 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGNN: A Joint Semi-supervised Framework for Graph-level Classification
Apr 23, 2023This paper studies semi-supervised graph classification, a crucial task with a wide range of applications in social network analysis and bioinformatics. Recent works typically adopt graph neural networks to learn graph-level representations for classification, failing to explicitly leverage features derived from graph topology (e.g., paths). Moreover, when labeled data is scarce, these methods are far from satisfactory due to their insufficient topology exploration of unlabeled data. We address the challenge by proposing a novel semi-supervised framework called Twin Graph Neural Network (TGNN). To explore graph structural information from complementary views, our TGNN has a message passing module and a graph kernel module. To fully utilize unlabeled data, for each module, we calculate the similarity of each unlabeled graph to other labeled graphs in the memory bank and our consistency loss encourages consistency between two similarity distributions in different embedding spaces. The two twin modules collaborate with each other by exchanging instance similarity knowledge to fully explore the structure information of both labeled and unlabeled data. We evaluate our TGNN on various public datasets and show that it achieves strong performance.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023



Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
Class Is Invariant to Context and Vice Versa: On Learning Invariance for Out-Of-Distribution Generalization
Aug 06, 2022
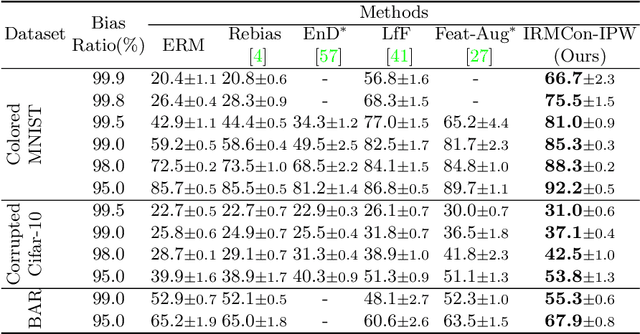
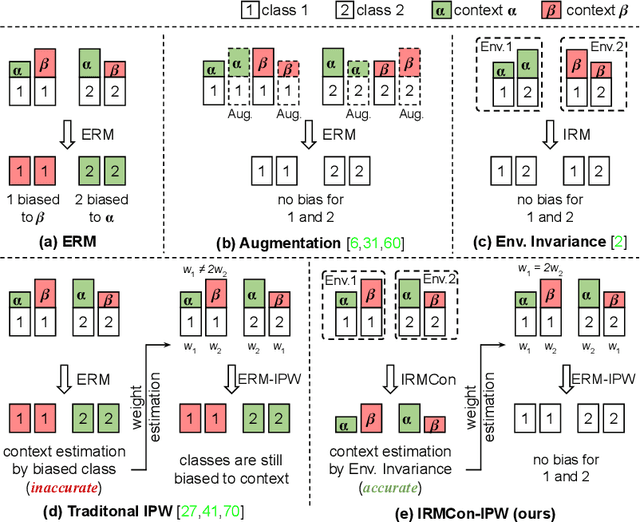
Out-Of-Distribution generalization (OOD) is all about learning invariance against environmental changes. If the context in every class is evenly distributed, OOD would be trivial because the context can be easily removed due to an underlying principle: class is invariant to context. However, collecting such a balanced dataset is impractical. Learning on imbalanced data makes the model bias to context and thus hurts OOD. Therefore, the key to OOD is context balance. We argue that the widely adopted assumption in prior work, the context bias can be directly annotated or estimated from biased class prediction, renders the context incomplete or even incorrect. In contrast, we point out the everoverlooked other side of the above principle: context is also invariant to class, which motivates us to consider the classes (which are already labeled) as the varying environments to resolve context bias (without context labels). We implement this idea by minimizing the contrastive loss of intra-class sample similarity while assuring this similarity to be invariant across all classes. On benchmarks with various context biases and domain gaps, we show that a simple re-weighting based classifier equipped with our context estimation achieves state-of-the-art performance. We provide the theoretical justifications in Appendix and codes on https://github.com/simpleshinobu/IRMCon.
