 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Fidelity Reconstruction via Improved Consistency-Distilled Flow Matching for Dynamical Systems
May 07, 2026Reconstructing high-fidelity flow fields from low-fidelity observations is a central problem in scientific machine learning, yet recent diffusion and flow-matching models typically rely on iterative sampling, making them costly for latency-sensitive workflows such as ensemble forecasting, real-time visualization, and simulation-in-the-loop inference. We study whether a high-fidelity flow-matching generative model can be compressed into a compact one-step model for fast scientific flow reconstruction. Our approach distills an optimal-transport flow-matching teacher into a one-step consistency model. Low-fidelity observations are incorporated at inference by initializing the generative trajectory from a noised observation along the transport path, allowing an unconditional high-fidelity flow model to perform conditional reconstruction without retraining the teacher. We evaluate this distillation strategy on three fluid benchmarks, Smoke Buoyancy, Turbulent Channel Flow, and Kolmogorov Flow, using coarse-to-fine reconstruction as a controlled testbed at field sizes up to $256 \times 256$. Across these settings, the distilled student retains similar performance of the teacher's model on spectrum metrics, while using roughly half as many parameters and achieving a $12\times$ inference speedup over the flow-matching teacher. Under the same training budget, the distilled student also outperforms a one-step consistency model trained directly from scratch by $23.1\%$ in SSIM, showing that teacher distillation improves training efficiency rather than merely accelerating sampling. These results suggest a promising route for turning future high-capacity scientific generative models into compact reconstruction models that are faster to train, cheaper to run, and easier to deploy.
Understanding Data Influence with Differential Approximation
Aug 20, 2025Data plays a pivotal role in the groundbreaking advancements in artificial intelligence. The quantitative analysis of data significantly contributes to model training, enhancing both the efficiency and quality of data utilization. However, existing data analysis tools often lag in accuracy. For instance, many of these tools even assume that the loss function of neural networks is convex. These limitations make it challenging to implement current methods effectively. In this paper, we introduce a new formulation to approximate a sample's influence by accumulating the differences in influence between consecutive learning steps, which we term Diff-In. Specifically, we formulate the sample-wise influence as the cumulative sum of its changes/differences across successive training iterations. By employing second-order approximations, we approximate these difference terms with high accuracy while eliminating the need for model convexity required by existing methods. Despite being a second-order method, Diff-In maintains computational complexity comparable to that of first-order methods and remains scalable. This efficiency is achieved by computing the product of the Hessian and gradient, which can be efficiently approximated using finite differences of first-order gradients. We assess the approximation accuracy of Diff-In both theoretically and empirically. Our theoretical analysis demonstrates that Diff-In achieves significantly lower approximation error compared to existing influence estimators. Extensive experiments further confirm its superior performance across multiple benchmark datasets in three data-centric tasks: data cleaning, data deletion, and coreset selection. Notably, our experiments on data pruning for large-scale vision-language pre-training show that Diff-In can scale to millions of data points and outperforms strong baselines.
Efficient and accurate neural field reconstruction using resistive memory
Apr 15, 2024



