 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025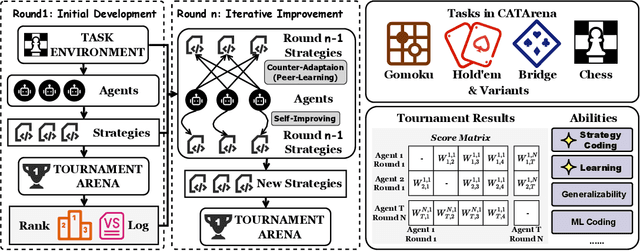
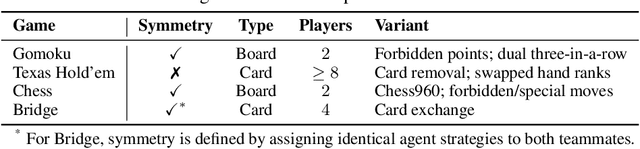
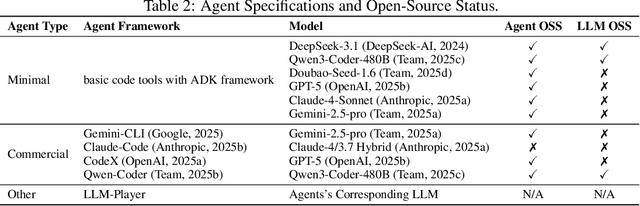
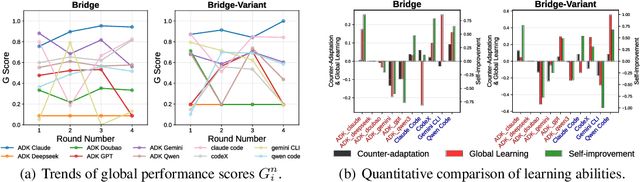
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
ColorEcosystem: Powering Personalized, Standardized, and Trustworthy Agentic Service in massive-agent Ecosystem
Oct 27, 2025With the rapid development of (multimodal) large language model-based agents, the landscape of agentic service management has evolved from single-agent systems to multi-agent systems, and now to massive-agent ecosystems. Current massive-agent ecosystems face growing challenges, including impersonal service experiences, a lack of standardization, and untrustworthy behavior. To address these issues, we propose ColorEcosystem, a novel blueprint designed to enable personalized, standardized, and trustworthy agentic service at scale. Concretely, ColorEcosystem consists of three key components: agent carrier, agent store, and agent audit. The agent carrier provides personalized service experiences by utilizing user-specific data and creating a digital twin, while the agent store serves as a centralized, standardized platform for managing diverse agentic services. The agent audit, based on the supervision of developer and user activities, ensures the integrity and credibility of both service providers and users. Through the analysis of challenges, transitional forms, and practical considerations, the ColorEcosystem is poised to power personalized, standardized, and trustworthy agentic service across massive-agent ecosystems. Meanwhile, we have also implemented part of ColorEcosystem's functionality, and the relevant code is open-sourced at https://github.com/opas-lab/color-ecosystem.
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
Sep 09, 2025With the rapid progress of multimodal large language models, operating system (OS) agents become increasingly capable of automating tasks through on-device graphical user interfaces (GUIs). However, most existing OS agents are designed for idealized settings, whereas real-world environments often present untrustworthy conditions. To mitigate risks of over-execution in such scenarios, we propose a query-driven human-agent-GUI interaction framework that enables OS agents to decide when to query humans for more reliable task completion. Built upon this framework, we introduce VeriOS-Agent, a trustworthy OS agent trained with a two-stage learning paradigm that falicitate the decoupling and utilization of meta-knowledge. Concretely, VeriOS-Agent autonomously executes actions in normal conditions while proactively querying humans in untrustworthy scenarios. Experiments show that VeriOS-Agent improves the average step-wise success rate by 20.64\% in untrustworthy scenarios over the state-of-the-art, without compromising normal performance. Analysis highlights VeriOS-Agent's rationality, generalizability, and scalability. The codes, datasets and models are available at https://github.com/Wuzheng02/VeriOS.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.
Quick on the Uptake: Eliciting Implicit Intents from Human Demonstrations for Personalized Mobile-Use Agents
Aug 12, 2025



As multimodal large language models advance rapidly, the automation of mobile tasks has become increasingly feasible through the use of mobile-use agents that mimic human interactions from graphical user interface. To further enhance mobile-use agents, previous studies employ demonstration learning to improve mobile-use agents from human demonstrations. However, these methods focus solely on the explicit intention flows of humans (e.g., step sequences) while neglecting implicit intention flows (e.g., personal preferences), which makes it difficult to construct personalized mobile-use agents. In this work, to evaluate the \textbf{I}ntention \textbf{A}lignment \textbf{R}ate between mobile-use agents and humans, we first collect \textbf{MobileIAR}, a dataset containing human-intent-aligned actions and ground-truth actions. This enables a comprehensive assessment of the agents' understanding of human intent. Then we propose \textbf{IFRAgent}, a framework built upon \textbf{I}ntention \textbf{F}low \textbf{R}ecognition from human demonstrations. IFRAgent analyzes explicit intention flows from human demonstrations to construct a query-level vector library of standard operating procedures (SOP), and analyzes implicit intention flows to build a user-level habit repository. IFRAgent then leverages a SOP extractor combined with retrieval-augmented generation and a query rewriter to generate personalized query and SOP from a raw ambiguous query, enhancing the alignment between mobile-use agents and human intent. Experimental results demonstrate that IFRAgent outperforms baselines by an average of 6.79\% (32.06\% relative improvement) in human intention alignment rate and improves step completion rates by an average of 5.30\% (26.34\% relative improvement). The codes are available at https://github.com/MadeAgents/Quick-on-the-Uptake.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.