Identifying Hard Noise in Long-Tailed Sample Distribution
Jul 27, 2022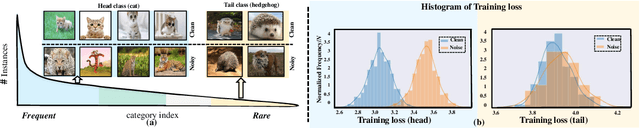

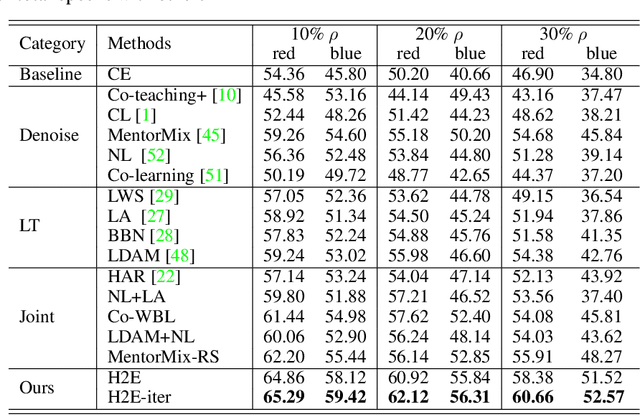
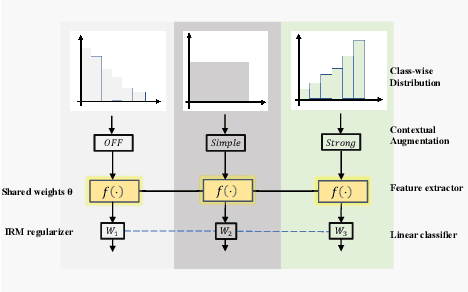
Conventional de-noising methods rely on the assumption that all samples are independent and identically distributed, so the resultant classifier, though disturbed by noise, can still easily identify the noises as the outliers of training distribution. However, the assumption is unrealistic in large-scale data that is inevitably long-tailed. Such imbalanced training data makes a classifier less discriminative for the tail classes, whose previously "easy" noises are now turned into "hard" ones -- they are almost as outliers as the clean tail samples. We introduce this new challenge as Noisy Long-Tailed Classification (NLT). Not surprisingly, we find that most de-noising methods fail to identify the hard noises, resulting in significant performance drop on the three proposed NLT benchmarks: ImageNet-NLT, Animal10-NLT, and Food101-NLT. To this end, we design an iterative noisy learning framework called Hard-to-Easy (H2E). Our bootstrapping philosophy is to first learn a classifier as noise identifier invariant to the class and context distributional changes, reducing "hard" noises to "easy" ones, whose removal further improves the invariance. Experimental results show that our H2E outperforms state-of-the-art de-noising methods and their ablations on long-tailed settings while maintaining a stable performance on the conventional balanced settings. Datasets and codes are available at https://github.com/yxymessi/H2E-Framework
Spatiotemporal Self-attention Modeling with Temporal Patch Shift for Action Recognition
Jul 27, 2022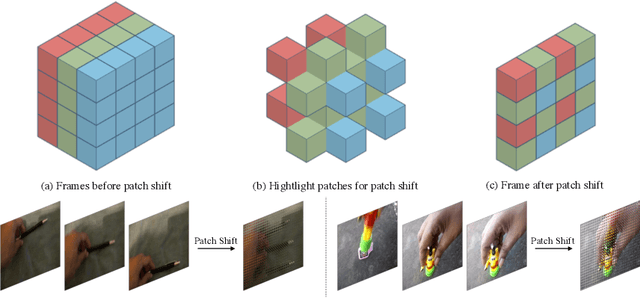
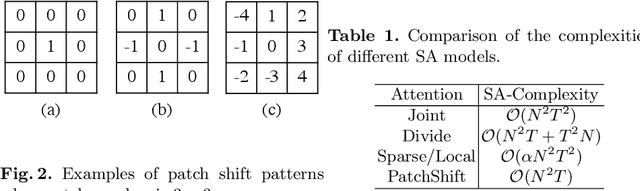
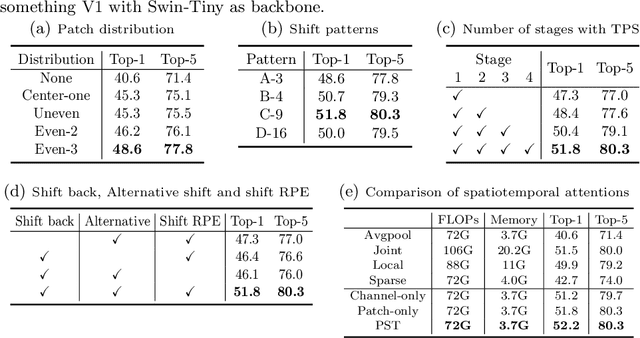

Transformer-based methods have recently achieved great advancement on 2D image-based vision tasks. For 3D video-based tasks such as action recognition, however, directly applying spatiotemporal transformers on video data will bring heavy computation and memory burdens due to the largely increased number of patches and the quadratic complexity of self-attention computation. How to efficiently and effectively model the 3D self-attention of video data has been a great challenge for transformers. In this paper, we propose a Temporal Patch Shift (TPS) method for efficient 3D self-attention modeling in