 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Action Reparameterization for Efficient Agent Inference
May 19, 2026Large language model (LLM) agents often rely on long sequences of low-level textual actions, resulting in large effective decision horizons and high inference cost. While prior work has focused on improving inference efficiency through system-level optimizations or prompt engineering, we argue that a key bottleneck lies in the representation of the action space itself. We propose Latent Action Reparameterization (LAR), a framework that learns a compact latent action space in which each latent action corresponds to a multi-step semantic behavior. By reparameterizing agent actions into latent units, LAR enables decision making over a shorter effective horizon while preserving the expressiveness of the original action space. Unlike hand-crafted macros or hierarchical controllers, latent actions are learned from agent trajectories and integrated directly into the model, allowing both planning and execution to operate over abstract action representations. Across a range of LLM-based agent benchmarks, LAR significantly reduces the effective action horizon and improves inference efficiency under fixed compute budgets. As a consequence, our approach achieves substantial reductions in action tokens and corresponding wall-clock inference time, while maintaining or improving task success rates. These results suggest that action representation learning is a critical and underexplored factor in scaling efficient LLM agent inference, complementary to advances in model architecture and hardware.
Scalable Environments Drive Generalizable Agents
May 18, 2026Generalizable agents should adapt to diverse tasks and unseen environments beyond their training distribution. This position paper argues that such generalization requires environment scaling: expanding the distribution of executable rule-sets that agents interact with, rather than only increasing trajectories or tasks within fixed benchmarks. Current scaling practices largely focus on collecting more experience or broader task sets under fixed interaction rules, leaving agents brittle when underlying interfaces, dynamics, observations, or feedback signals change. The core challenge is therefore a world-level distribution shift: agents need systematic exposure to environments with meaningfully different executable rule-sets. To clarify this challenge, we propose a unified taxonomy that separates trajectory scaling, task scaling, and environment scaling by their primary deliverables and by what changes in the executable rule-set. Building on this taxonomy, we synthesize construction paradigms for scalable environments, contrasting programmatic generators that prioritize controllability and verifiability with generative world models that offer broader coverage and open-endedness. We further outline how environment scaling can be coupled with stateful learning mechanisms, emphasizing learned update rules for cross-environment adaptation. We conclude by discussing alternative perspectives and argue that scalable environments provide the essential substrate for measurable and controllable progress toward robust general agents.
Harnessing Agentic Evolution
May 13, 2026Agentic evolution has emerged as a powerful paradigm for improving programs, workflows, and scientific solutions by iteratively generating candidates, evaluating them, and using feedback to guide future search. However, existing methods are typically instantiated either as fixed hand-designed procedures that are modular but rigid, or as general-purpose agents that flexibly integrate feedback but can drift in long-horizon evolution. Both forms accumulate rich evidence over time, including candidates, feedback, traces, and failures, yet lack a stable interface for organizing this evidence and revising the mechanism that drives future evolution. We address this limitation by formulating agentic evolution as an interactive environment, where the accumulated evolution context serves as a process-level state. We introduce AEvo, a harnessed meta-editing framework in which a meta-agent observes this state and acts not by directly proposing the next candidate, but by editing the procedure or agent context that controls future evolution. This unified interface enables AEvo to steer both procedure-based and agent-based evolution, making accumulated evidence actionable for long-horizon search. Empirical evaluations on agentic and reasoning benchmarks show that AEvo outperforms five evolution baselines, achieving a 26 relative improvement over the strongest baseline. Across three open-ended optimization tasks, AEvo further outperforms four evolution baselines and achieves state-of-the-art performance under the same iteration budget.
Co-Evolution of Policy and Internal Reward for Language Agents
Apr 03, 2026Large language model (LLM) agents learn by interacting with environments, but long-horizon training remains fundamentally bottlenecked by sparse and delayed rewards. Existing methods typically address this challenge through post-hoc credit assignment or external reward models, which provide limited guidance at inference time and often separate reward improvement from policy improvement. We propose Self-Guide, a self-generated internal reward for language agents that supports both inference-time guidance and training-time supervision. Specifically, the agent uses Self-Guide as a short self-guidance signal to steer the next action during inference, and converts the same signal into step-level internal reward for denser policy optimization during training. This creates a co-evolving loop: better policy produces better guidance, and better guidance further improves policy as internal reward. Across three agent benchmarks, inference-time self-guidance already yields clear gains, while jointly evolving policy and internal reward with GRPO brings further improvements (8\%) over baselines trained solely with environment reward. Overall, our results suggest that language agents can improve not only by collecting more experience, but also by learning to generate and refine their own internal reward during acting and learning.
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
InfoPO: Information-Driven Policy Optimization for User-Centric Agents
Feb 28, 2026Real-world user requests to LLM agents are often underspecified. Agents must interact to acquire missing information and make correct downstream decisions. However, current multi-turn GRPO-based methods often rely on trajectory-level reward computation, which leads to credit assignment problems and insufficient advantage signals within rollout groups. A feasible approach is to identify valuable interaction turns at a fine granularity to drive more targeted learning. To address this, we introduce InfoPO (Information-Driven Policy Optimization), which frames multi-turn interaction as a process of active uncertainty reduction and computes an information-gain reward that credits turns whose feedback measurably changes the agent's subsequent action distribution compared to a masked-feedback counterfactual. It then combines this signal with task outcomes via an adaptive variance-gated fusion to identify information importance while maintaining task-oriented goal direction. Across diverse tasks, including intent clarification, collaborative coding, and tool-augmented decision making, InfoPO consistently outperforms prompting and multi-turn RL baselines. It also demonstrates robustness under user simulator shifts and generalizes effectively to environment-interactive tasks. Overall, InfoPO provides a principled and scalable mechanism for optimizing complex agent-user collaboration. Code is available at https://github.com/kfq20/InfoPO.
AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
Feb 15, 2026The performance of autonomous Web GUI agents heavily relies on the quality and quantity of their training data. However, a fundamental bottleneck persists: collecting interaction trajectories from real-world websites is expensive and difficult to verify. The underlying state transitions are hidden, leading to reliance on inconsistent and costly external verifiers to evaluate step-level correctness. To address this, we propose AutoWebWorld, a novel framework for synthesizing controllable and verifiable web environments by modeling them as Finite State Machines (FSMs) and use coding agents to translate FSMs into interactive websites. Unlike real websites, where state transitions are implicit, AutoWebWorld explicitly defines all states, actions, and transition rules. This enables programmatic verification: action correctness is checked against predefined rules, and task success is confirmed by reaching a goal state in the FSM graph. AutoWebWorld enables a fully automated search-and-verify pipeline, generating over 11,663 verified trajectories from 29 diverse web environments at only $0.04 per trajectory. Training on this synthetic data significantly boosts real-world performance. Our 7B Web GUI agent outperforms all baselines within 15 steps on WebVoyager. Furthermore, we observe a clear scaling law: as the synthetic data volume increases, performance on WebVoyager and Online-Mind2Web consistently improves.
AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025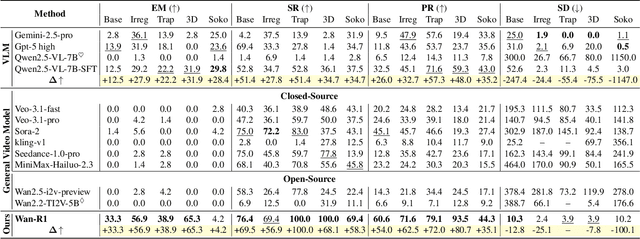

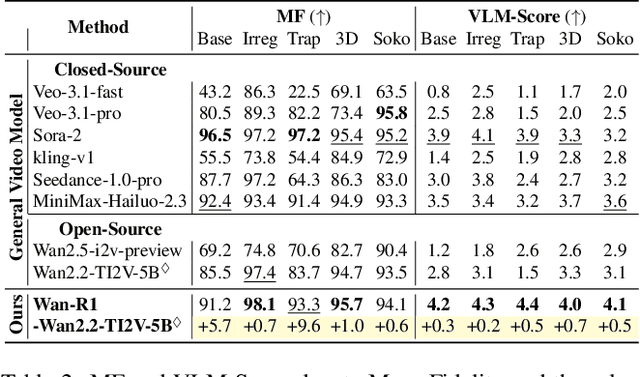
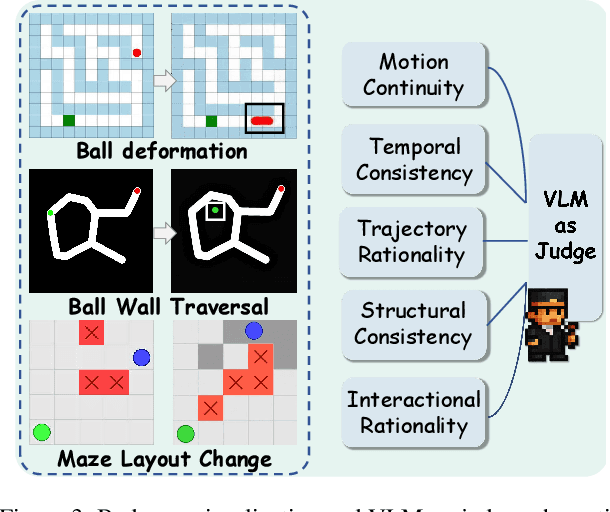
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
VisJudge-Bench: Aesthetics and Quality Assessment of Visualizations
Oct 25, 2025Visualization, a domain-specific yet widely used form of imagery, is an effective way to turn complex datasets into intuitive insights, and its value depends on whether data are faithfully represented, clearly communicated, and aesthetically designed. However, evaluating visualization quality is challenging: unlike natural images, it requires simultaneous judgment across data encoding accuracy, information expressiveness, and visual aesthetics. Although multimodal large language models (MLLMs) have shown promising performance in aesthetic assessment of natural images, no systematic benchmark exists for measuring their capabilities in evaluating visualizations. To address this, we propose VisJudge-Bench, the first comprehensive benchmark for evaluating MLLMs' performance in assessing visualization aesthetics and quality. It contains 3,090 expert-annotated samples from real-world scenarios, covering single visualizations, multiple visualizations, and dashboards across 32 chart types. Systematic testing on this benchmark reveals that even the most advanced MLLMs (such as GPT-5) still exhibit significant gaps compared to human experts in judgment, with a Mean Absolute Error (MAE) of 0.551 and a correlation with human ratings of only 0.429. To address this issue, we propose VisJudge, a model specifically designed for visualization aesthetics and quality assessment. Experimental results demonstrate that VisJudge significantly narrows the gap with human judgment, reducing the MAE to 0.442 (a 19.8% reduction) and increasing the consistency with human experts to 0.681 (a 58.7% improvement) compared to GPT-5. The benchmark is available at https://github.com/HKUSTDial/VisJudgeBench.