Superplatforms Have to Attack AI Agents
May 23, 2025Over the past decades, superplatforms, digital companies that integrate a vast range of third-party services and applications into a single, unified ecosystem, have built their fortunes on monopolizing user attention through targeted advertising and algorithmic content curation. Yet the emergence of AI agents driven by large language models (LLMs) threatens to upend this business model. Agents can not only free user attention with autonomy across diverse platforms and therefore bypass the user-attention-based monetization, but might also become the new entrance for digital traffic. Hence, we argue that superplatforms have to attack AI agents to defend their centralized control of digital traffic entrance. Specifically, we analyze the fundamental conflict between user-attention-based monetization and agent-driven autonomy through the lens of our gatekeeping theory. We show how AI agents can disintermediate superplatforms and potentially become the next dominant gatekeepers, thereby forming the urgent necessity for superplatforms to proactively constrain and attack AI agents. Moreover, we go through the potential technologies for superplatform-initiated attacks, covering a brand-new, unexplored technical area with unique challenges. We have to emphasize that, despite our position, this paper does not advocate for adversarial attacks by superplatforms on AI agents, but rather offers an envisioned trend to highlight the emerging tensions between superplatforms and AI agents. Our aim is to raise awareness and encourage critical discussion for collaborative solutions, prioritizing user interests and perserving the openness of digital ecosystems in the age of AI agents.
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
May 23, 2025Mathematical reasoning through Chain-of-Thought (CoT) has emerged as a powerful capability of Large Language Models (LLMs), which can be further enhanced through Test-Time Scaling (TTS) methods like Beam Search and DVTS. However, these methods, despite improving accuracy by allocating more computational resources during inference, often suffer from path homogenization and inefficient use of intermediate results. To address these limitations, we propose Stepwise Reasoning Checkpoint Analysis (SRCA), a framework that introduces checkpoints between reasoning steps. It incorporates two key strategies: (1) Answer-Clustered Search, which groups reasoning paths by their intermediate checkpoint answers to maintain diversity while ensuring quality, and (2) Checkpoint Candidate Augmentation, which leverages all intermediate answers for final decision-making. Our approach effectively reduces path homogenization and creates a fault-tolerant mechanism by utilizing high-quality intermediate results. Experimental results show that SRCA improves reasoning accuracy compared to existing TTS methods across various mathematical datasets.
InfoDeepSeek: Benchmarking Agentic Information Seeking for Retrieval-Augmented Generation
May 21, 2025Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by grounding responses with retrieved information. As an emerging paradigm, Agentic RAG further enhances this process by introducing autonomous LLM agents into the information seeking process. However, existing benchmarks fall short in evaluating such systems, as they are confined to a static retrieval environment with a fixed, limited corpus} and simple queries that fail to elicit agentic behavior. Moreover, their evaluation protocols assess information seeking effectiveness by pre-defined gold sets of documents, making them unsuitable for the open-ended and dynamic nature of real-world web environments. To bridge this gap, we present InfoDeepSeek, a new benchmark with challenging questions designed for assessing agentic information seeking in real-world, dynamic web environments. We propose a systematic methodology for constructing challenging queries satisfying the criteria of determinacy, difficulty, and diversity. Based on this, we develop the first evaluation framework tailored to dynamic agentic information seeking, including fine-grained metrics about the accuracy, utility, and compactness of information seeking outcomes. Through extensive experiments across LLMs, search engines, and question types, InfoDeepSeek reveals nuanced agent behaviors and offers actionable insights for future research.
NL-Debugging: Exploiting Natural Language as an Intermediate Representation for Code Debugging
May 21, 2025Debugging is a critical aspect of LLM's coding ability. Early debugging efforts primarily focused on code-level analysis, which often falls short when addressing complex programming errors that require a deeper understanding of algorithmic logic. Recent advancements in large language models (LLMs) have shifted attention toward leveraging natural language reasoning to enhance code-related tasks. However, two fundamental questions remain unanswered: What type of natural language format is most effective for debugging tasks? And what specific benefits does natural language reasoning bring to the debugging process? In this paper, we introduce NL-DEBUGGING, a novel framework that employs natural language as an intermediate representation to improve code debugging. By debugging at a natural language level, we demonstrate that NL-DEBUGGING outperforms traditional debugging methods and enables a broader modification space through direct refinement guided by execution feedback. Our findings highlight the potential of natural language reasoning to advance automated code debugging and address complex programming challenges.