 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDailyReport: An Open-ended Benchmark for Evaluating Search Agents on Daily Search Tasks
Jun 11, 2026Search Agents (SAs) typically leverage large language models (LLMs) to support complex information-seeking tasks by autonomously exploring web sources and synthesizing information into comprehensive responses. For SAs evaluation, prior benchmarks mainly focus on specialized tasks that are unlikely to arise in real-world user scenarios. Moreover, their reliance on coarse task-level rubrics often limits evaluation interpretability. To bridge this gap, we introduce DailyReport, an open-ended benchmark to evaluate SA capabilities on daily search tasks. It contains 150 open-ended tasks with 3,546 associated rubrics, capturing widely discussed and timely information demands of real-world users. Each task is decomposed into subtasks and evaluated with cascade rubrics across disentangled dimensions. Through cascade performance attribution and user-centric aggregation, we derive highly interpretable scores for each dimension, along with a user preference score. Our results on 17 agentic systems show that current systems still fall short of users' expectations. To facilitate future research, our dataset and code are made publicly available at https://github.com/AGI-Eval-Official/DailyReport.
Asuka-Bench: Benchmarking Code Agents on Underspecified User Intent and Multi-Round Refinement
Jun 04, 2026Existing code-generation benchmarks score a single mapping from a complete prompt to a one-shot output. However, real web development is different. Users seldom write a full spec at the start; many requirements only become clear once they look at an intermediate result and react to it. We present Asuka-Bench, a benchmark that pairs underspecified user intent with multi-round refinement, grounded in browser-rendered behavior. Each task is resolved through a closed loop: a Code Agent generates a web project, a UI Agent executes test cases on the deployed site, and a User LLM turns evaluation outcomes into natural-language feedback for the next round. The benchmark comprises 50 web tasks with 784 evaluation criteria and 2402 expected outcomes. We benchmark 8 LLMs across 2 agent frameworks. The results separate models clearly: weighted Task Pass Rate varies by 38 percentage points and models also differ substantially in their ability to repair from feedback. Asuka-Bench is also far from saturated: even the strongest model completes only 52% of projects after three rounds.
SAGE: A Quantitative Evaluation of Socialized Evolution in Agent Ecosystems
Jun 02, 2026Self-improving language agents are typically evaluated in isolation: an agent attempts a task, receives feedback, and iteratively refines its own behavior. Yet agents increasingly operate alongside peers whose strategies and outcomes are publicly visible. This raises an under-studied question: when does shared experience produce improvements that self-improvement alone cannot achieve? We introduce SAGE (Social Agent Group Evolution),an evaluation framework that compares two compute-matched conditions: SocialEvo, where agents from five distinct model families co-evolve with access to all peers' histories; and SelfEvo, where each agent receives the same number of task attempts but sees only its own past, which is conventional in self-improving agent studies. We instantiate SAGE in three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play, evaluated across multiple evolutionary rounds. We find that group history is not a universal amplifier: the strongest agent does not exceed its self-evolution ceiling. However, agents that plateau under self-improvement can achieve significant breakthroughs when peer experience is available. In competitive settings, counterfactual controls reveal that agents improve generally rather than developing opponent-specific strategies. Across different forms of shared history, filtered peer traces and reflective summaries often outperform raw logs, indicating that social gains depend on abstraction rather than exposure volume. These findings reveal that peer-history gains are agent-specific, arena-dependent, and contingent on the capacity to abstract transferable knowledge from public traces.
