 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHurwitz Quaternion Multiplicative Quantization for KV Cache Compression
May 26, 2026We propose \textbf{Hurwitz Quaternion Multiplicative Quantization (HQMQ)}, a \textbf{calibration-free} method for KV cache compression of large language models. HQMQ treats each 4-element chunk of K or V as a quaternion and quantizes its unit direction to the \emph{product} $q_p \cdot q_s$, where $q_p$ ranges over the 24-element Hurwitz group $2T$ (the 24 vertices of the 24-cell on $S^3$, pairwise angle $60^\circ$) and $q_s$ ranges over a per-(layer, head) secondary codebook of $S$ \emph{random} unit quaternions. The multiplicative composition yields $24S$ effective codewords at $S$ stored parameters; random initialization suffices because left-multiplication is an $S^3$ isometry, so seeded codebooks vary in end-task ppl by $<1.5\%$. A per-batch median-multiplier outlier extraction step ($C{=}3$, no calibration) handles modern outlier-heavy architectures. We evaluate on five modern open models: Mistral-7B (dense MHA), Llama-3-8B and Qwen2.5-7B and Qwen3-8B (dense GQA), and gpt-oss-20b (sparse MoE). On Mistral-7B and Qwen3-8B, HQMQ matches fp16 within $0.02$--$0.03$ ppl points at $\sim$5 bits. On Qwen2.5-7B and Qwen3-8B, where naive int4 collapses to $10^4{+}$ ppl, HQMQ + Med3$\times$ recovers fp16 quality within $0.02$--$0.10$ ppl points at $\sim$5 bits. HQMQ Pareto-dominates naive int by $3$--$1900\times$ at matched bits across all five models, and downstream zero-shot accuracy matches fp16 at $3.79$ bits on Mistral. Against the strongest calibrated KV-quantization baseline, HQMQ at $3.79$ bits matches KIVI-4 ($\sim 4.5$ bits) within ${\sim}1$ pt on CoQA, $0.6$ pts on TruthfulQA, and $2.3$ pts on GSM8K, at $16\%$ fewer bits and without a calibration pass. At the storage level, HQMQ delivers up to $5.05\times$ KV compression, shrinking a Llama-3-70B 128k-context cache from 43 GB to 8.5 GB.
CliffSearch: Structured Agentic Co-Evolution over Theory and Code for Scientific Algorithm Discovery
Apr 01, 2026Scientific algorithm discovery is iterative: hypotheses are proposed, implemented, stress-tested, and revised. Current LLM-guided search systems accelerate proposal generation, but often under-represent scientific structure by optimizing code-only artifacts with weak correctness/originality gating. We present CliffSearch, an agentic evolutionary framework in which the core evolution operators (pair selection, crossover, mutation, and review) are implemented as LLM agents, and the loop is designed around three principles: (1) each node is a structured scientific artifact, instantiated in either theory+code or code_only mode, (2) reviewer judgments of correctness and originality are first-class selection gates alongside optimization of the benchmark metric of interest, and (3) mutation is split into exploration and correction pathways with distinct objectives. Exploration mutation imports ideas from adjacent scientific domains to increase novelty, while correction mutation performs targeted evidence-guided repair using reviewer signals over theory, code, benchmark results, and runtime errors. We illustrate the framework on three benchmark-grounded studies: transformer hyper-connection evolution, optimizer discovery on a fixed nanoGPT stack, and a smaller native-optimizer ablation. Across these settings, the same loop supports explicit metric direction, reproducible persistence, and reviewer-gated comparison of discoveries under controlled search conditions. The result is a discovery workflow that prioritizes scientific interpretability and correctness while optimizing task metrics under controlled novelty constraints, rather than maximizing candidate throughput alone. Full run artifacts, interactive visualizations, and exported best nodes for the reported studies are available at https://cliffsearch.ai .
LLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
A System for Accurate Tracking and Video Recordings of Rodent Eye Movements using Convolutional Neural Networks for Biomedical Image Segmentation
Jun 09, 2025Research in neuroscience and vision science relies heavily on careful measurements of animal subject's gaze direction. Rodents are the most widely studied animal subjects for such research because of their economic advantage and hardiness. Recently, video based eye trackers that use image processing techniques have become a popular option for gaze tracking because they are easy to use and are completely noninvasive. Although significant progress has been made in improving the accuracy and robustness of eye tracking algorithms, unfortunately, almost all of the techniques have focused on human eyes, which does not account for the unique characteristics of the rodent eye images, e.g., variability in eye parameters, abundance of surrounding hair, and their small size. To overcome these unique challenges, this work presents a flexible, robust, and highly accurate model for pupil and corneal reflection identification in rodent gaze determination that can be incrementally trained to account for variability in eye parameters encountered in the field. To the best of our knowledge, this is the first paper that demonstrates a highly accurate and practical biomedical image segmentation based convolutional neural network architecture for pupil and corneal reflection identification in eye images. This new method, in conjunction with our automated infrared videobased eye recording system, offers the state of the art technology in eye tracking for neuroscience and vision science research for rodents.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025



Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
Granite Embedding Models
Feb 27, 2025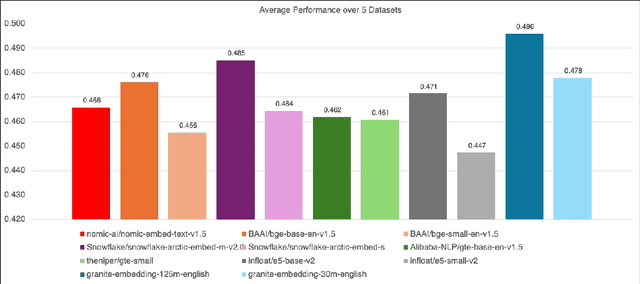
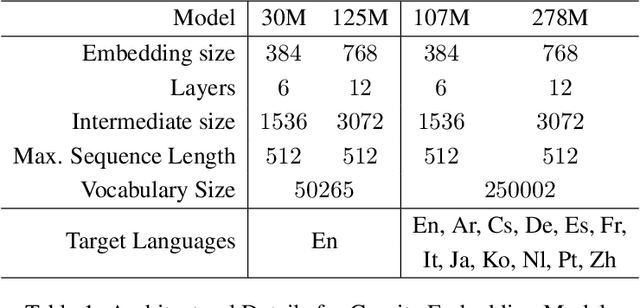
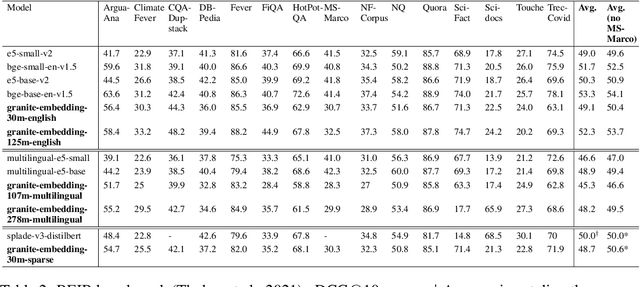

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024



AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.