 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeScope: Large Multimodal Expert Model for Transparent AI-Generated Image Forensics
Mar 31, 2025



The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Mar 18, 2025
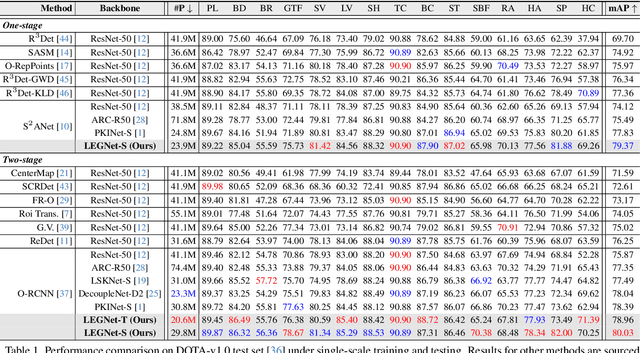
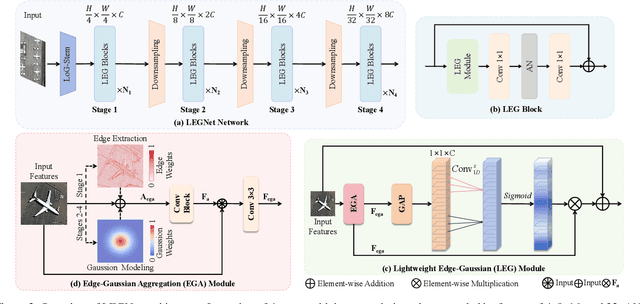
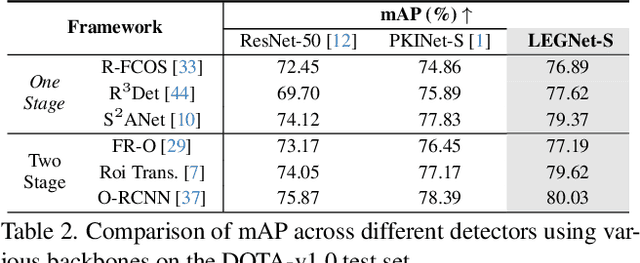
Remote sensing object detection (RSOD) faces formidable challenges in complex visual environments. Aerial and satellite images inherently suffer from limitations such as low spatial resolution, sensor noise, blurred objects, low-light degradation, and partial occlusions. These degradation factors collectively compromise the feature discriminability in detection models, resulting in three key issues: (1) reduced contrast that hampers foreground-background separation, (2) structural discontinuities in edge representations, and (3) ambiguous feature responses caused by variations in illumination. These collectively weaken model robustness and deployment feasibility. To address these challenges, we propose LEGNet, a lightweight network that incorporates a novel edge-Gaussian aggregation (EGA) module specifically designed for low-quality remote sensing images. Our key innovation lies in the synergistic integration of Scharr operator-based edge priors with uncertainty-aware Gaussian modeling: (a) The orientation-aware Scharr filters preserve high-frequency edge details with rotational invariance; (b) The uncertainty-aware Gaussian layers probabilistically refine low-confidence features through variance estimation. This design enables precision enhancement while maintaining architectural simplicity. Comprehensive evaluations across four RSOD benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0) and a UAV-view dataset (VisDrone2019) demonstrate significant improvements. LEGNet achieves state-of-the-art performance across five benchmark datasets while ensuring computational efficiency, making it well-suited for deployment on resource-constrained edge devices in real-world remote sensing applications. The code is available at https://github.com/lwCVer/LEGNet.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
ChatReID: Open-ended Interactive Person Retrieval via Hierarchical Progressive Tuning for Vision Language Models
Feb 27, 2025



Person re-identification (Re-ID) is a critical task in human-centric intelligent systems, enabling consistent identification of individuals across different camera views using multi-modal query information. Recent studies have successfully integrated LVLMs with person Re-ID, yielding promising results. However, existing LVLM-based methods face several limitations. They rely on extracting textual embeddings from fixed templates, which are used either as intermediate features for image representation or for prompt tuning in domain-specific tasks. Furthermore, they are unable to adopt the VQA inference format, significantly restricting their broader applicability. In this paper, we propose a novel, versatile, one-for-all person Re-ID framework, ChatReID. Our approach introduces a Hierarchical Progressive Tuning (HPT) strategy, which ensures fine-grained identity-level retrieval by progressively refining the model's ability to distinguish pedestrian identities. Extensive experiments demonstrate that our approach outperforms SOTA methods across ten benchmarks in four different Re-ID settings, offering enhanced flexibility and user-friendliness. ChatReID provides a scalable, practical solution for real-world person Re-ID applications, enabling effective multi-modal interaction and fine-grained identity discrimination.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025



Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025



Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
Topic-FlipRAG: Topic-Orientated Adversarial Opinion Manipulation Attacks to Retrieval-Augmented Generation Models
Feb 03, 2025Retrieval-Augmented Generation (RAG) systems based on Large Language Models (LLMs) have become essential for tasks such as question answering and content generation. However, their increasing impact on public opinion and information dissemination has made them a critical focus for security research due to inherent vulnerabilities. Previous studies have predominantly addressed attacks targeting factual or single-query manipulations. In this paper, we address a more practical scenario: topic-oriented adversarial opinion manipulation attacks on RAG models, where LLMs are required to reason and synthesize multiple perspectives, rendering them particularly susceptible to systematic knowledge poisoning. Specifically, we propose Topic-FlipRAG, a two-stage manipulation attack pipeline that strategically crafts adversarial perturbations to influence opinions across related queries. This approach combines traditional adversarial ranking attack techniques and leverages the extensive internal relevant knowledge and reasoning capabilities of LLMs to execute semantic-level perturbations. Experiments show that the proposed attacks effectively shift the opinion of the model's outputs on specific topics, significantly impacting user information perception. Current mitigation methods cannot effectively defend against such attacks, highlighting the necessity for enhanced safeguards for RAG systems, and offering crucial insights for LLM security research.
LWGANet: A Lightweight Group Attention Backbone for Remote Sensing Visual Tasks
Jan 17, 2025Remote sensing (RS) visual tasks have gained significant academic and practical importance. However, they encounter numerous challenges that hinder effective feature extraction, including the detection and recognition of multiple objects exhibiting substantial variations in scale within a single image. While prior dual-branch or multi-branch architectural strategies have been effective in managing these object variances, they have concurrently resulted in considerable increases in computational demands and parameter counts. Consequently, these architectures are rendered less viable for deployment on resource-constrained devices. Contemporary lightweight backbone networks, designed primarily for natural images, frequently encounter difficulties in effectively extracting features from multi-scale objects, which compromises their efficacy in RS visual tasks. This article introduces LWGANet, a specialized lightweight backbone network tailored for RS visual tasks, incorporating a novel lightweight group attention (LWGA) module designed to address these specific challenges. LWGA module, tailored for RS imagery, adeptly harnesses redundant features to extract a wide range of spatial information, from local to global scales, without introducing additional complexity or computational overhead. This facilitates precise feature extraction across multiple scales within an efficient framework.LWGANet was rigorously evaluated across twelve datasets, which span four crucial RS visual tasks: scene classification, oriented object detection, semantic segmentation, and change detection. The results confirm LWGANet's widespread applicability and its ability to maintain an optimal balance between high performance and low complexity, achieving SOTA results across diverse datasets. LWGANet emerged as a novel solution for resource-limited scenarios requiring robust RS image processing capabilities.
Boundary-enhanced time series data imputation with long-term dependency diffusion models
Jan 11, 2025



Data imputation is crucial for addressing challenges posed by missing values in multivariate time series data across various fields, such as healthcare, traffic, and economics, and has garnered significant attention. Among various methods, diffusion model-based approaches show notable performance improvements. However, existing methods often cause disharmonious boundaries between missing and known regions and overlook long-range dependencies in missing data estimation, leading to suboptimal results. To address these issues, we propose a Diffusion-based time Series Data Imputation (DSDI) framework. We develop a weight-reducing injection strategy that incorporates the predicted values of missing points with reducing weights into the reverse diffusion process to mitigate boundary inconsistencies. Further, we introduce a multi-scale S4-based U-Net, which combines hierarchical information from different levels via multi-resolution integration to capture long-term dependencies. Experimental results demonstrate that our model outperforms existing imputation methods.