 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Elevating Medical Reasoning from Statistical Consensus to Process-Led Alignment
Mar 09, 2026Recent advances in medical large language models have explored Test-Time Reinforcement Learning (TTRL) to enhance reasoning. However, standard TTRL often relies on majority voting (MV) as a heuristic supervision signal, which can be unreliable in complex medical scenarios where the most frequent reasoning path is not necessarily the clinically correct one. In this work, we propose a novel and unified training paradigm that integrates medical process reward models with TTRL to bridge the gap between test-time scaling (TTS) and parametric model optimization. Specifically, we advance the TTRL framework by replacing the conventional MV with a fine-grained, expert-aligned supervision paradigm using Med-RPM. This integration ensures that reinforcement learning is guided by medical correctness rather than mere consensus, effectively distilling search-based intelligence into the model's parametric memory. Extensive evaluations on four different benchmarks have demonstrated that our developed method consistently and significantly outperforms current TTRL and standalone PRM selection. Our findings establish that transitioning from stochastic heuristics to structured, step-wise rewards is essential for developing reliable and scalable medical AI systems
Learning Neural Operators from Partial Observations via Latent Autoregressive Modeling
Jan 27, 2026Real-world scientific applications frequently encounter incomplete observational data due to sensor limitations, geographic constraints, or measurement costs. Although neural operators significantly advanced PDE solving in terms of computational efficiency and accuracy, their underlying assumption of fully-observed spatial inputs severely restricts applicability in real-world applications. We introduce the first systematic framework for learning neural operators from partial observation. We identify and formalize two fundamental obstacles: (i) the supervision gap in unobserved regions that prevents effective learning of physical correlations, and (ii) the dynamic spatial mismatch between incomplete inputs and complete solution fields. Specifically, our proposed Latent Autoregressive Neural Operator(LANO) introduces two novel components designed explicitly to address the core difficulties of partial observations: (i) a mask-to-predict training strategy that creates artificial supervision by strategically masking observed regions, and (ii) a Physics-Aware Latent Propagator that reconstructs solutions through boundary-first autoregressive generation in latent space. Additionally, we develop POBench-PDE, a dedicated and comprehensive benchmark designed specifically for evaluating neural operators under partial observation conditions across three PDE-governed tasks. LANO achieves state-of-the-art performance with 18--69$\%$ relative L2 error reduction across all benchmarks under patch-wise missingness with less than 50$\%$ missing rate, including real-world climate prediction. Our approach effectively addresses practical scenarios involving up to 75$\%$ missing rate, to some extent bridging the existing gap between idealized research settings and the complexities of real-world scientific computing.
ALL-PET: A Low-resource and Low-shot PET Foundation Model in the Projection Domain
Sep 11, 2025



Building large-scale foundation model for PET imaging is hindered by limited access to labeled data and insufficient computational resources. To overcome data scarcity and efficiency limitations, we propose ALL-PET, a low-resource, low-shot PET foundation model operating directly in the projection domain. ALL-PET leverages a latent diffusion model (LDM) with three key innovations. First, we design a Radon mask augmentation strategy (RMAS) that generates over 200,000 structurally diverse training samples by projecting randomized image-domain masks into sinogram space, significantly improving generalization with minimal data. This is extended by a dynamic multi-mask (DMM) mechanism that varies mask quantity and distribution, enhancing data diversity without added model complexity. Second, we implement positive/negative mask constraints to embed strict geometric consistency, reducing parameter burden while preserving generation quality. Third, we introduce transparent medical attention (TMA), a parameter-free, geometry-driven mechanism that enhances lesion-related regions in raw projection data. Lesion-focused attention maps are derived from coarse segmentation, covering both hypermetabolic and hypometabolic areas, and projected into sinogram space for physically consistent guidance. The system supports clinician-defined ROI adjustments, ensuring flexible, interpretable, and task-adaptive emphasis aligned with PET acquisition physics. Experimental results show ALL-PET achieves high-quality sinogram generation using only 500 samples, with performance comparable to models trained on larger datasets. ALL-PET generalizes across tasks including low-dose reconstruction, attenuation correction, delayed-frame prediction, and tracer separation, operating efficiently with memory use under 24GB.
MIMOSA: Multi-parametric Imaging using Multiple-echoes with Optimized Simultaneous Acquisition for highly-efficient quantitative MRI
Aug 13, 2025