Human beings construct perception of space by integrating sparse observations into massively interconnected synapses and neurons, offering a superior parallelism and efficiency. Replicating this capability in AI finds wide applications in medical imaging, AR/VR, and embodied AI, where input data is often sparse and computing resources are limited. However, traditional signal reconstruction methods on digital computers face both software and hardware challenges. On the software front, difficulties arise from storage inefficiencies in conventional explicit signal representation. Hardware obstacles include the von Neumann bottleneck, which limits data transfer between the CPU and memory, and the limitations of CMOS circuits in supporting parallel processing. We propose a systematic approach with software-hardware co-optimizations for signal reconstruction from sparse inputs. Software-wise, we employ neural field to implicitly represent signals via neural networks, which is further compressed using low-rank decomposition and structured pruning. Hardware-wise, we design a resistive memory-based computing-in-memory (CIM) platform, featuring a Gaussian Encoder (GE) and an MLP Processing Engine (PE). The GE harnesses the intrinsic stochasticity of resistive memory for efficient input encoding, while the PE achieves precise weight mapping through a Hardware-Aware Quantization (HAQ) circuit. We demonstrate the system's efficacy on a 40nm 256Kb resistive memory-based in-memory computing macro, achieving huge energy efficiency and parallelism improvements without compromising reconstruction quality in tasks like 3D CT sparse reconstruction, novel view synthesis, and novel view synthesis for dynamic scenes. This work advances the AI-driven signal restoration technology and paves the way for future efficient and robust medical AI and 3D vision applications.
3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Mar 30, 2024In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians' opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
DO3D: Self-supervised Learning of Decomposed Object-aware 3D Motion and Depth from Monocular Videos
Mar 09, 2024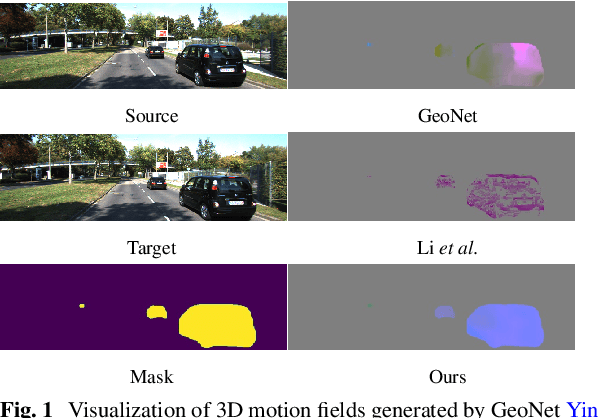
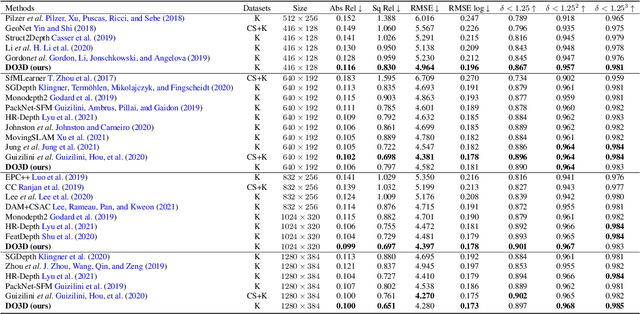
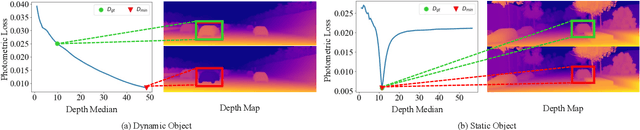

Although considerable advancements have been attained in self-supervised depth estimation from monocular videos, most existing methods often treat all objects in a video as static entities, which however violates the dynamic nature of real-world scenes and fails to model the geometry and motion of moving objects. In this paper, we propose a self-supervised method to jointly learn 3D motion and depth from monocular videos. Our system contains a depth estimation module to predict depth, and a new decomposed object-wise 3D motion (DO3D) estimation module to predict ego-motion and 3D object motion. Depth and motion networks work collaboratively to faithfully model the geometry and dynamics of real-world scenes, which, in turn, benefits both depth and 3D motion estimation. Their predictions are further combined to synthesize a novel video frame for self-supervised training. As a core component of our framework, DO3D is a new motion disentanglement module that learns to predict camera ego-motion and instance-aware 3D object motion separately. To alleviate the difficulties in estimating non-rigid 3D object motions, they are decomposed to object-wise 6-DoF global transformations and a pixel-wise local 3D motion deformation field. Qualitative and quantitative experiments are conducted on three benchmark datasets, including KITTI, Cityscapes, and VKITTI2, where our model delivers superior performance in all evaluated settings. For the depth estimation task, our model outperforms all compared research works in the high-resolution setting, attaining an absolute relative depth error (abs rel) of 0.099 on the KITTI benchmark. Besides, our optical flow estimation results (an overall EPE of 7.09 on KITTI) also surpass state-of-the-art methods and largely improve the estimation of dynamic regions, demonstrating the effectiveness of our motion model. Our code will be available.
Speech2Lip: High-fidelity Speech to Lip Generation by Learning from a Short Video
Sep 09, 2023



Synthesizing realistic videos according to a given speech is still an open challenge. Previous works have been plagued by issues such as inaccurate lip shape generation and poor image quality. The key reason is that only motions and appearances on limited facial areas (e.g., lip area) are mainly driven by the input speech. Therefore, directly learning a mapping function from speech to the entire head image is prone to ambiguity, particularly when using a short video for training. We thus propose a decomposition-synthesis-composition framework named Speech to Lip (Speech2Lip) that disentangles speech-sensitive and speech-insensitive motion/appearance to facilitate effective learning from limited training data, resulting in the generation of natural-looking videos. First, given a fixed head pose (i.e., canonical space), we present a speech-driven implicit model for lip image generation which concentrates on learning speech-sensitive motion and appearance. Next, to model the major speech-insensitive motion (i.e., head movement), we introduce a geometry-aware mutual explicit mapping (GAMEM) module that establishes geometric mappings between different head poses. This allows us to paste generated lip images at the canonical space onto head images with arbitrary poses and synthesize talking videos with natural head movements. In addition, a Blend-Net and a contrastive sync loss are introduced to enhance the overall synthesis performance. Quantitative and qualitative results on three benchmarks demonstrate that our model can be trained by a video of just a few minutes in length and achieve state-of-the-art performance in both visual quality and speech-visual synchronization. Code: https://github.com/CVMI-Lab/Speech2Lip.