 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Region Policy Distillation
May 25, 2026Reinforcement learning for large language models faces a fundamental trade-off between sample efficiency and asymptotic performance: strictly on-policy methods discard trajectories after a single update, while off-policy reuse introduces distribution mismatch that existing trust-region techniques mitigate primarily by enforcing conservative optimization, often leaving rich training signals underutilized. To investigate this, we perform extensive off-policy updates on fixed data. Our experiments reveal that aggressive multi-step optimization brings rapid initial gains, but excessive updates cause trajectory probabilities to deviate and entropy to collapse, with performance plateauing early. Tightening KL constraints merely lowers the ceiling without resolving the degradation. This motivates Extreme Region Policy Distillation (ERPD), a two-stage framework that decouples sample efficiency from KL efficiency. The first stage performs weakly constrained off-policy optimization on fixed data to maximally extract training signals. The resulting policy provides token-level supervision. In the second stage, we distill these signals into the base policy under trust-region constraints, filtering harmful drift while preserving useful signals. The distilled policy achieves comparable or better performance with substantially smaller KL divergence, indicating that much of the first-stage divergence was spent on unnecessary drift rather than genuine improvement. Crucially, ERPD accommodates both strong and weak teachers: when aggressive optimization yields no stronger policy, even degenerate teachers provide effective supervision via alternative signal construction strategies. We validate ERPD on mathematical reasoning, showing gains for strong base models where on-policy training plateaus, and reliable improvements with weak teachers.
CoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
Feb 27, 2026Mobile Agents can autonomously execute user instructions, which requires hybrid-capabilities reasoning, including screen summary, subtask planning, action decision and action function. However, existing agents struggle to achieve both decoupled enhancement and balanced integration of these capabilities. To address these challenges, we propose Channel-of-Mobile-Experts (CoME), a novel agent architecture consisting of four distinct experts, each aligned with a specific reasoning stage, CoME activates the corresponding expert to generate output tokens in each reasoning stage via output-oriented activation. To empower CoME with hybrid-capabilities reasoning, we introduce a progressive training strategy: Expert-FT enables decoupling and enhancement of different experts' capability; Router-FT aligns expert activation with the different reasoning stage; CoT-FT facilitates seamless collaboration and balanced optimization across multiple capabilities. To mitigate error propagation in hybrid-capabilities reasoning, we propose InfoGain-Driven DPO (Info-DPO), which uses information gain to evaluate the contribution of each intermediate step, thereby guiding CoME toward more informative reasoning. Comprehensive experiments show that CoME outperforms dense mobile agents and MoE methods on both AITZ and AMEX datasets.
Efficient Process Reward Model Training via Active Learning
Apr 14, 2025

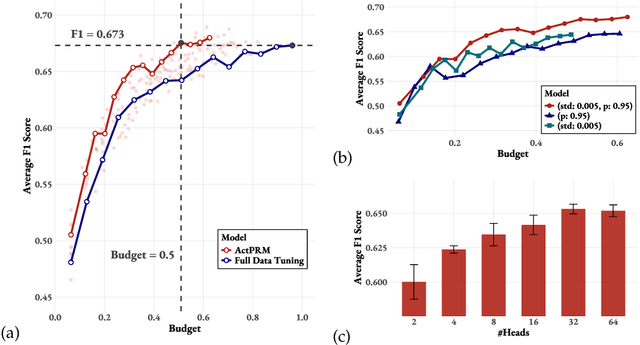

Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.
Understanding R1-Zero-Like Training: A Critical Perspective
Mar 26, 2025



DeepSeek-R1-Zero has shown that reinforcement learning (RL) at scale can directly enhance the reasoning capabilities of LLMs without supervised fine-tuning. In this work, we critically examine R1-Zero-like training by analyzing its two core components: base models and RL. We investigate a wide range of base models, including DeepSeek-V3-Base, to understand how pretraining characteristics influence RL performance. Our analysis reveals that DeepSeek-V3-Base already exhibit ''Aha moment'', while Qwen2.5 base models demonstrate strong reasoning capabilities even without prompt templates, suggesting potential pretraining biases. Additionally, we identify an optimization bias in Group Relative Policy Optimization (GRPO), which artificially increases response length (especially for incorrect outputs) during training. To address this, we introduce Dr. GRPO, an unbiased optimization method that improves token efficiency while maintaining reasoning performance. Leveraging these insights, we present a minimalist R1-Zero recipe that achieves 43.3% accuracy on AIME 2024 with a 7B base model, establishing a new state-of-the-art. Our code is available at https://github.com/sail-sg/understand-r1-zero.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025



Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
On Learning Informative Trajectory Embeddings for Imitation, Classification and Regression
Jan 16, 2025



In real-world sequential decision making tasks like autonomous driving, robotics, and healthcare, learning from observed state-action trajectories is critical for tasks like imitation, classification, and clustering. For example, self-driving cars must replicate human driving behaviors, while robots and healthcare systems benefit from modeling decision sequences, whether or not they come from expert data. Existing trajectory encoding methods often focus on specific tasks or rely on reward signals, limiting their ability to generalize across domains and tasks. Inspired by the success of embedding models like CLIP and BERT in static domains, we propose a novel method for embedding state-action trajectories into a latent space that captures the skills and competencies in the dynamic underlying decision-making processes. This method operates without the need for reward labels, enabling better generalization across diverse domains and tasks. Our contributions are threefold: (1) We introduce a trajectory embedding approach that captures multiple abilities from state-action data. (2) The learned embeddings exhibit strong representational power across downstream tasks, including imitation, classification, clustering, and regression. (3) The embeddings demonstrate unique properties, such as controlling agent behaviors in IQ-Learn and an additive structure in the latent space. Experimental results confirm that our method outperforms traditional approaches, offering more flexible and powerful trajectory representations for various applications. Our code is available at https://github.com/Erasmo1015/vte.
Sample-Efficient Alignment for LLMs
Nov 03, 2024



We study methods for efficiently aligning large language models (LLMs) with human preferences given budgeted online feedback. We first formulate the LLM alignment problem in the frame of contextual dueling bandits. This formulation, subsuming recent paradigms such as online RLHF and online DPO, inherently quests for sample-efficient algorithms that incorporate online active exploration. Leveraging insights from bandit theory, we introduce a unified algorithm based on Thompson sampling and highlight its applications in two distinct LLM alignment scenarios. The practical agent that efficiently implements this algorithm, named SEA (Sample-Efficient Alignment), is empirically validated through extensive experiments across three model scales (1B, 2.8B, 6.9B) and three preference learning algorithms (DPO, IPO, SLiC). The results demonstrate that SEA achieves highly sample-efficient alignment with oracle's preferences, outperforming recent active exploration methods for LLMs. Additionally, we release the implementation of SEA together with an efficient codebase designed for online alignment of LLMs, aiming to accelerate future research in this field.
Towards Neural Network based Cognitive Models of Dynamic Decision-Making by Humans
Jul 24, 2024



Modelling human cognitive processes in dynamic decision-making tasks has been an endeavor in AI for a long time. Some initial works have attempted to utilize neural networks (and large language models) but often assume one common model for all humans and aim to emulate human behavior in aggregate. However, behavior of each human is distinct, heterogeneous and relies on specific past experiences in specific tasks. To that end, we build on a well known model of cognition, namely Instance Based Learning (IBL), that posits that decisions are made based on similar situations encountered in the past. We propose two new attention based neural network models to model human decision-making in dynamic settings. We experiment with two distinct datasets gathered from human subject experiment data, one focusing on detection of phishing email by humans and another where humans act as attackers in a cybersecurity setting and decide on an attack option. We conduct extensive experiments with our two neural network models, IBL, and GPT3.5, and demonstrate that one of our neural network models achieves the best performance in representing human decision-making. We find an interesting trend that all models predict a human's decision better if that human is better at the task. We also explore explanation of human decisions based on what our model considers important in prediction. Overall, our work yields promising results for further use of neural networks in cognitive modelling of human decision making. Our code is available at https://github.com/shshnkreddy/NCM-HDM.
Unlocking Large Language Model's Planning Capabilities with Maximum Diversity Fine-tuning
Jun 15, 2024



Large language models (LLMs) have demonstrated impressive task-solving capabilities, achieved through either prompting techniques or system designs. However, concerns have arisen regarding their proficiency in planning tasks, as they often struggle to generate valid plans. This paper investigates the impact of fine-tuning on LLMs' planning capabilities. Our findings indicate that LLMs can achieve good performance in planning through substantial (thousands of specific examples) fine-tuning. However, fine-tuning is associated with significant economic and computational costs. To address this challenge, we propose the Maximum Diversity Fine-Tuning (MDFT) strategy to improve the sample efficiency of fine-tuning in the planning domain. Specifically, our algorithm, referred to as MDFT-g, encodes the planning task instances with their graph representations and selects a subset of samples in the vector space that maximizes data diversity. We empirically demonstrate that MDFT-g consistently outperforms existing baselines at various scales across multiple benchmark domains.
Bootstrapping Language Models with DPO Implicit Rewards
Jun 14, 2024



Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.