Purpose: To develop a new sequence, MIMOSA, for highly-efficient T1, T2, T2*, proton density (PD), and source separation quantitative susceptibility mapping (QSM). Methods: MIMOSA was developed based on 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) by combining 3D turbo Fast Low Angle Shot (FLASH) and multi-echo gradient echo acquisition modules with a spiral-like Cartesian trajectory to facilitate highly-efficient acquisition. Simulations were performed to optimize the sequence. Multi-contrast/-slice zero-shot self-supervised learning algorithm was employed for reconstruction. The accuracy of quantitative mapping was assessed by comparing MIMOSA with 3D-QALAS and reference techniques in both ISMRM/NIST phantom and in-vivo experiments. MIMOSA's acceleration capability was assessed at R = 3.3, 6.5, and 11.8 in in-vivo experiments, with repeatability assessed through scan-rescan studies. Beyond the 3T experiments, mesoscale quantitative mapping was performed at 750 um isotropic resolution at 7T. Results: Simulations demonstrated that MIMOSA achieved improved parameter estimation accuracy compared to 3D-QALAS. Phantom experiments indicated that MIMOSA exhibited better agreement with the reference techniques than 3D-QALAS. In-vivo experiments demonstrated that an acceleration factor of up to R = 11.8-fold can be achieved while preserving parameter estimation accuracy, with intra-class correlation coefficients of 0.998 (T1), 0.973 (T2), 0.947 (T2*), 0.992 (QSM), 0.987 (paramagnetic susceptibility), and 0.977 (diamagnetic susceptibility) in scan-rescan studies. Whole-brain T1, T2, T2*, PD, source separation QSM were obtained with 1 mm isotropic resolution in 3 min at 3T and 750 um isotropic resolution in 13 min at 7T. Conclusion: MIMOSA demonstrated potential for highly-efficient multi-parametric mapping.
Predicting ICU In-Hospital Mortality Using Adaptive Transformer Layer Fusion
Jun 06, 2025



Early identification of high-risk ICU patients is crucial for directing limited medical resources. We introduce ALFIA (Adaptive Layer Fusion with Intelligent Attention), a modular, attention-based architecture that jointly trains LoRA (Low-Rank Adaptation) adapters and an adaptive layer-weighting mechanism to fuse multi-layer semantic features from a BERT backbone. Trained on our rigorous cw-24 (CriticalWindow-24) benchmark, ALFIA surpasses state-of-the-art tabular classifiers in AUPRC while preserving a balanced precision-recall profile. The embeddings produced by ALFIA's fusion module, capturing both fine-grained clinical cues and high-level concepts, enable seamless pairing with GBDTs (CatBoost/LightGBM) as ALFIA-boost, and deep neuro networks as ALFIA-nn, yielding additional performance gains. Our experiments confirm ALFIA's superior early-warning performance, by operating directly on routine clinical text, it furnishes clinicians with a convenient yet robust tool for risk stratification and timely intervention in critical-care settings.
Dynamic PET Image Prediction Using a Network Combining Reversible and Irreversible Modules
Oct 30, 2024



Dynamic positron emission tomography (PET) images can reveal the distribution of tracers in the organism and the dynamic processes involved in biochemical reactions, and it is widely used in clinical practice. Despite the high effectiveness of dynamic PET imaging in studying the kinetics and metabolic processes of radiotracers. Pro-longed scan times can cause discomfort for both patients and medical personnel. This study proposes a dynamic frame prediction method for dynamic PET imaging, reduc-ing dynamic PET scanning time by applying a multi-module deep learning framework composed of reversible and irreversible modules. The network can predict kinetic parameter images based on the early frames of dynamic PET images, and then generate complete dynamic PET images. In validation experiments with simulated data, our network demonstrated good predictive performance for kinetic parameters and was able to reconstruct high-quality dynamic PET images. Additionally, in clinical data experiments, the network exhibited good generalization performance and attached that the proposed method has promising clinical application prospects.
FashionR2R: Texture-preserving Rendered-to-Real Image Translation with Diffusion Models
Oct 18, 2024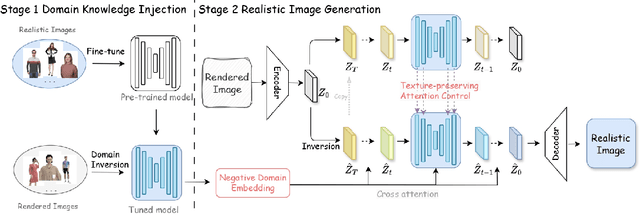
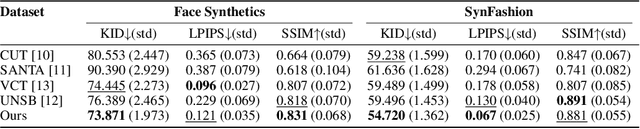
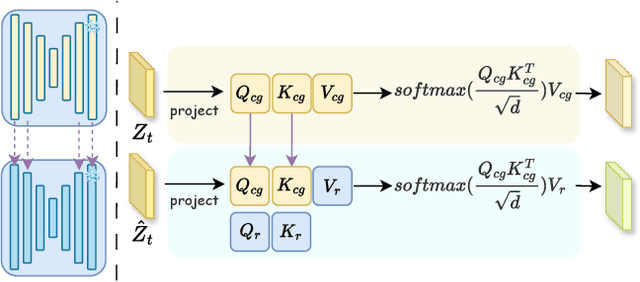
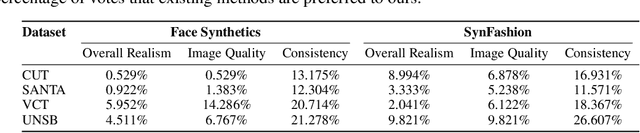
Modeling and producing lifelike clothed human images has attracted researchers' attention from different areas for decades, with the complexity from highly articulated and structured content. Rendering algorithms decompose and simulate the imaging process of a camera, while are limited by the accuracy of modeled variables and the efficiency of computation. Generative models can produce impressively vivid human images, however still lacking in controllability and editability. This paper studies photorealism enhancement of rendered images, leveraging generative power from diffusion models on the controlled basis of rendering. We introduce a novel framework to translate rendered images into their realistic counterparts, which consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, we adopt positive (real) domain finetuning and negative (rendered) domain embedding to inject knowledge into a pretrained Text-to-image (T2I) diffusion model. In RIG, we generate the realistic image corresponding to the input rendered image, with a Texture-preserving Attention Control (TAC) to preserve fine-grained clothing textures, exploiting the decoupled features encoded in the UNet structure. Additionally, we introduce SynFashion dataset, featuring high-quality digital clothing images with diverse textures. Extensive experimental results demonstrate the superiority and effectiveness of our method in rendered-to-real image translation.
Deep unrolled primal dual network for TOF-PET list-mode image reconstruction
Oct 15, 2024