transformers for video-based action recognition. TPS shifts part of patches with a specific mosaic pattern in the temporal dimension, thus converting a vanilla spatial self-attention operation to a spatiotemporal one with little additional cost. As a result, we can compute 3D self-attention using nearly the same computation and memory cost as 2D self-attention. TPS is a plug-and-play module and can be inserted into existing 2D transformer models to enhance spatiotemporal feature learning. The proposed method achieves competitive performance with state-of-the-arts on Something-something V1 & V2, Diving-48, and Kinetics400 while being much more efficient on computation and memory cost. The source code of TPS can be found at https://github.com/MartinXM/TPS.
Rethinking IoU-based Optimization for Single-stage 3D Object Detection
Jul 20, 2022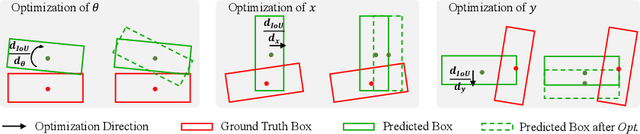
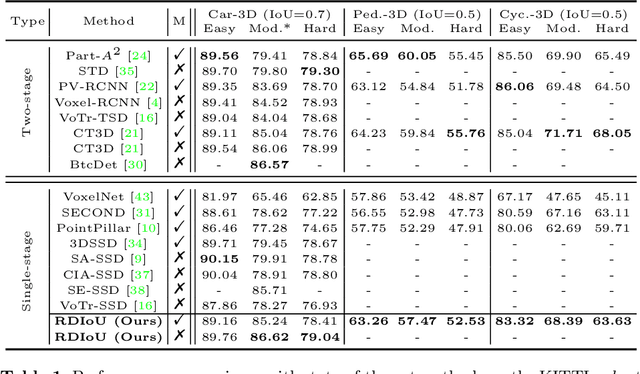
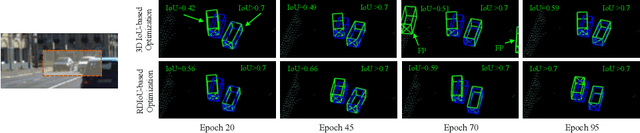
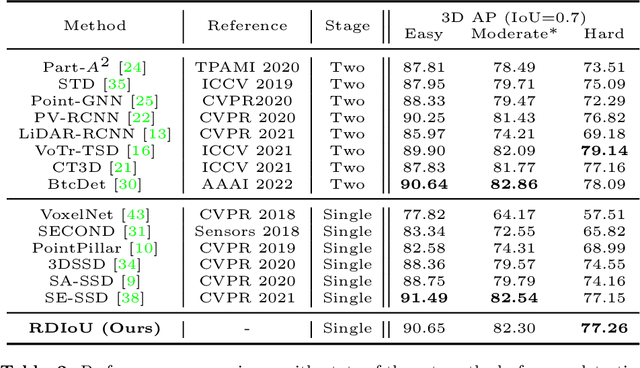
Since Intersection-over-Union (IoU) based optimization maintains the consistency of the final IoU prediction metric and losses, it has been widely used in both regression and classification branches of single-stage 2D object detectors. Recently, several 3D object detection methods adopt IoU-based optimization and directly replace the 2D IoU with 3D IoU. However, such a direct computation in 3D is very costly due to the complex implementation and inefficient backward operations. Moreover, 3D IoU-based optimization is sub-optimal as it is sensitive to rotation and thus can cause training instability and detection performance deterioration. In this paper, we propose a novel Rotation-Decoupled IoU (RDIoU) method that can mitigate the rotation-sensitivity issue, and produce more efficient optimization objectives compared with 3D IoU during the training stage. Specifically, our RDIoU simplifies the complex interactions of regression parameters by decoupling the rotation variable as an independent term, yet preserving the geometry of 3D IoU. By incorporating RDIoU into both the regression and classification branches, the network is encouraged to learn more precise bounding boxes and concurrently overcome the misalignment issue between classification and regression. Extensive experiments on the benchmark KITTI and Waymo Open Dataset validate that our RDIoU method can bring substantial improvement for the single-stage 3D object detection.
