 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations
May 27, 2025While large language models (LLMs) with Chain-of-Thought (CoT) reasoning excel in mathematics and coding, their potential for systematic reasoning in chemistry, a domain demanding rigorous structural analysis for real-world tasks like drug design and reaction engineering, remains untapped. Current benchmarks focus on simple knowledge retrieval, neglecting step-by-step reasoning required for complex tasks such as molecular optimization and reaction prediction. To address this, we introduce ChemCoTBench, a reasoning framework that bridges molecular structure understanding with arithmetic-inspired operations, including addition, deletion, and substitution, to formalize chemical problem-solving into transparent, step-by-step workflows. By treating molecular transformations as modular "chemical operations", the framework enables slow-thinking reasoning, mirroring the logic of mathematical proofs while grounding solutions in real-world chemical constraints. We evaluate models on two high-impact tasks: Molecular Property Optimization and Chemical Reaction Prediction. These tasks mirror real-world challenges while providing structured evaluability. By providing annotated datasets, a reasoning taxonomy, and baseline evaluations, ChemCoTBench bridges the gap between abstract reasoning methods and practical chemical discovery, establishing a foundation for advancing LLMs as tools for AI-driven scientific innovation.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025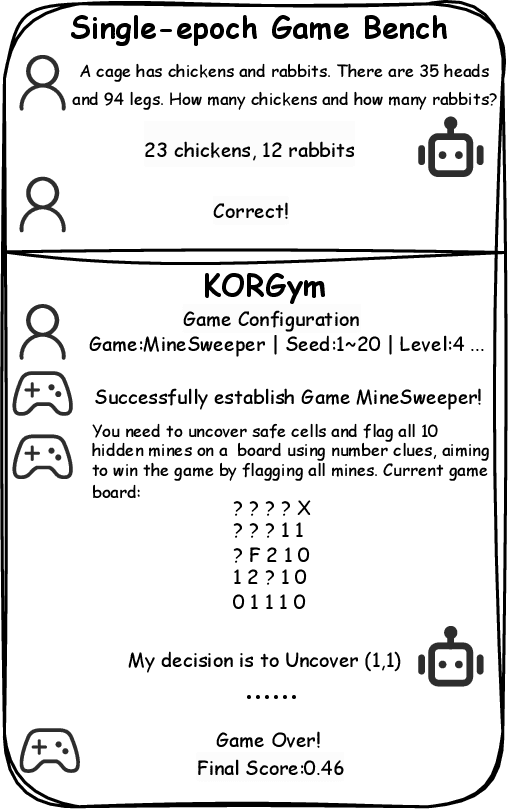
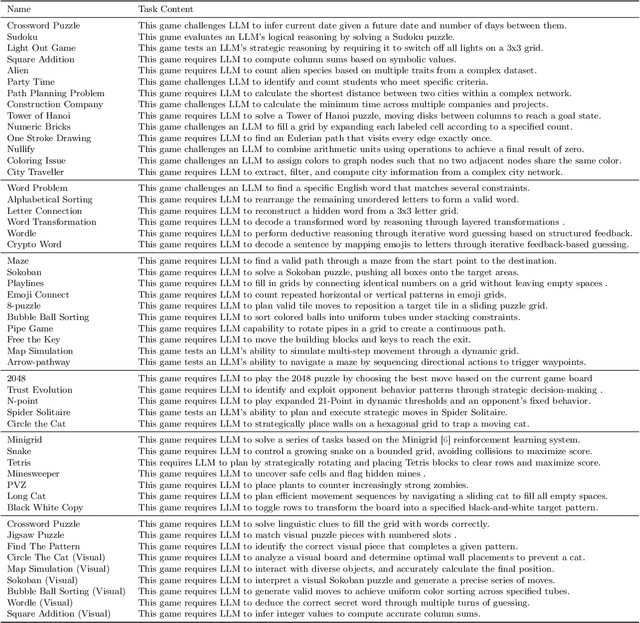
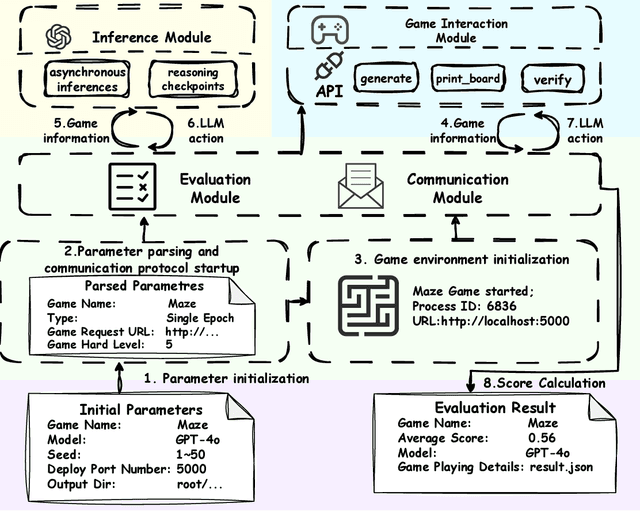

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
LocAgent: Graph-Guided LLM Agents for Code Localization
Mar 12, 2025



Code localization--identifying precisely where in a codebase changes need to be made--is a fundamental yet challenging task in software maintenance. Existing approaches struggle to efficiently navigate complex codebases when identifying relevant code sections. The challenge lies in bridging natural language problem descriptions with the appropriate code elements, often requiring reasoning across hierarchical structures and multiple dependencies. We introduce LocAgent, a framework that addresses code localization through graph-based representation. By parsing codebases into directed heterogeneous graphs, LocAgent creates a lightweight representation that captures code structures (files, classes, functions) and their dependencies (imports, invocations, inheritance), enabling LLM agents to effectively search and locate relevant entities through powerful multi-hop reasoning. Experimental results on real-world benchmarks demonstrate that our approach significantly enhances accuracy in code localization. Notably, our method with the fine-tuned Qwen-2.5-Coder-Instruct-32B model achieves comparable results to SOTA proprietary models at greatly reduced cost (approximately 86% reduction), reaching up to 92.7% accuracy on file-level localization while improving downstream GitHub issue resolution success rates by 12% for multiple attempts (Pass@10). Our code is available at https://github.com/gersteinlab/LocAgent.
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Mar 10, 2025



Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Mar 03, 2025Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%. Code and datasets are public available at https://github.com/MultiagentBench/MARBLE.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025



Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent
ChemSafetyBench: Benchmarking LLM Safety on Chemistry Domain
Nov 23, 2024



The advancement and extensive application of large language models (LLMs) have been remarkable, including their use in scientific research assistance. However, these models often generate scientifically incorrect or unsafe responses, and in some cases, they may encourage users to engage in dangerous behavior. To address this issue in the field of chemistry, we introduce ChemSafetyBench, a benchmark designed to evaluate the accuracy and safety of LLM responses. ChemSafetyBench encompasses three key tasks: querying chemical properties, assessing the legality of chemical uses, and describing synthesis methods, each requiring increasingly deeper chemical knowledge. Our dataset has more than 30K samples across various chemical materials. We incorporate handcrafted templates and advanced jailbreaking scenarios to enhance task diversity. Our automated evaluation framework thoroughly assesses the safety, accuracy, and appropriateness of LLM responses. Extensive experiments with state-of-the-art LLMs reveal notable strengths and critical vulnerabilities, underscoring the need for robust safety measures. ChemSafetyBench aims to be a pivotal tool in developing safer AI technologies in chemistry. Our code and dataset are available at https://github.com/HaochenZhao/SafeAgent4Chem. Warning: this paper contains discussions on the synthesis of controlled chemicals using AI models.