Time-of-flight (TOF) information provides more accurate location data for annihilation photons, thereby enhancing the quality of PET reconstruction images and reducing noise. List-mode reconstruction has a significant advantage in handling TOF information. However, current advanced TOF PET list-mode reconstruction algorithms still require improvements when dealing with low-count data. Deep learning algorithms have shown promising results in PET image reconstruction. Nevertheless, the incorporation of TOF information poses significant challenges related to the storage space required by deep learning methods, particularly for the advanced deep unrolled methods. In this study, we propose a deep unrolled primal dual network for TOF-PET list-mode reconstruction. The network is unrolled into multiple phases, with each phase comprising a dual network for list-mode domain updates and a primal network for image domain updates. We utilize CUDA for parallel acceleration and computation of the system matrix for TOF list-mode data, and we adopt a dynamic access strategy to mitigate memory consumption. Reconstructed images of different TOF resolutions and different count levels show that the proposed method outperforms the LM-OSEM, LM-EMTV, LM-SPDHG,LM-SPDHG-TV and FastPET method in both visually and quantitative analysis. These results demonstrate the potential application of deep unrolled methods for TOF-PET list-mode data and show better performance than current mainstream TOF-PET list-mode reconstruction algorithms, providing new insights for the application of deep learning methods in TOF list-mode data. The codes for this work are available at https://github.com/RickHH/LMPDnet
Unsupervised Learning of Hybrid Latent Dynamics: A Learn-to-Identify Framework
Mar 13, 2024



Modern applications increasingly require unsupervised learning of latent dynamics from high-dimensional time-series. This presents a significant challenge of identifiability: many abstract latent representations may reconstruct observations, yet do they guarantee an adequate identification of the governing dynamics? This paper investigates this challenge from two angles: the use of physics inductive bias specific to the data being modeled, and a learn-to-identify strategy that separates forecasting objectives from the data used for the identification. We combine these two strategies in a novel framework for unsupervised meta-learning of hybrid latent dynamics (Meta-HyLaD) with: 1) a latent dynamic function that hybridize known mathematical expressions of prior physics with neural functions describing its unknown errors, and 2) a meta-learning formulation to learn to separately identify both components of the hybrid dynamics. Through extensive experiments on five physics and one biomedical systems, we provide strong evidence for the benefits of Meta-HyLaD to integrate rich prior knowledge while identifying their gap to observed data.
Hybrid Kinetics Embedding Framework for Dynamic PET Reconstruction
Mar 12, 2024In dynamic positron emission tomography (PET) reconstruction, the importance of leveraging the temporal dependence of the data has been well appreciated. Current deep-learning solutions can be categorized in two groups in the way the temporal dynamics is modeled: data-driven approaches use spatiotemporal neural networks to learn the temporal dynamics of tracer kinetics from data, which relies heavily on data supervision; physics-based approaches leverage \textit{a priori} tracer kinetic models to focus on inferring their parameters, which relies heavily on the accuracy of the prior kinetic model. In this paper, we marry the strengths of these two approaches in a hybrid kinetics embedding (HyKE-Net) framework for dynamic PET reconstruction. We first introduce a novel \textit{hybrid} model of tracer kinetics consisting of a physics-based function augmented by a neural component to account for its gap to data-generating tracer kinetics, both identifiable from data. We then embed this hybrid model at the latent space of an encoding-decoding framework to enable both supervised and unsupervised identification of the hybrid kinetics and thereby dynamic PET reconstruction. Through both phantom and real-data experiments, we demonstrate the benefits of HyKE-Net -- especially in unsupervised reconstructions -- over existing physics-based and data-driven baselines as well as its ablated formulations where the embedded tracer kinetics are purely physics-based, purely neural, or hybrid but with a non-adaptable neural component.