Towards Counterfactual Image Manipulation via CLIP
Jul 12, 2022
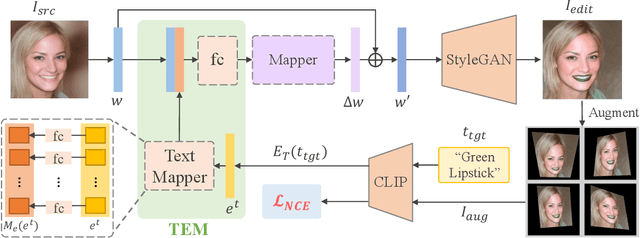
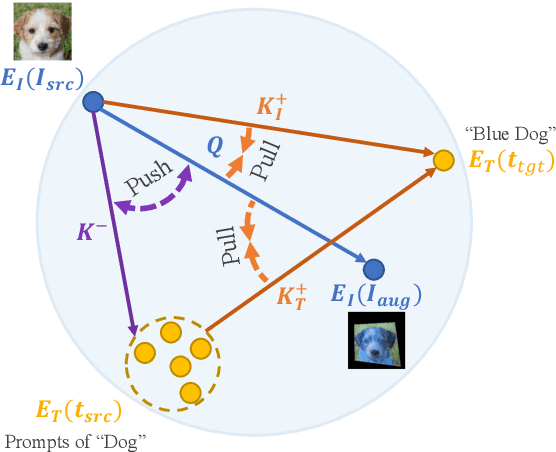

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
On Non-Random Missing Labels in Semi-Supervised Learning
Jun 29, 2022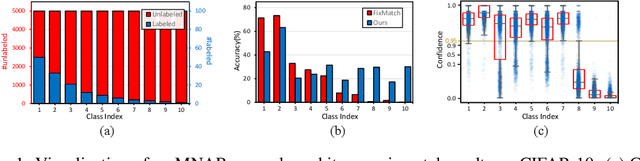
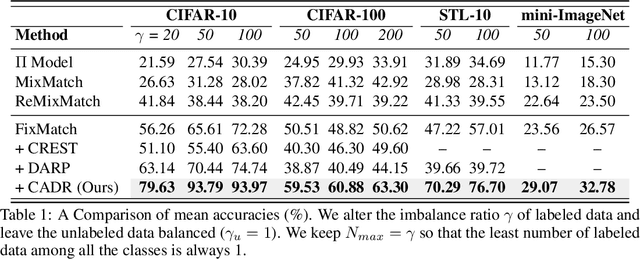
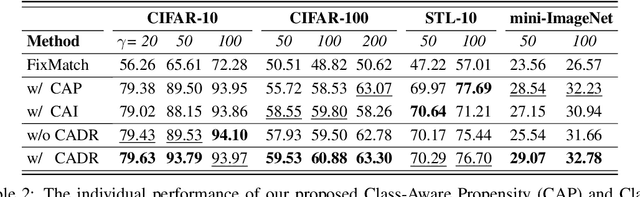
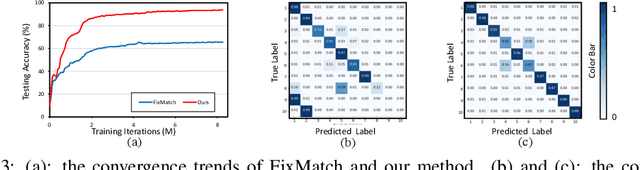
Semi-Supervised Learning (SSL) is fundamentally a missing label problem, in which the label Missing Not At Random (MNAR) problem is more realistic and challenging, compared to the widely-adopted yet naive Missing Completely At Random assumption where both labeled and unlabeled data share the same class distribution. Different from existing SSL solutions that overlook the role of "class" in causing the non-randomness, e.g., users are more likely to label popular classes, we explicitly incorporate "class" into SSL. Our method is three-fold: 1) We propose Class-Aware Propensity (CAP) that exploits the unlabeled data to train an improved classifier using the biased labeled data. 2) To encourage rare class training, whose model is low-recall but high-precision that discards too many pseudo-labeled data, we propose Class-Aware Imputation (CAI) that dynamically decreases (or increases) the pseudo-label assignment threshold for rare (or frequent) classes. 3) Overall, we integrate CAP and CAI into a Class-Aware Doubly Robust (CADR) estimator for training an unbiased SSL model. Under various MNAR settings and ablations, our method not only significantly outperforms existing baselines but also surpasses other label bias removal SSL methods. Please check our code at: https://github.com/JoyHuYY1412/CADR-FixMatch.