DUEL: Adversarial Self-Play for Multimodal Reasoning
May 24, 2026Reinforcement learning (RL) has emerged as an effective paradigm for improving the reasoning capability of vision-language models (VLMs). However, RL-based optimization typically depends on costly high-quality annotations that are difficult to scale. Existing unsupervised alternatives may drift toward biased solutions due to weak visual grounding and the lack of reliable verification signals. We propose a self-evolving post-training framework, DUEL, where supervision emerges from adversarial interactions between two policies initialized from the same pretrained VLM. A Challenger generates an image-grounded true claim together with a minimally perturbed hard-negative counterpart, while a Solver verifies both claims against the image, encouraging fine-grained visual discrimination under near-neighbor semantics. To stabilize optimization, we introduce a length-normalized log-likelihood reward that preserves informative optimization signals beyond binary outcome supervision and improves learning stability under sparse feedback. Experiments show that DUEL consistently improves visual reasoning and robust discrimination without additional human annotations, external reward models, or image editing tools.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
AMemGym: Interactive Memory Benchmarking for Assistants in Long-Horizon Conversations
Mar 02, 2026Long-horizon interactions between users and LLM-based assistants necessitate effective memory management, yet current approaches face challenges in training and evaluation of memory. Existing memory benchmarks rely on static, off-policy data as context, limiting evaluation reliability and scalability. To address these gaps, we introduce AMemGym, an interactive environment enabling on-policy evaluation and optimization for memory-driven personalization. AMemGym employs structured data sampling to predefine user profiles, state-dependent questions, and state evolution trajectories, enabling cost-effective generation of high-quality, evaluation-aligned interactions. LLM-simulated users expose latent states through role-play while maintaining structured state consistency. Comprehensive metrics based on structured data guide both assessment and optimization of assistants. Extensive experiments reveal performance gaps in existing memory systems (e.g., RAG, long-context LLMs, and agentic memory) and corresponding reasons. AMemGym not only enables effective selection among competing approaches but also can potentially drive the self-evolution of memory management strategies. By bridging structured state evolution with free-form interactions, our framework provides a scalable, diagnostically rich environment for advancing memory capabilities in conversational agents.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Beyond Instrumental and Substitutive Paradigms: Introducing Machine Culture as an Emergent Phenomenon in Large Language Models
