, where UAVs execute short-range, reactive flight behaviors in response to language instructions. We formalize this problem as the Flying-on-a-Word (Flow) task and introduce UAV imitation learning as an effective approach. In this framework, UAVs learn fine-grained control policies by mimicking expert pilot trajectories paired with atomic language instructions. To support this paradigm, we present UAV-Flow, the first real-world benchmark for language-conditioned, fine-grained UAV control. It includes a task formulation, a large-scale dataset collected in diverse environments, a deployable control framework, and a simulation suite for systematic evaluation. Our design enables UAVs to closely imitate the precise, expert-level flight trajectories of human pilots and supports direct deployment without sim-to-real gap. We conduct extensive experiments on UAV-Flow, benchmarking VLN and VLA paradigms. Results show that VLA models are superior to VLN baselines and highlight the critical role of spatial grounding in the fine-grained Flow setting.
Advancing Generalizable Tumor Segmentation with Anomaly-Aware Open-Vocabulary Attention Maps and Frozen Foundation Diffusion Models
May 05, 2025We explore Generalizable Tumor Segmentation, aiming to train a single model for zero-shot tumor segmentation across diverse anatomical regions. Existing methods face limitations related to segmentation quality, scalability, and the range of applicable imaging modalities. In this paper, we uncover the potential of the internal representations within frozen medical foundation diffusion models as highly efficient zero-shot learners for tumor segmentation by introducing a novel framework named DiffuGTS. DiffuGTS creates anomaly-aware open-vocabulary attention maps based on text prompts to enable generalizable anomaly segmentation without being restricted by a predefined training category list. To further improve and refine anomaly segmentation masks, DiffuGTS leverages the diffusion model, transforming pathological regions into high-quality pseudo-healthy counterparts through latent space inpainting, and applies a novel pixel-level and feature-level residual learning approach, resulting in segmentation masks with significantly enhanced quality and generalization. Comprehensive experiments on four datasets and seven tumor categories demonstrate the superior performance of our method, surpassing current state-of-the-art models across multiple zero-shot settings. Codes are available at https://github.com/Yankai96/DiffuGTS.
QDM: Quadtree-Based Region-Adaptive Sparse Diffusion Models for Efficient Image Super-Resolution
Mar 15, 2025



Deep learning-based super-resolution (SR) methods often perform pixel-wise computations uniformly across entire images, even in homogeneous regions where high-resolution refinement is redundant. We propose the Quadtree Diffusion Model (QDM), a region-adaptive diffusion framework that leverages a quadtree structure to selectively enhance detail-rich regions while reducing computations in homogeneous areas. By guiding the diffusion with a quadtree derived from the low-quality input, QDM identifies key regions-represented by leaf nodes-where fine detail is essential and applies minimal refinement elsewhere. This mask-guided, two-stream architecture adaptively balances quality and efficiency, producing high-fidelity outputs with low computational redundancy. Experiments demonstrate QDM's effectiveness in high-resolution SR tasks across diverse image types, particularly in medical imaging (e.g., CT scans), where large homogeneous regions are prevalent. Furthermore, QDM outperforms or is comparable to state-of-the-art SR methods on standard benchmarks while significantly reducing computational costs, highlighting its efficiency and suitability for resource-limited environments. Our code is available at https://github.com/linYDTHU/QDM.
Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
Oct 10, 2024



Developing agents capable of navigating to a target location based on language instructions and visual information, known as vision-language navigation (VLN), has attracted widespread interest. Most research has focused on ground-based agents, while UAV-based VLN remains relatively underexplored. Recent efforts in UAV vision-language navigation predominantly adopt ground-based VLN settings, relying on predefined discrete action spaces and neglecting the inherent disparities in agent movement dynamics and the complexity of navigation tasks between ground and aerial environments. To address these disparities and challenges, we propose solutions from three perspectives: platform, benchmark, and methodology. To enable realistic UAV trajectory simulation in VLN tasks, we propose the OpenUAV platform, which features diverse environments, realistic flight control, and extensive algorithmic support. We further construct a target-oriented VLN dataset consisting of approximately 12k trajectories on this platform, serving as the first dataset specifically designed for realistic UAV VLN tasks. To tackle the challenges posed by complex aerial environments, we propose an assistant-guided UAV object search benchmark called UAV-Need-Help, which provides varying levels of guidance information to help UAVs better accomplish realistic VLN tasks. We also propose a UAV navigation LLM that, given multi-view images, task descriptions, and assistant instructions, leverages the multimodal understanding capabilities of the MLLM to jointly process visual and textual information, and performs hierarchical trajectory generation. The evaluation results of our method significantly outperform the baseline models, while there remains a considerable gap between our results and those achieved by human operators, underscoring the challenge presented by the UAV-Need-Help task.
SymmetricDiffusers: Learning Discrete Diffusion on Finite Symmetric Groups
Oct 03, 2024



