 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIP-VLM: Group-Relative Importance Pruning for Efficient Vision-Language Models
May 13, 2026In Vision-Language Models (VLMs), processing a massive number of visual tokens incurs prohibitive computational overhead. While recent training-aware pruning methods attempt to selectively discard redundant tokens, they largely rely on continuous-gradient relaxations. However, visual token pruning is inherently a discrete, non-convex combinatorial problem; consequently, these continuous approximations frequently trap the optimization in sub-optimal local minima, especially under aggressive compression budgets. To overcome this fundamental bottleneck, we propose GRIP-VLM, a Group-Relative Importance Pruning framework driven by Reinforcement Learning. Rather than relying on smooth-gradient assumptions, GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space. Integrated with a budget-aware scorer, our lightweight agent dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining. Extensive experiments across diverse multimodal benchmarks demonstrate that GRIP-VLM consistently outperforms heuristic and supervised-learning baselines, achieving a superior Pareto frontier and delivering up to a 15\% inference speedup at equal accuracy.
EmbodiSkill: Skill-Aware Reflection for Self-Evolving Embodied Agents
May 11, 2026Embodied agents can benefit from skills that guide object search, action execution, and state changes across diverse environments. Since embodied environments vary across layouts, object states, and other execution factors, these skills must self-evolve from trajectories generated during task execution. However, existing skill self-evolution methods are mainly developed in digital environments and often convert trajectories into coarse skill updates. Directly applying this paradigm to embodied settings is problematic, because a failed task execution may reflect not only incorrect skill content, but also an execution lapse in which the agent fails to follow valid guidance. We propose EmbodiSkill, a training-free framework for embodied skill self-evolution through skill-aware reflection and targeted revision. EmbodiSkill interprets each trajectory with respect to the current skill, uses skill-changing evidence to update the skill body, and uses execution-lapse evidence to preserve and emphasize valid guidance. Experiments on ALFWorld and EmbodiedBench show that EmbodiSkill consistently improves embodied task success. On ALFWorld, EmbodiSkill enables a frozen Qwen3.5-27B executor to reach 93.28% task success, outperforming GPT-5.2 used as a direct agent without skills by 31.58%. These results show that skill-aware self-evolution helps embodied agents accumulate reusable procedural knowledge from their own trajectories.
Em-Garde: A Propose-Match Framework for Proactive Streaming Video Understanding
Mar 19, 2026Recent advances in Streaming Video Understanding has enabled a new interaction paradigm where models respond proactively to user queries. Current proactive VideoLLMs rely on per-frame triggering decision making, which suffers from an efficiency-accuracy dilemma. We propose Em-Garde, a novel framework that decouples semantic understanding from streaming perception. At query time, the Instruction-Guided Proposal Parser transforms user queries into structured, perceptually grounded visual proposals; during streaming, a Lightweight Proposal Matching Module performs efficient embedding-based matching to trigger responses. Experiments on StreamingBench and OVO-Bench demonstrate consistent improvements over prior models in proactive response accuracy and efficiency, validating an effective solution for proactive video understanding under strict computational constraints.
PA-LVIO: Real-Time LiDAR-Visual-Inertial Odometry and Mapping with Pose-Only Bundle Adjustment
Mar 17, 2026Real-time LiDAR-visual-inertial odometry and mapping is crucial for navigation and planning tasks in intelligent transportation systems. This study presents a pose-only bundle adjustment (PA) LiDAR-visual-inertial odometry (LVIO), named PA-LVIO, to meet the urgent need for real-time navigation and mapping. The proposed PA framework for LiDAR and visual measurements is highly accurate and efficient, and it can derive reliable frame-to-frame constraints within multiple frames. A marginalization-free and frame-to-map (F2M) LiDAR measurement model is integrated into the state estimator to eliminate odometry drifts. Meanwhile, an IMU-centric online spatial-temporal calibration is employed to obtain a pixel-wise LiDAR-camera alignment. With accurate estimated odometry and extrinsics, a high-quality and RGB-rendered point-cloud map can be built. Comprehensive experiments are conducted on both public and private datasets collected by wheeled robot, unmanned aerial vehicle (UAV), and handheld devices with 28 sequences and more than 50 km trajectories. Sufficient results demonstrate that the proposed PA-LVIO yields superior or comparable performance to state-of-the-art LVIO methods, in terms of the odometry accuracy and mapping quality. Besides, PA-LVIO can run in real-time on both the desktop PC and the onboard ARM computer.
OxyGen: Unified KV Cache Management for Vision-Language-Action Models under Multi-Task Parallelism
Mar 15, 2026Embodied AI agents increasingly require parallel execution of multiple tasks, such as manipulation, conversation, and memory construction, from shared observations under distinct time constraints. Recent Mixture-of-Transformers (MoT) Vision-Language-Action Models (VLAs) architecturally support such heterogeneous outputs, yet existing inference systems fail to achieve efficient multi-task parallelism for on-device deployment due to redundant computation and resource contention. We identify isolated KV cache management as the root cause. To address this, we propose unified KV cache management, an inference paradigm that treats KV cache as a first-class shared resource across tasks and over time. This abstraction enables two key optimizations: cross-task KV sharing eliminates redundant prefill of shared observations, while cross-frame continuous batching decouples variable-length language decoding from fixed-rate action generation across control cycles. We implement this paradigm for $π_{0.5}$, the most popular MoT VLA, and evaluate under representative robotic configurations. OxyGen achieves up to 3.7$\times$ speedup over isolated execution, delivering over 200 tokens/s language throughput and 70 Hz action frequency simultaneously without action quality degradation.
Enhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025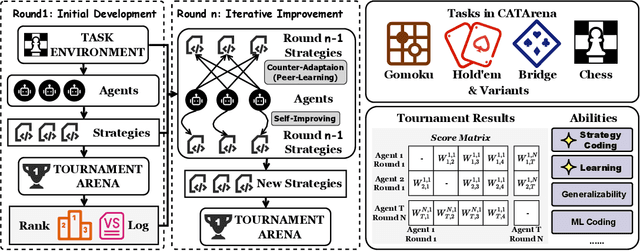
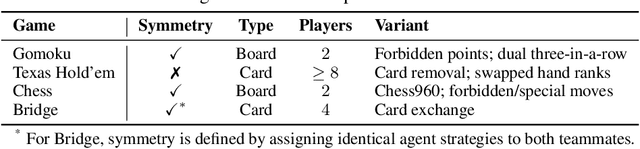
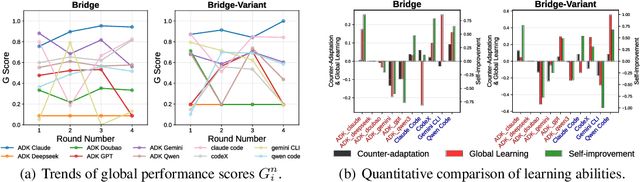
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
TopInG: Topologically Interpretable Graph Learning via Persistent Rationale Filtration
Oct 06, 2025Graph Neural Networks (GNNs) have shown remarkable success across various scientific fields, yet their adoption in critical decision-making is often hindered by a lack of interpretability. Recently, intrinsically interpretable GNNs have been studied to provide insights into model predictions by identifying rationale substructures in graphs. However, existing methods face challenges when the underlying rationale subgraphs are complex and varied. In this work, we propose TopInG: Topologically Interpretable Graph Learning, a novel topological framework that leverages persistent homology to identify persistent rationale subgraphs. TopInG employs a rationale filtration learning approach to model an autoregressive generation process of rationale subgraphs, and introduces a self-adjusted topological constraint, termed topological discrepancy, to enforce a persistent topological distinction between rationale subgraphs and irrelevant counterparts. We provide theoretical guarantees that our loss function is uniquely optimized by the ground truth under specific conditions. Extensive experiments demonstrate TopInG's effectiveness in tackling key challenges, such as handling variform rationale subgraphs, balancing predictive performance with interpretability, and mitigating spurious correlations. Results show that our approach improves upon state-of-the-art methods on both predictive accuracy and interpretation quality.
StreamMind: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition
Mar 08, 2025



With the rise of real-world human-AI interaction applications, such as AI assistants, the need for Streaming Video Dialogue is critical. To address this need, we introduce \sys, a video LLM framework that achieves ultra-FPS streaming video processing (100 fps on a single A100) and enables proactive, always-on responses in real time, without explicit user intervention. To solve the key challenge of the contradiction between linear video streaming speed and quadratic transformer computation cost, we propose a novel perception-cognition interleaving paradigm named ''event-gated LLM invocation'', in contrast to the existing per-time-step LLM invocation. By introducing a Cognition Gate network between the video encoder and the LLM, LLM is only invoked when relevant events occur. To realize the event feature extraction with constant cost, we propose Event-Preserving Feature Extractor (EPFE) based on state-space method, generating a single perception token for spatiotemporal features. These techniques enable the video LLM with full-FPS perception and real-time cognition response. Experiments on Ego4D and SoccerNet streaming tasks, as well as standard offline benchmarks, demonstrate state-of-the-art performance in both model capability and real-time efficiency, paving the way for ultra-high-FPS applications, such as Game AI Copilot and interactive media.
Q&C: When Quantization Meets Cache in Efficient Image Generation
Mar 04, 2025



Quantization and cache mechanisms are typically applied individually for efficient Diffusion Transformers (DiTs), each demonstrating notable potential for acceleration. However, the promoting effect of combining the two mechanisms on efficient generation remains under-explored. Through empirical investigation, we find that the combination of quantization and cache mechanisms for DiT is not straightforward, and two key challenges lead to severe catastrophic performance degradation: (i) the sample efficacy of calibration datasets in post-training quantization (PTQ) is significantly eliminated by cache operation; (ii) the combination of the above mechanisms introduces more severe exposure bias within sampling distribution, resulting in amplified error accumulation in the image generation process. In this work, we take advantage of these two acceleration mechanisms and propose a hybrid acceleration method by tackling the above challenges, aiming to further improve the efficiency of DiTs while maintaining excellent generation capability. Concretely, a temporal-aware parallel clustering (TAP) is designed to dynamically improve the sample selection efficacy for the calibration within PTQ for different diffusion steps. A variance compensation (VC) strategy is derived to correct the sampling distribution. It mitigates exposure bias through an adaptive correction factor generation. Extensive experiments have shown that our method has accelerated DiTs by 12.7x while preserving competitive generation capability. The code will be available at https://github.com/xinding-sys/Quant-Cache.