Jan 23, 2026Recent scholarship typically characterizes Large Language Models (LLMs) through either an \textit{Instrumental Paradigm} (viewing models as reflections of their developers' culture) or a \textit{Substitutive Paradigm} (viewing models as bilingual proxies that switch cultural frames based on language). This study challenges these anthropomorphic frameworks by proposing \textbf{Machine Culture} as an emergent, distinct phenomenon. We employed a 2 (Model Origin: US vs. China) $\times$ 2 (Prompt Language: English vs. Chinese) factorial design across eight multimodal tasks, uniquely incorporating image generation and interpretation to extend analysis beyond textual boundaries. Results revealed inconsistencies with both dominant paradigms: Model origin did not predict cultural alignment, with US models frequently exhibiting ``holistic'' traits typically associated with East Asian data. Similarly, prompt language did not trigger stable cultural frame-switching; instead, we observed \textbf{Cultural Reversal}, where English prompts paradoxically elicited higher contextual attention than Chinese prompts. Crucially, we identified a novel phenomenon termed \textbf{Service Persona Camouflage}: Reinforcement Learning from Human Feedback (RLHF) collapsed cultural variance in affective tasks into a hyper-positive, zero-variance ``helpful assistant'' persona. We conclude that LLMs do not simulate human culture but exhibit an emergent Machine Culture -- a probabilistic phenomenon shaped by \textit{superposition} in high-dimensional space and \textit{mode collapse} from safety alignment.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025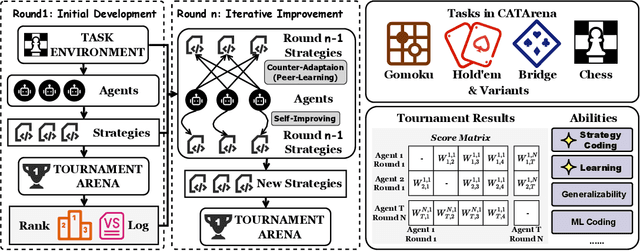
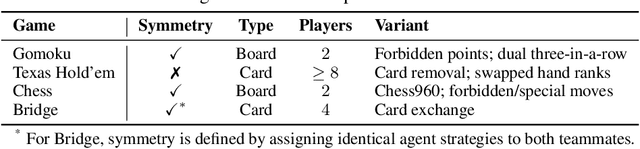
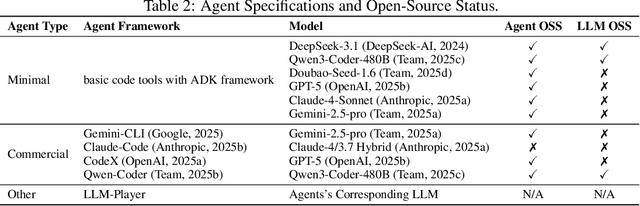
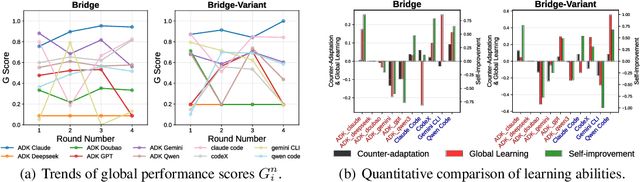
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
Instance-level Randomization: Toward More Stable LLM Evaluations
Sep 16, 2025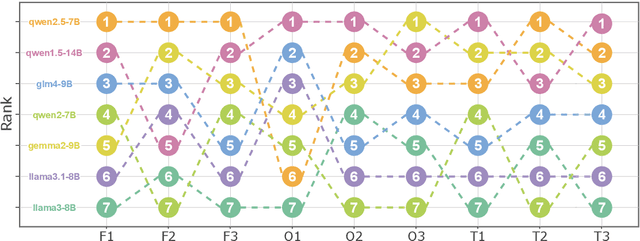

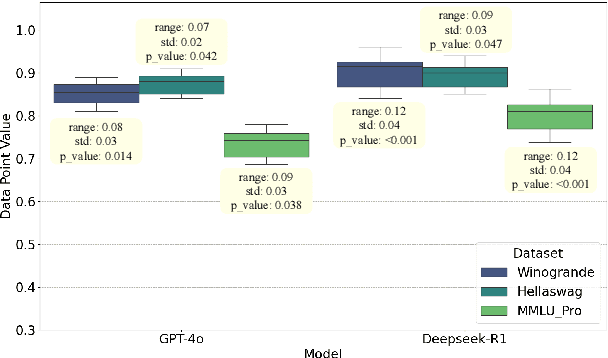
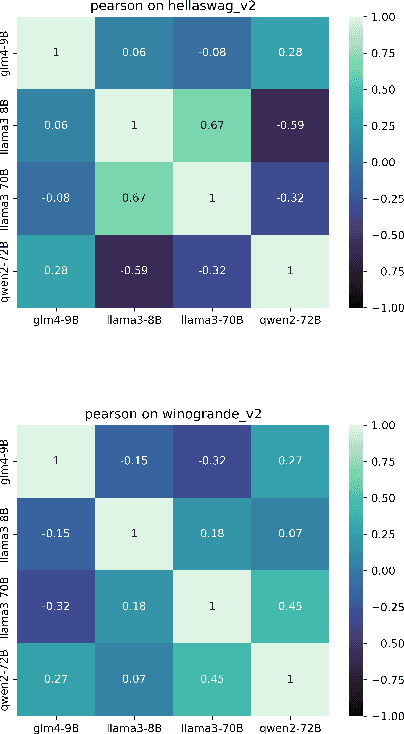
Evaluations of large language models (LLMs) suffer from instability, where small changes of random factors such as few-shot examples can lead to drastic fluctuations of scores and even model rankings. Moreover, different LLMs can have different preferences for a certain setting of random factors. As a result, using a fixed setting of random factors, which is often adopted as the paradigm of current evaluations, can lead to potential unfair comparisons between LLMs. To mitigate the volatility of evaluations, we first theoretically analyze the sources of variance induced by changes in random factors. Targeting these specific sources, we then propose the instance-level randomization (ILR) method to reduce variance and enhance fairness in model comparisons. Instead of using a fixed setting across the whole benchmark in a single experiment, we randomize all factors that affect evaluation scores for every single instance, run multiple experiments and report the averaged score. Theoretical analyses and empirical results demonstrate that ILR can reduce the variance and unfair comparisons caused by random factors, as well as achieve similar robustness level with less than half computational cost compared with previous methods.