Finite symmetric groups $S_n$ are essential in fields such as combinatorics, physics, and chemistry. However, learning a probability distribution over $S_n$ poses significant challenges due to its intractable size and discrete nature. In this paper, we introduce SymmetricDiffusers, a novel discrete diffusion model that simplifies the task of learning a complicated distribution over $S_n$ by decomposing it into learning simpler transitions of the reverse diffusion using deep neural networks. We identify the riffle shuffle as an effective forward transition and provide empirical guidelines for selecting the diffusion length based on the theory of random walks on finite groups. Additionally, we propose a generalized Plackett-Luce (PL) distribution for the reverse transition, which is provably more expressive than the PL distribution. We further introduce a theoretically grounded "denoising schedule" to improve sampling and learning efficiency. Extensive experiments show that our model achieves state-of-the-art or comparable performances on solving tasks including sorting 4-digit MNIST images, jigsaw puzzles, and traveling salesman problems. Our code is released at https://github.com/NickZhang53/SymmetricDiffusers.
Realistic Rainy Weather Simulation for LiDARs in CARLA Simulator
Dec 20, 2023



Employing data augmentation methods to enhance perception performance in adverse weather has attracted considerable attention recently. Most of the LiDAR augmentation methods post-process the existing dataset by physics-based models or machine-learning methods. However, due to the limited environmental annotations and the fixed vehicle trajectories in the existing dataset, it is challenging to edit the scene and expand the diversity of traffic flow and scenario. To this end, we propose a simulator-based physical modeling approach to augment LiDAR data in rainy weather in order to improve the perception performance of LiDAR in this scenario. We complete the modeling task of the rainy weather in the CARLA simulator and establish a pipeline for LiDAR data collection. In particular, we pay special attention to the spray and splash rolled up by the wheels of surrounding vehicles in rain and complete the simulation of this special scenario through the Spray Emitter method we developed. In addition, we examine the influence of different weather conditions on the intensity of the LiDAR echo, develop a prediction network for the intensity of the LiDAR echo, and complete the simulation of 4-feat LiDAR point cloud data. In the experiment, we observe that the model augmented by the synthetic data improves the object detection task's performance in the rainy sequence of the Waymo Open Dataset. Both the code and the dataset will be made publicly available at https://github.com/PJLab-ADG/PCSim#rainypcsim.
ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
Sep 25, 2023



Domain shifts such as sensor type changes and geographical situation variations are prevalent in Autonomous Driving (AD), which poses a challenge since AD model relying on the previous-domain knowledge can be hardly directly deployed to a new domain without additional costs. In this paper, we provide a new perspective and approach of alleviating the domain shifts, by proposing a Reconstruction-Simulation-Perception (ReSimAD) scheme. Specifically, the implicit reconstruction process is based on the knowledge from the previous old domain, aiming to convert the domain-related knowledge into domain-invariant representations, e.g., 3D scene-level meshes. Besides, the point clouds simulation process of multiple new domains is conditioned on the above reconstructed 3D meshes, where the target-domain-like simulation samples can be obtained, thus reducing the cost of collecting and annotating new-domain data for the subsequent perception process. For experiments, we consider different cross-domain situations such as Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE, etc, to verify the zero-shot target-domain perception using ReSimAD. Results demonstrate that our method is beneficial to boost the domain generalization ability, even promising for 3D pre-training.
On Sparse Modern Hopfield Model
Sep 22, 2023We introduce the sparse modern Hopfield model as a sparse extension of the modern Hopfield model. Like its dense counterpart, the sparse modern Hopfield model equips a memory-retrieval dynamics whose one-step approximation corresponds to the sparse attention mechanism. Theoretically, our key contribution is a principled derivation of a closed-form sparse Hopfield energy using the convex conjugate of the sparse entropic regularizer. Building upon this, we derive the sparse memory retrieval dynamics from the sparse energy function and show its one-step approximation is equivalent to the sparse-structured attention. Importantly, we provide a sparsity-dependent memory retrieval error bound which is provably tighter than its dense analog. The conditions for the benefits of sparsity to arise are therefore identified and discussed. In addition, we show that the sparse modern Hopfield model maintains the robust theoretical properties of its dense counterpart, including rapid fixed point convergence and exponential memory capacity. Empirically, we use both synthetic and real-world datasets to demonstrate that the sparse Hopfield model outperforms its dense counterpart in many situations.