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Dense Learning based Semi-Supervised Object Detection
Apr 15, 2022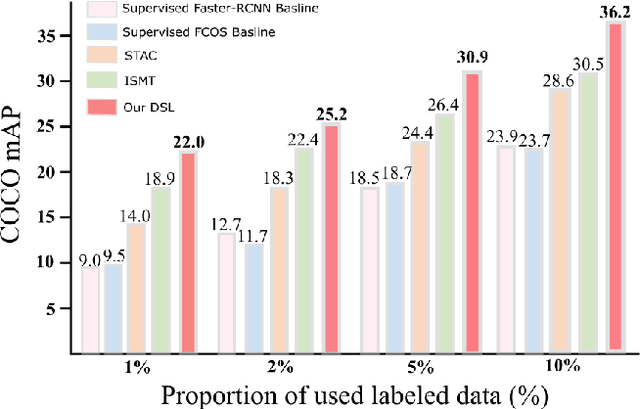
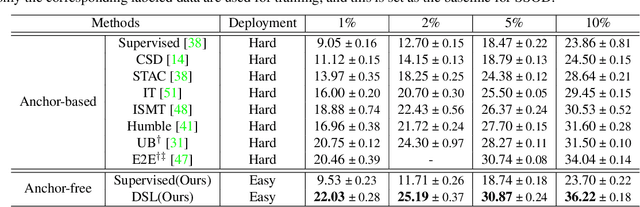
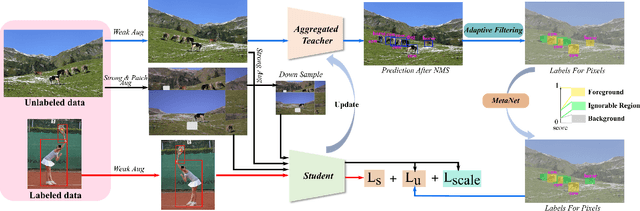
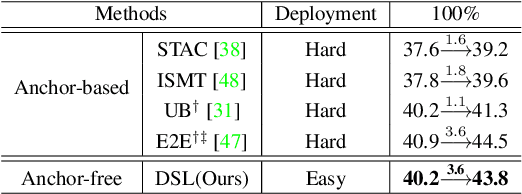
Semi-supervised object detection (SSOD) aims to facilitate the training and deployment of object detectors with the help of a large amount of unlabeled data. Though various self-training based and consistency-regularization based SSOD methods have been proposed, most of them are anchor-based detectors, ignoring the fact that in many real-world applications anchor-free detectors are more demanded. In this paper, we intend to bridge this gap and propose a DenSe Learning (DSL) based anchor-free SSOD algorithm. Specifically, we achieve this goal by introducing several novel techniques, including an Adaptive Filtering strategy for assigning multi-level and accurate dense pixel-wise pseudo-labels, an Aggregated Teacher for producing stable and precise pseudo-labels, and an uncertainty-consistency-regularization term among scales and shuffled patches for improving the generalization capability of the detector. Extensive experiments are conducted on MS-COCO and PASCAL-VOC, and the results show that our proposed DSL method records new state-of-the-art SSOD performance, surpassing existing methods by a large margin. Codes can be found at \textcolor{blue}{https://github.com/chenbinghui1/DSL}.